46 Deep Learning tips for Classification and Regression
- Datasets:
spiral.csv,grid.csv,covtype.full.csv - Algorithms:
- Deep Learning with
h2o
- Deep Learning with
- Techniques:
- Decision Boundaries
- Hyper-parameter Tuning with Grid Search
- Checkpointing
- Cross-Validation
46.1 Introduction
Source: http://docs.h2o.ai/h2o-tutorials/latest-stable/tutorials/deeplearning/index.html
Repo: https://github.com/h2oai/h2o-tutorials
This tutorial shows how a H2O Deep Learning model can be used to do supervised classification and regression. A great tutorial about Deep Learning is given by Quoc Le here and here. This tutorial covers usage of H2O from R. A python version of this tutorial will be available as well in a separate document. This file is available in plain R, R markdown and regular markdown formats, and the plots are available as PDF files. All documents are available on Github.
If run from plain R, execute R in the directory of this script. If run from RStudio, be sure to setwd() to the location of this script.h2o.init() starts H2O in R’s current working directory. h2o.importFile() looks for files from the perspective of where H2O was started.
More examples and explanations can be found in our H2O Deep Learning booklet and on our H2O Github Repository. The PDF slide deck can be found on Github.
46.2 H2O R Package
Load the H2O R package:
Source: http://docs.h2o.ai/h2o-tutorials/latest-stable/tutorials/deeplearning/index.html
## R installation instructions are at http://h2o.ai/download
library(h2o)
#>
#> ----------------------------------------------------------------------
#>
#> Your next step is to start H2O:
#> > h2o.init()
#>
#> For H2O package documentation, ask for help:
#> > ??h2o
#>
#> After starting H2O, you can use the Web UI at http://localhost:54321
#> For more information visit http://docs.h2o.ai
#>
#> ----------------------------------------------------------------------
#>
#> Attaching package: 'h2o'
#> The following objects are masked from 'package:stats':
#>
#> cor, sd, var
#> The following objects are masked from 'package:base':
#>
#> &&, %*%, %in%, ||, apply, as.factor, as.numeric, colnames,
#> colnames<-, ifelse, is.character, is.factor, is.numeric, log,
#> log10, log1p, log2, round, signif, trunc46.3 Start H2O
Start up a 1-node H2O server on your local machine, and allow it to use all CPU cores and up to 2GB of memory:
h2o.init(nthreads=-1, max_mem_size="2G")
#> Connection successful!
#>
#> R is connected to the H2O cluster:
#> H2O cluster uptime: 38 minutes 44 seconds
#> H2O cluster timezone: Etc/UTC
#> H2O data parsing timezone: UTC
#> H2O cluster version: 3.30.0.1
#> H2O cluster version age: 7 months and 16 days !!!
