24 Naive Bayes for SMS spam
- Datasets:
sms_spam.csv - Algorithms:
- Naive Bayes
Dataset: https://github.com/stedy/Machine-Learning-with-R-datasets/blob/master/sms_spam.csv
Instructions: Machine Learning with R. Page 104.
str(sms_raw)
#> 'data.frame': 5574 obs. of 2 variables:
#> $ type: chr "ham" "ham" "spam" "ham" ...
#> $ text: chr "Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat..." "Ok lar... Joking wif u oni..." "Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question("| __truncated__ "U dun say so early hor... U c already then say..." ...24.0.1 convert type to a factor
sms_raw$type <- factor(sms_raw$type)
str(sms_raw$type)
#> Factor w/ 2 levels "ham","spam": 1 1 2 1 1 2 1 1 2 2 ...How many email of type ham or spam:
table(sms_raw$type)
#>
#> ham spam
#> 4827 747Create the corpus:
library(tm)
#> Loading required package: NLP
sms_corpus <- VCorpus(VectorSource(sms_raw$text))
print(sms_corpus)
#> <<VCorpus>>
#> Metadata: corpus specific: 0, document level (indexed): 0
#> Content: documents: 5574Let’s see a couple of documents:
inspect(sms_corpus[1:2])
#> <<VCorpus>>
#> Metadata: corpus specific: 0, document level (indexed): 0
#> Content: documents: 2
#>
#> [[1]]
#> <<PlainTextDocument>>
#> Metadata: 7
#> Content: chars: 111
#>
#> [[2]]
#> <<PlainTextDocument>>
#> Metadata: 7
#> Content: chars: 29
# show some text
as.character(sms_corpus[[1]])
#> [1] "Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat..."
# show three documents
lapply(sms_corpus[1:3], as.character)
#> $`1`
#> [1] "Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat..."
#>
#> $`2`
#> [1] "Ok lar... Joking wif u oni..."
#>
#> $`3`
#> [1] "Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's"24.1 Some conversion
# convert to lowercase
sms_corpus_clean <- tm_map(sms_corpus, content_transformer(tolower))
as.character(sms_corpus[[1]])
#> [1] "Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat..."
# converted to lowercase
as.character(sms_corpus_clean[[1]])
#> [1] "go until jurong point, crazy.. available only in bugis n great world la e buffet... cine there got amore wat..."
# remove numbers
sms_corpus_clean <- tm_map(sms_corpus_clean, removeNumbers)What transformations are available
# what transformations are available
getTransformations()
#> [1] "removeNumbers" "removePunctuation" "removeWords"
#> [4] "stemDocument" "stripWhitespace"
# remove punctuation
sms_corpus_clean <- tm_map(sms_corpus_clean, removePunctuation)Stemming:
library(SnowballC)
wordStem(c("learn", "learned", "learning", "learns"))
#> [1] "learn" "learn" "learn" "learn"
# stemming corpus
sms_corpus_clean <- tm_map(sms_corpus_clean, stemDocument)
# remove white spaces
sms_corpus_clean <- tm_map(sms_corpus_clean, stripWhitespace)Show what we’ve got so far
# show what we've got so far
lapply(sms_corpus[1:3], as.character)
#> $`1`
#> [1] "Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat..."
#>
#> $`2`
#> [1] "Ok lar... Joking wif u oni..."