#> H2O cluster name: H2O_started_from_R_root_mwl453
#> H2O cluster total nodes: 1
#> H2O cluster total memory: 7.07 GB
#> H2O cluster total cores: 8
#> H2O cluster allowed cores: 8
#> H2O cluster healthy: TRUE
#> H2O Connection ip: localhost
#> H2O Connection port: 54321
#> H2O Connection proxy: NA
#> H2O Internal Security: FALSE
#> H2O API Extensions: Amazon S3, XGBoost, Algos, AutoML, Core V3, TargetEncoder, Core V4
#> R Version: R version 3.6.3 (2020-02-29)
#> Warning in h2o.clusterInfo():
#> Your H2O cluster version is too old (7 months and 16 days)!
#> Please download and install the latest version from http://h2o.ai/download/
h2o.removeAll() ## clean slate - just in case the cluster was already runningThe h2o.deeplearning function fits H2O’s Deep Learning models from within R. We can run the example from the man page using the example function, or run a longer demonstration from the h2o package using the demo function::
args(h2o.deeplearning)
#> function (x, y, training_frame, model_id = NULL, validation_frame = NULL,
#> nfolds = 0, keep_cross_validation_models = TRUE, keep_cross_validation_predictions = FALSE,
#> keep_cross_validation_fold_assignment = FALSE, fold_assignment = c("AUTO",
#> "Random", "Modulo", "Stratified"), fold_column = NULL,
#> ignore_const_cols = TRUE, score_each_iteration = FALSE, weights_column = NULL,
#> offset_column = NULL, balance_classes = FALSE, class_sampling_factors = NULL,
#> max_after_balance_size = 5, max_hit_ratio_k = 0, checkpoint = NULL,
#> pretrained_autoencoder = NULL, overwrite_with_best_model = TRUE,
#> use_all_factor_levels = TRUE, standardize = TRUE, activation = c("Tanh",
#> "TanhWithDropout", "Rectifier", "RectifierWithDropout",
#> "Maxout", "MaxoutWithDropout"), hidden = c(200, 200),
#> epochs = 10, train_samples_per_iteration = -2, target_ratio_comm_to_comp = 0.05,
#> seed = -1, adaptive_rate = TRUE, rho = 0.99, epsilon = 1e-08,
#> rate = 0.005, rate_annealing = 1e-06, rate_decay = 1, momentum_start = 0,
#> momentum_ramp = 1e+06, momentum_stable = 0, nesterov_accelerated_gradient = TRUE,
#> input_dropout_ratio = 0, hidden_dropout_ratios = NULL, l1 = 0,
#> l2 = 0, max_w2 = 3.4028235e+38, initial_weight_distribution = c("UniformAdaptive",
#> "Uniform", "Normal"), initial_weight_scale = 1, initial_weights = NULL,
#> initial_biases = NULL, loss = c("Automatic", "CrossEntropy",
#> "Quadratic", "Huber", "Absolute", "Quantile"), distribution = c("AUTO",
#> "bernoulli", "multinomial", "gaussian", "poisson", "gamma",
#> "tweedie", "laplace", "quantile", "huber"), quantile_alpha = 0.5,
#> tweedie_power = 1.5, huber_alpha = 0.9, score_interval = 5,
#> score_training_samples = 10000, score_validation_samples = 0,
#> score_duty_cycle = 0.1, classification_stop = 0, regression_stop = 1e-06,
#> stopping_rounds = 5, stopping_metric = c("AUTO", "deviance",
#> "logloss", "MSE", "RMSE", "MAE", "RMSLE", "AUC", "AUCPR",
#> "lift_top_group", "misclassification", "mean_per_class_error",
#> "custom", "custom_increasing"), stopping_tolerance = 0,
#> max_runtime_secs = 0, score_validation_sampling = c("Uniform",
#> "Stratified"), diagnostics = TRUE, fast_mode = TRUE,
#> force_load_balance = TRUE, variable_importances = TRUE, replicate_training_data = TRUE,
#> single_node_mode = FALSE, shuffle_training_data = FALSE,
#> missing_values_handling = c("MeanImputation", "Skip"), quiet_mode = FALSE,
#> autoencoder = FALSE, sparse = FALSE, col_major = FALSE, average_activation = 0,
#> sparsity_beta = 0, max_categorical_features = 2147483647,
#> reproducible = FALSE, export_weights_and_biases = FALSE,
#> mini_batch_size = 1, categorical_encoding = c("AUTO", "Enum",
#> "OneHotInternal", "OneHotExplicit", "Binary", "Eigen",
#> "LabelEncoder", "SortByResponse", "EnumLimited"), elastic_averaging = FALSE,
#> elastic_averaging_moving_rate = 0.9, elastic_averaging_regularization = 0.001,
#> export_checkpoints_dir = NULL, verbose = FALSE)
#> NULL
if (interactive()) help(h2o.deeplearning)
example(h2o.deeplearning)
#>
#> h2.dpl> ## Not run:
#> h2.dpl> ##D library(h2o)
#> h2.dpl> ##D h2o.init()
#> h2.dpl> ##D iris_hf <- as.h2o(iris)
#> h2.dpl> ##D iris_dl <- h2o.deeplearning(x = 1:4, y = 5, training_frame = iris_hf, seed=123456)
#> h2.dpl> ##D
#> h2.dpl> ##D # now make a prediction
#> h2.dpl> ##D predictions <- h2o.predict(iris_dl, iris_hf)
#> h2.dpl> ## End(Not run)
#> h2.dpl>
#> h2.dpl>
#> h2.dpl>
if (interactive()) demo(h2o.deeplearning) #requires user interactionWhile H2O Deep Learning has many parameters, it was designed to be just as easy to use as the other supervised training methods in H2O. Early stopping, automatic data standardization and handling of categorical variables and missing values and adaptive learning rates (per weight) reduce the amount of parameters the user has to specify. Often, it’s just the number and sizes of hidden layers, the number of epochs and the activation function and maybe some regularization techniques.
46.4 Let’s have some fun first: Decision Boundaries
We start with a small dataset representing red and black dots on a plane, arranged in the shape of two nested spirals. Then we task H2O’s machine learning methods to separate the red and black dots, i.e., recognize each spiral as such by assigning each point in the plane to one of the two spirals.