#>
#> $`3`
#> [1] "Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's"
lapply(sms_corpus_clean[1:3], as.character)
#> $`1`
#> [1] "go jurong point crazi avail bugi n great world la e buffet cine got amor wat"
#>
#> $`2`
#> [1] "ok lar joke wif u oni"
#>
#> $`3`
#> [1] "free entri wkli comp win fa cup final tkts st may text fa receiv entri questionstd txt ratetc appli s"24.2 Convert to Document Term Matrix (dtm
)
sms_dtm <- DocumentTermMatrix(sms_corpus_clean)
sms_dtm
#> <<DocumentTermMatrix (documents: 5574, terms: 6592)>>
#> Non-/sparse entries: 42608/36701200
#> Sparsity : 100%
#> Maximal term length: 40
#> Weighting : term frequency (tf)24.3 split in training and test datasets
sms_dtm_train <- sms_dtm[1:4169, ]
sms_dtm_test <- sms_dtm[4170:5559, ]24.3.1 separate the labels
sms_train_labels <- sms_raw[1:4169, ]$type
sms_test_labels <- sms_raw[4170:5559, ]$type
prop.table(table(sms_train_labels))
#> sms_train_labels
#> ham spam
#> 0.865 0.135
prop.table(table(sms_test_labels))
#> sms_test_labels
#> ham spam
#> 0.87 0.13
# convert dtm to matrix
sms_mat_train <- as.matrix(t(sms_dtm_train))
dtm.rs <- sort(rowSums(sms_mat_train), decreasing=TRUE)
# dataframe with word-frequency
dtm.df <- data.frame(word = names(dtm.rs), freq = as.integer(dtm.rs),
stringsAsFactors = FALSE)24.4 plot wordcloud
library(wordcloud)
#> Loading required package: RColorBrewer
wordcloud(sms_corpus_clean, min.freq = 50, random.order = FALSE)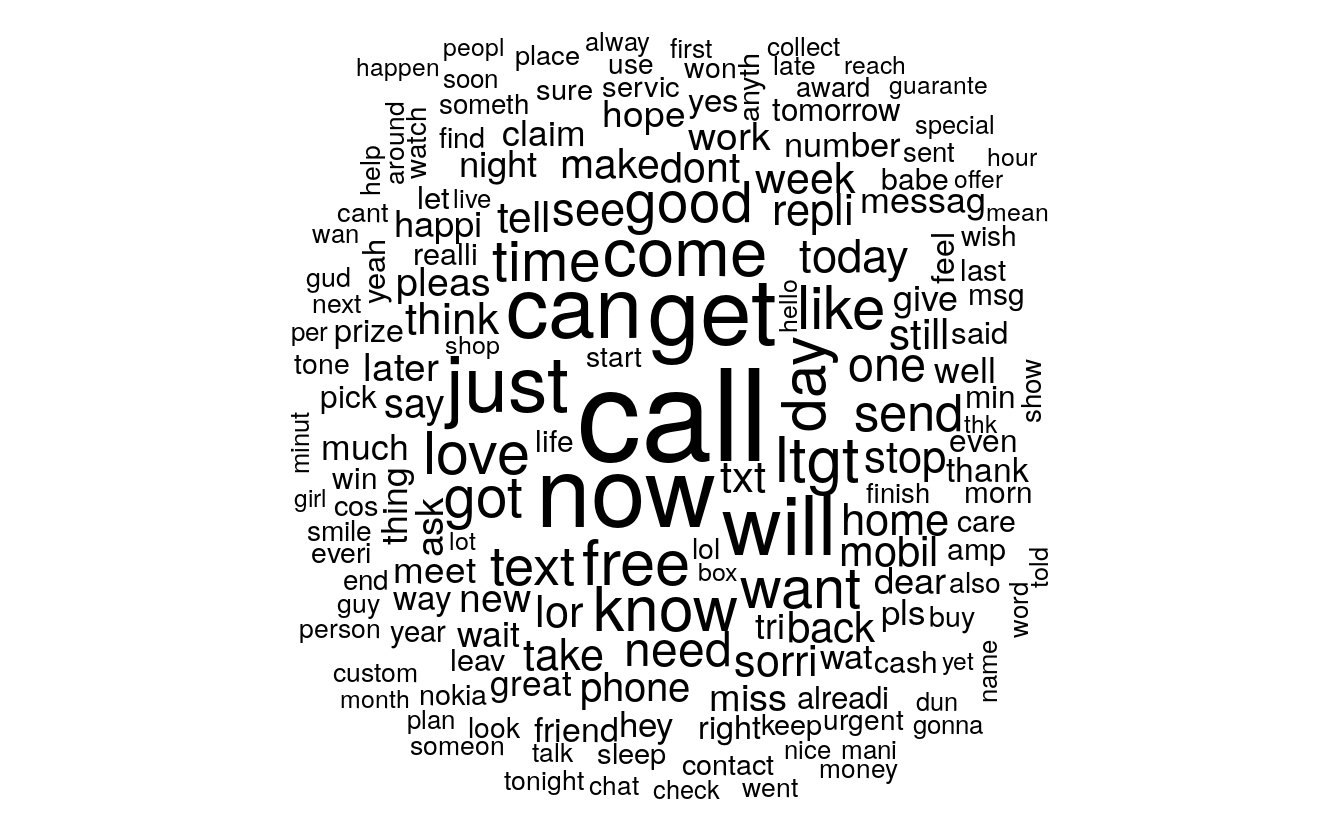
Words related to spam
wordcloud(spam$text, max.words = 40, scale = c(3, 0.5))
#> Warning in tm_map.SimpleCorpus(corpus, tm::removePunctuation): transformation
#> drops documents
#> Warning in tm_map.SimpleCorpus(corpus, function(x) tm::removeWords(x,
#> tm::stopwords())): transformation drops documents
Words related to ham
wordcloud(ham$text, max.words = 40, scale = c(3, 0.5))
#> Warning in tm_map.SimpleCorpus(corpus, tm::removePunctuation): transformation
#> drops documents
#> Warning in tm_map.SimpleCorpus(corpus, function(x) tm::removeWords(x,
#> tm::stopwords())): transformation drops documents
24.5 Limit Frequent words
# words that appear at least in 5 messages
sms_freq_words <- findFreqTerms(sms_dtm_train, 6)
str(sms_freq_words)
#> chr [1:997] "abiola" "abl" "abt" "accept" "access" "account" "across" ...24.5.1 get only frequent words
sms_dtm_freq_train<- sms_dtm_train[ , sms_freq_words]
sms_dtm_freq_test <- sms_dtm_test[ , sms_freq_words]24.5.2 function to change value to Yes/No
convert_counts <- function(x) {
x <- ifelse(x > 0, "Yes", "No")
}