We visualize the nature of H2O Deep Learning (DL), H2O’s tree methods (GBM/DRF) and H2O’s generalized linear modeling (GLM) by plotting the decision boundary between the red and black spirals:
# setwd("~/h2o-tutorials/tutorials/deeplearning") ##For RStudio
spiral <- h2o.importFile(path = normalizePath(file.path(data_raw_dir, "spiral.csv")))
#>
|
| | 0%
|
|======================================================================| 100%
grid <- h2o.importFile(path = normalizePath(file.path(data_raw_dir, "grid.csv")))
#>
|
| | 0%
|
|=============== | 22%
|
|======================================================================| 100%
# Define helper to plot contours
plotC <- function(name, model, data=spiral, g=grid) {
data <- as.data.frame(data) #get data from into R
pred <- as.data.frame(h2o.predict(model, g))
n=0.5*(sqrt(nrow(g))-1); d <- 1.5; h <- d*(-n:n)/n
plot(data[,-3],pch=19,col=data[,3],cex=0.5,
xlim=c(-d,d),ylim=c(-d,d),main=name)
contour(h,h,z=array(ifelse(pred[,1]=="Red",0,1),
dim=c(2*n+1,2*n+1)),col="blue",lwd=2,add=T)
}We build a few different models:
#dev.new(noRStudioGD=FALSE) #direct plotting output to a new window
par(mfrow=c(2,2)) #set up the canvas for 2x2 plots
plotC( "DL", h2o.deeplearning(1:2,3,spiral,epochs=1e3))
plotC("GBM", h2o.gbm (1:2,3,spiral))
plotC("DRF", h2o.randomForest(1:2,3,spiral))
plotC("GLM", h2o.glm (1:2,3,spiral,family="binomial"))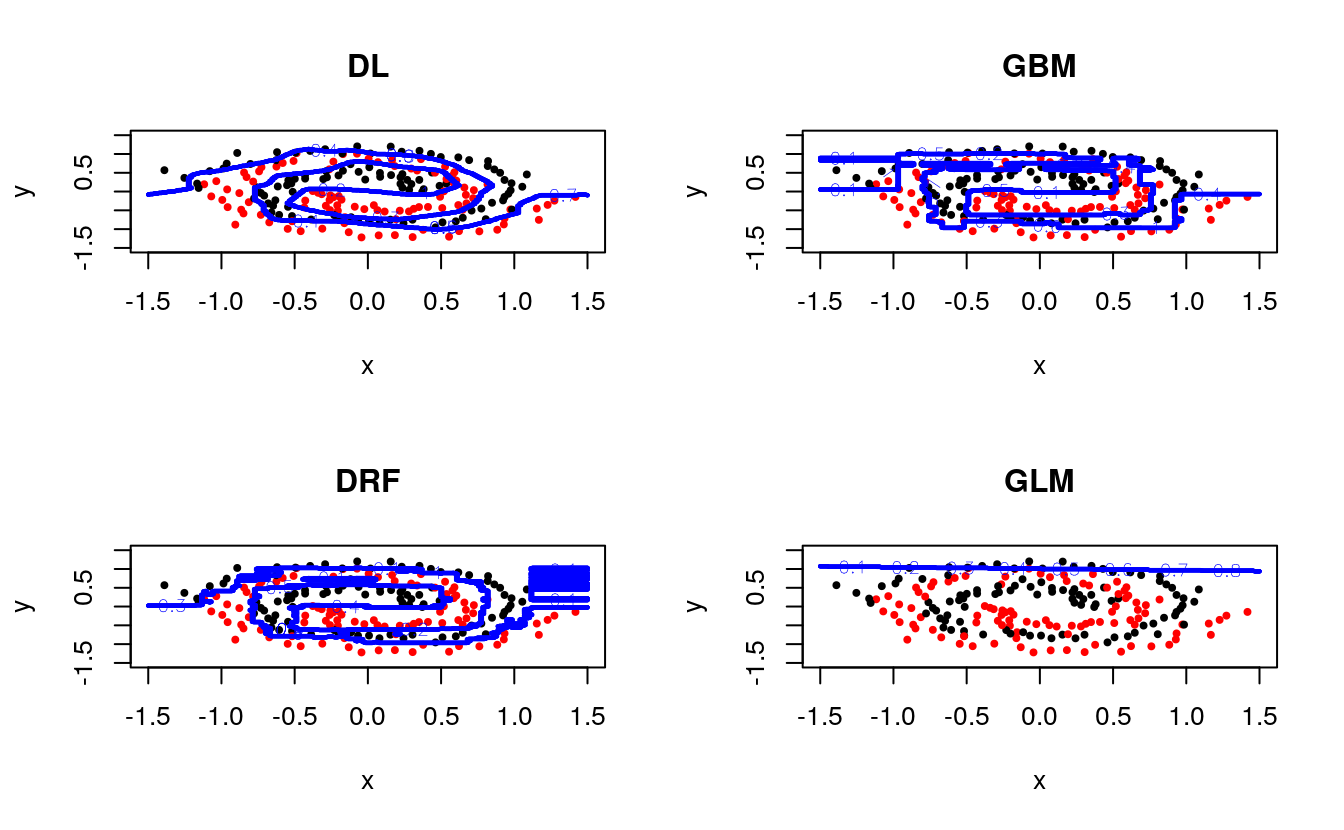 Let’s investigate some more Deep Learning models. First, we explore the evolution over training time (number of passes over the data), and we use checkpointing to continue training the same model:
Let’s investigate some more Deep Learning models. First, we explore the evolution over training time (number of passes over the data), and we use checkpointing to continue training the same model:
#dev.new(noRStudioGD=FALSE) #direct plotting output to a new window
par(mfrow=c(2,2)) #set up the canvas for 2x2 plots
ep <- c(1,250,500,750)
plotC(paste0("DL ",ep[1]," epochs"),
h2o.deeplearning(1:2,3,spiral,epochs=ep[1],
model_id="dl_1"))
plotC(paste0("DL ",ep[2]," epochs"),
h2o.deeplearning(1:2,3,spiral,epochs=ep[2],
checkpoint="dl_1",model_id="dl_2"))
plotC(paste0("DL ",ep[3]," epochs"),
h2o.deeplearning(1:2,3,spiral,epochs=ep[3],
checkpoint="dl_2",model_id="dl_3"))
plotC(paste0("DL ",ep[4]," epochs"),
h2o.deeplearning(1:2,3,spiral,epochs=ep[4],
checkpoint="dl_3",model_id="dl_4"))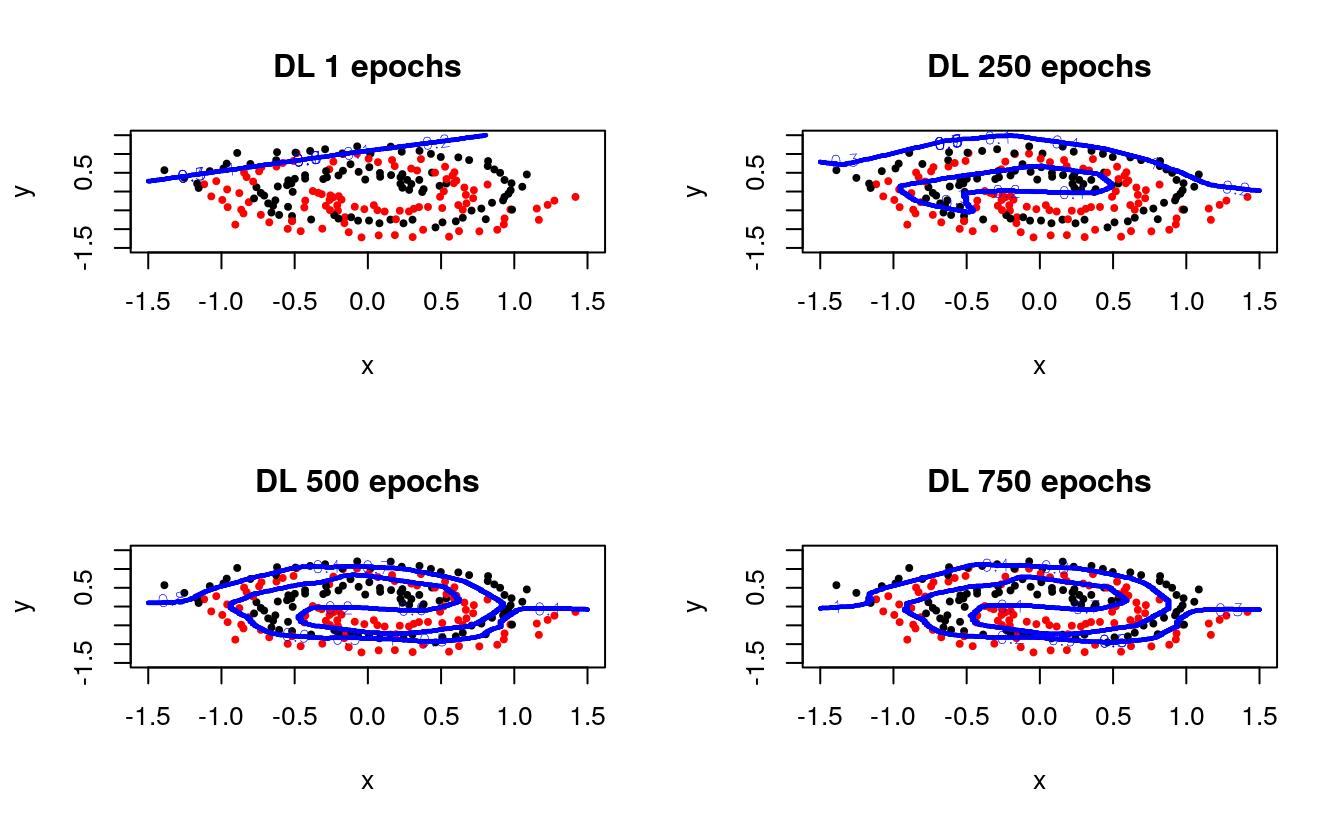
You can see how the network learns the structure of the spirals with enough training time. We explore different network architectures next:
#dev.new(noRStudioGD=FALSE) #direct plotting output to a new window
par(mfrow=c(2,2)) #set up the canvas for 2x2 plots
for (hidden in list(c(11,13,17,19),c(42,42,42),c(200,200),c(1000))) {
plotC(paste0("DL hidden=",paste0(hidden, collapse="x")),
h2o.deeplearning(1:2,3 ,spiral, hidden=hidden, epochs=500))
}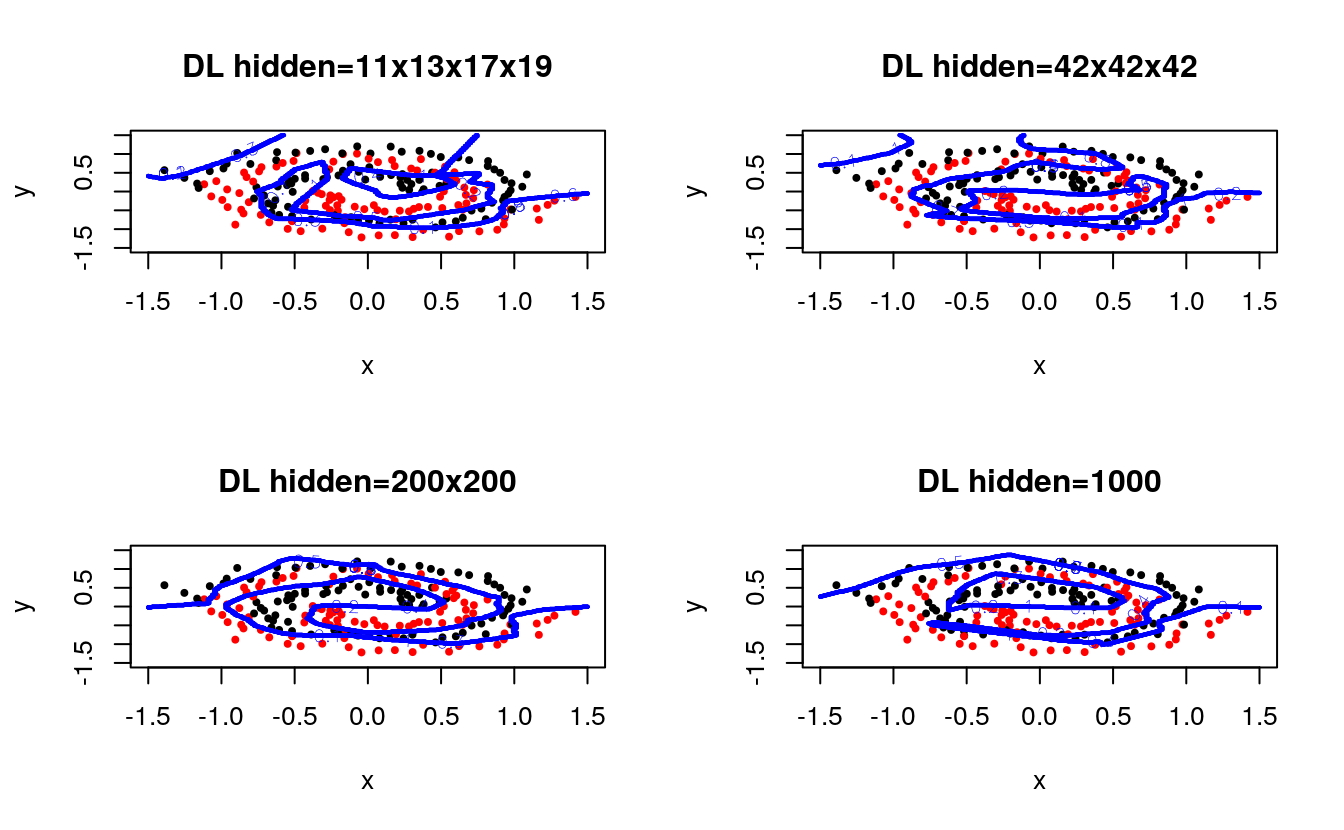
It is clear that different configurations can achieve similar performance, and that tuning will be required for optimal performance. Next, we compare between different activation functions, including one with 50% dropout regularization in the hidden layers:
#dev.new(noRStudioGD=FALSE) #direct plotting output to a new window
par(mfrow=c(2,2)) #set up the canvas for 2x2 plots
for (act in c("Tanh", "Maxout", "Rectifier", "RectifierWithDropout")) {
plotC(paste0("DL ",act," activation"),
h2o.deeplearning(1:2,3, spiral,
activation = act,
hidden = c(100,100),
epochs = 1000))
}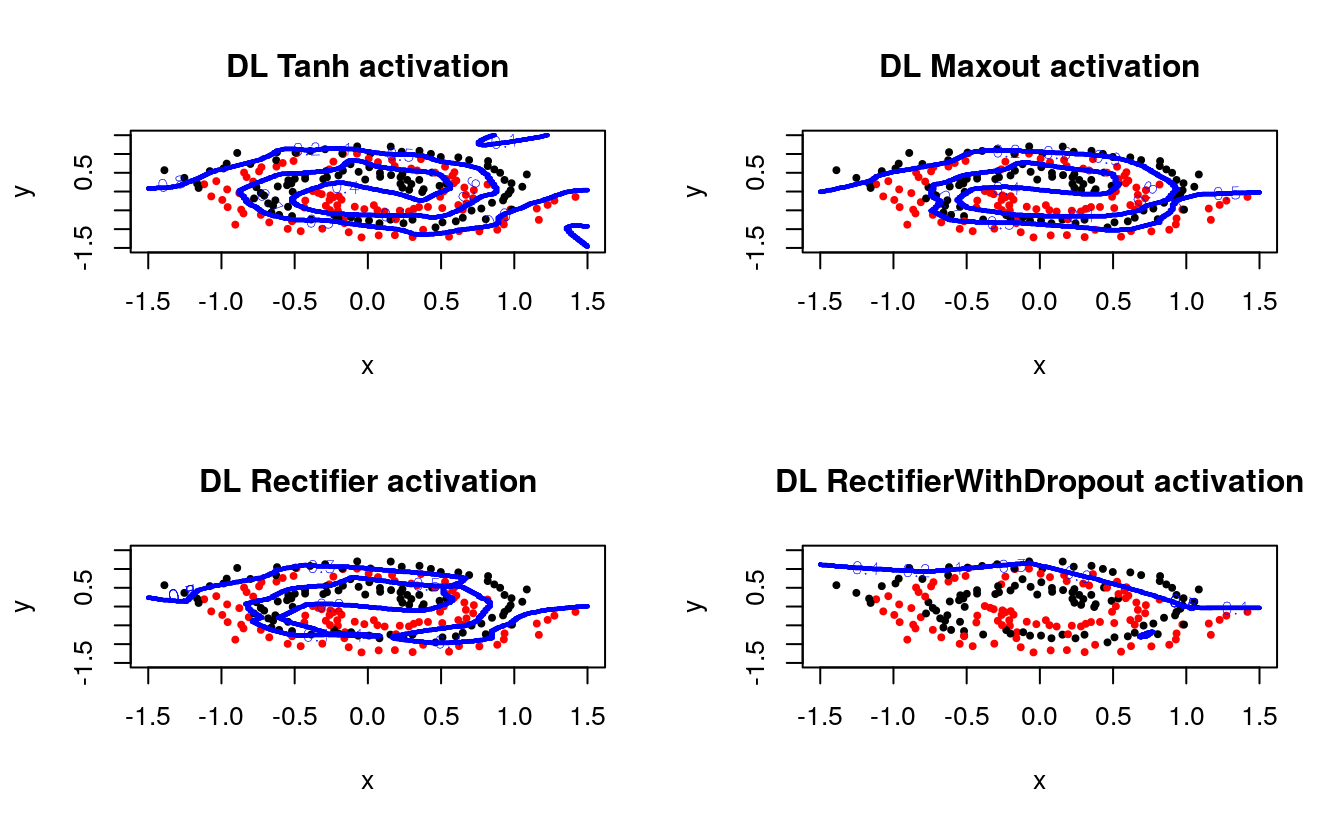
Clearly, the dropout rate was too high or the number of epochs was too low for the last configuration, which often ends up performing the best on larger datasets where generalization is important.
More information about the parameters can be found in the H2O Deep Learning booklet.
46.5 Cover Type Dataset
We important the full cover type dataset (581k rows, 13 columns, 10 numerical, 3 categorical). We also split the data 3 ways: 60% for training, 20% for validation (hyper parameter tuning) and 20% for final testing.
df <- h2o.importFile(path = normalizePath(file.path(data_raw_dir, "covtype.full.csv")))
#>
|
| | 0%
|
|======================================================================| 100%
dim(df)
#> [1] 581012 13
df
#> Elevation Aspect Slope Horizontal_Distance_To_Hydrology
#> 1 3066 124 5 0
#> 2 3136 32 20 450
#> 3 2655 28 14 42
#> 4 3191 45 19 323
#> 5 3217 80 13 30
#> 6 3119 293 13 30
#> Vertical_Distance_To_Hydrology Horizontal_Distance_To_Roadways Hillshade_9am
#> 1 0 1533 229
#> 2 -38 1290 211
#> 3 8 1890 214
#> 4 88 3932 221
#> 5 1 3901 237
#> 6 10 4810 182
#> Hillshade_Noon Hillshade_3pm Horizontal_Distance_To_Fire_Points
#> 1 236 141 459
#> 2 193 111 1112
#> 3 209 128 1001
#> 4 195 100 2919
#> 5 217 109 2859
#> 6 237 194 1200
#> Wilderness_Area Soil_Type Cover_Type
#> 1 area_0 type_22 class_1
#> 2 area_0 type_28 class_1
#> 3 area_2 type_9 class_2
#> 4 area_0 type_39 class_2
#> 5 area_0 type_22 class_7
#> 6 area_0 type_21 class_1
#>
#> [581012 rows x 13 columns]
splits <- h2o.splitFrame(df, c(0.6, 0.2), seed=1234)
train <- h2o.assign(splits[[1]], "train.hex") # 60%
valid <- h2o.assign(splits[[2]], "valid.hex") # 20%
test <- h2o.assign(splits[[3]], "test.hex") # 20%Here’s a scalable way to do scatter plots via binning (works for categorical and numeric columns) to get more familiar with the dataset.