# change from number to Yes/No
# also the result returns a matrix
sms_train <- apply(sms_dtm_freq_train, MARGIN = 2,
convert_counts)
sms_test <- apply(sms_dtm_freq_test, MARGIN = 2,
convert_counts)
# matrix of
# 4169 documents as rows
# 1159 terms as columns
dim(sms_train)
#> [1] 4169 997
length(sms_train_labels)
#> [1] 4169
# this is how the matrix looks
sms_train[1:10, 10:15]
#> Terms
#> Docs add address admir advanc aft afternoon
#> 1 "No" "No" "No" "No" "No" "No"
#> 2 "No" "No" "No" "No" "No" "No"
#> 3 "No" "No" "No" "No" "No" "No"
#> 4 "No" "No" "No" "No" "No" "No"
#> 5 "No" "No" "No" "No" "No" "No"
#> 6 "No" "No" "No" "No" "No" "No"
#> 7 "No" "No" "No" "No" "No" "No"
#> 8 "No" "No" "No" "No" "No" "No"
#> 9 "No" "No" "No" "No" "No" "No"
#> 10 "No" "No" "No" "No" "No" "No"
library(e1071)
sms_classifier <- naiveBayes(sms_train, sms_train_labels)
library(gmodels)
CrossTable(sms_test_pred, sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE,
dnn = c('predicted', 'actual'))
#>
#>
#> Cell Contents
#> |-------------------------|
#> | N |
#> | N / Row Total |
#> | N / Col Total |
#> |-------------------------|
#>
#>
#> Total Observations in Table: 1390
#>
#>
#> | actual
#> predicted | ham | spam | Row Total |
#> -------------|-----------|-----------|-----------|
#> ham | 1202 | 21 | 1223 |
#> | 0.983 | 0.017 | 0.880 |
#> | 0.994 | 0.116 | |
#> -------------|-----------|-----------|-----------|
#> spam | 7 | 160 | 167 |
#> | 0.042 | 0.958 | 0.120 |
#> | 0.006 | 0.884 | |
#> -------------|-----------|-----------|-----------|
#> Column Total | 1209 | 181 | 1390 |
#> | 0.870 | 0.130 | |
#> -------------|-----------|-----------|-----------|
#>
#> Misclassified: 20+9 (frequency = 5) 25+7 (freq=4) 23+7 (freq=3) 25+8 (freq=2) 21+7 (freq=6)
Decreasing the minimum word frequency doesn’t make the model better.
24.6 Improve model performance
sms_classifier2 <- naiveBayes(sms_train, sms_train_labels,
laplace = 1)
CrossTable(sms_test_pred2, sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual'))
#>
#>
#> Cell Contents
#> |-------------------------|
#> | N |
#> | N / Col Total |
#> |-------------------------|
#>
#>
#> Total Observations in Table: 1390
#>
#>
#> | actual
#> predicted | ham | spam | Row Total |
#> -------------|-----------|-----------|-----------|
#> ham | 1203 | 28 | 1231 |
#> | 0.995 | 0.155 | |
#> -------------|-----------|-----------|-----------|
#> spam | 6 | 153 | 159 |
#> | 0.005 | 0.845 | |
#> -------------|-----------|-----------|-----------|
#> Column Total | 1209 | 181 | 1390 |
#> | 0.870 | 0.130 | |
#> -------------|-----------|-----------|-----------|
#>
#> Misclassified: 28+7