#dev.new(noRStudioGD=FALSE) #direct plotting output to a new window
par(mfrow=c(1,1)) # reset canvas
plot(h2o.tabulate(df, "Elevation", "Cover_Type"))
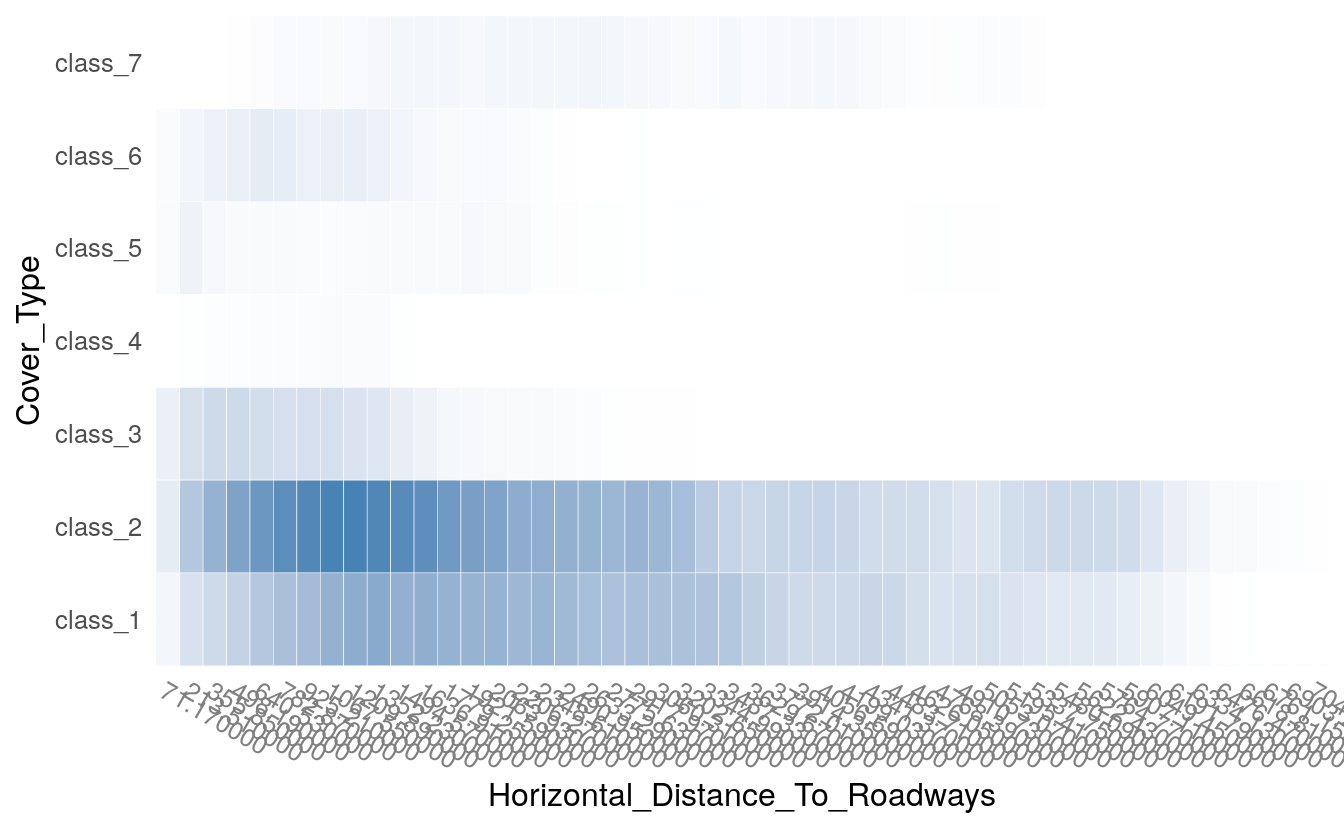
plot(h2o.tabulate(df, "Horizontal_Distance_To_Roadways", "Cover_Type"))
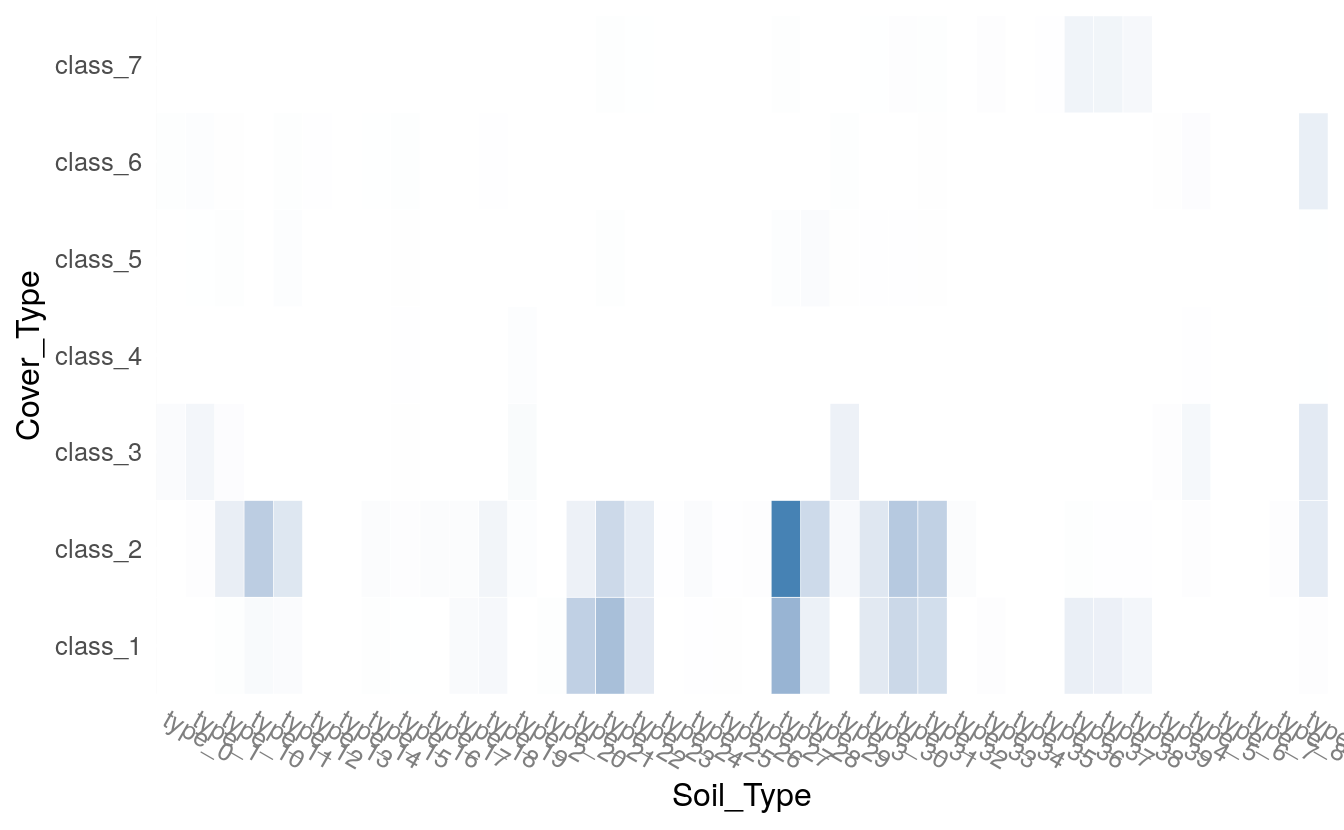
plot(h2o.tabulate(df, "Soil_Type", "Cover_Type"))
plot(h2o.tabulate(df, "Horizontal_Distance_To_Roadways", "Elevation" ))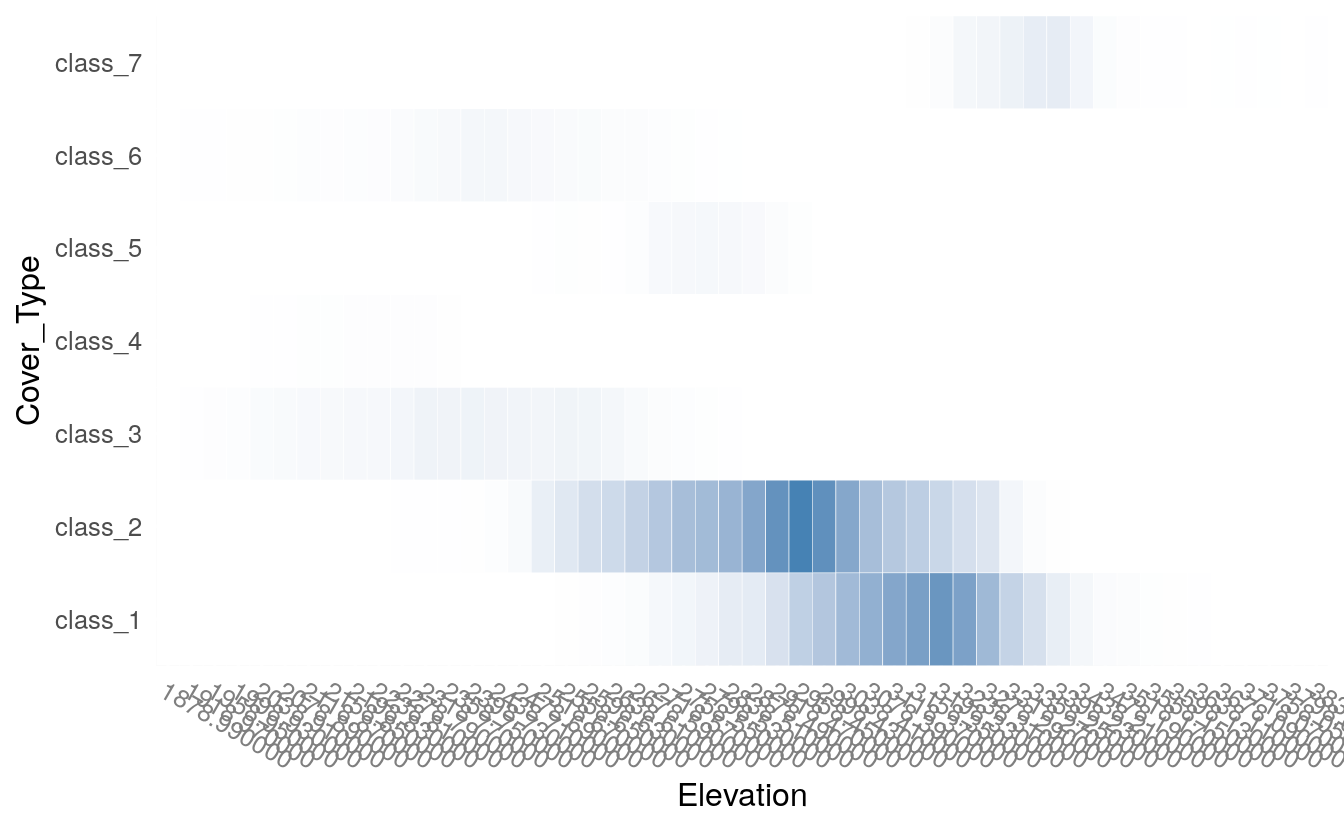
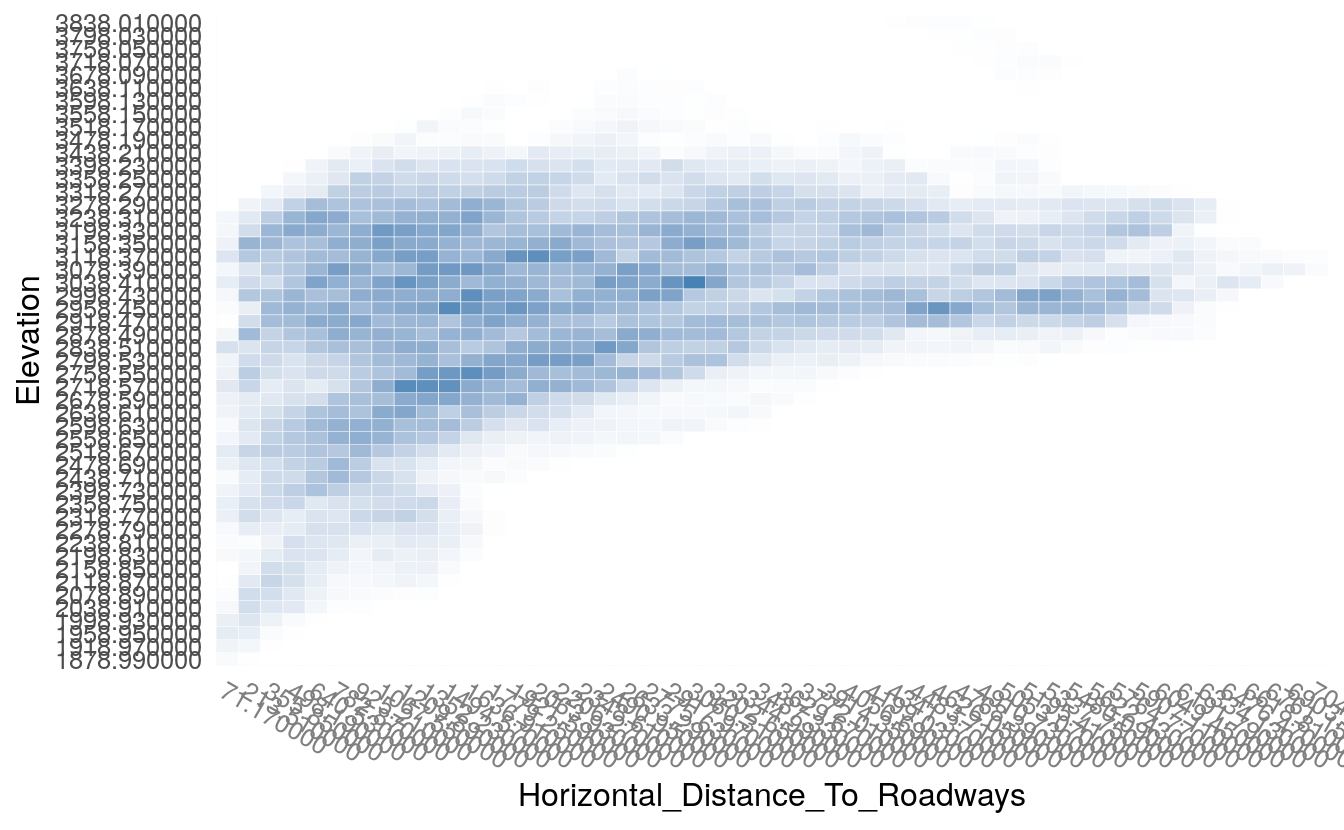
46.5.1 First Run of H2O Deep Learning
Let’s run our first Deep Learning model on the covtype dataset. We want to predict the Cover_Type column, a categorical feature with 7 levels, and the Deep Learning model will be tasked to perform (multi-class) classification. It uses the other 12 predictors of the dataset, of which 10 are numerical, and 2 are categorical with a total of 44 levels. We can expect the Deep Learning model to have 56 input neurons (after automatic one-hot encoding).
response <- "Cover_Type"
predictors <- setdiff(names(df), response)
predictors
#> [1] "Elevation" "Aspect"
#> [3] "Slope" "Horizontal_Distance_To_Hydrology"
#> [5] "Vertical_Distance_To_Hydrology" "Horizontal_Distance_To_Roadways"
#> [7] "Hillshade_9am" "Hillshade_Noon"
#> [9] "Hillshade_3pm" "Horizontal_Distance_To_Fire_Points"
#> [11] "Wilderness_Area" "Soil_Type"
train_df <- as.data.frame(train)
str(train_df)
#> 'data.frame': 349015 obs. of 13 variables:
#> $ Elevation : int 3136 3217 3119 2679 3261 2885 3227 2843 2853 2883 ...
#> $ Aspect : int 32 80 293 48 322 26 32 12 124 177 ...
#> $ Slope : int 20 13 13 7 13 9 6 18 12 9 ...
#> $ Horizontal_Distance_To_Hydrology : int 450 30 30 150 30 192 108 335 30 426 ...
#> $ Vertical_Distance_To_Hydrology : int -38 1 10 24 5 38 13 50 -5 126 ...
#> $ Horizontal_Distance_To_Roadways : int 1290 3901 4810 1588 5701 3271 5542 2642 1485 2139 ...
#> $ Hillshade_9am : int 211 237 182 223 186 216 219 199 240 225 ...
#> $ Hillshade_Noon : int 193 217 237 224 226 220 227 201 231 246 ...
#> $ Hillshade_3pm : int 111 109 194 136 180 140 145 135 119 153 ...
#> $ Horizontal_Distance_To_Fire_Points: int 1112 2859 1200 6265 769 2643 765 1719 2497 713 ...
#> $ Wilderness_Area : Factor w/ 4 levels "area_0","area_1",..: 1 1 1 1 1 1 1 3 3 3 ...
#> $ Soil_Type : Factor w/ 40 levels "type_0","type_1",..: 22 16 15 4 15 22 15 27 12 25 ...
#> $ Cover_Type : Factor w/ 7 levels "class_1","class_2",..: 1 7 1 2 1 2 1 2 1 2 ...
valid_df <- as.data.frame(valid)
str(valid_df)
#> 'data.frame': 116018 obs. of 13 variables:
#> $ Elevation : int 3066 2655 2902 2994 2697 2990 3237 2884 2972 2696 ...
#> $ Aspect : int 124 28 304 61 93 59 135 71 100 169 ...
#> $ Slope : int 5 14 22 9 9 12 14 9 4 10 ...
#> $ Horizontal_Distance_To_Hydrology : int 0 42 511 391 306 108 240 459 175 323 ...
#> $ Vertical_Distance_To_Hydrology : int 0 8 18 57 -2 10 -11 141 13 149 ...
#> $ Horizontal_Distance_To_Roadways : int 1533 1890 1273 4286 553 2190 1189 1214 5031 2452 ...
#> $ Hillshade_9am : int 229 214 155 227 234 229 241 231 227 228 ...
#> $ Hillshade_Noon : int 236 209 223 222 227 215 233 222 234 244 ...
#> $ Hillshade_3pm : int 141 128 206 128 125 117 118 124 142 148 ...
#> $ Horizontal_Distance_To_Fire_Points: int 459 1001 1347 1928 1716 1048 2748 1355 6198 1044 ...
#> $ Wilderness_Area : Factor w/ 4 levels "area_0","area_1",..: 1 3 3 1 1 3 1 3 1 3 ...
#> $ Soil_Type : Factor w/ 39 levels "type_0","type_1",..: 15 39 25 4 4 25 14 25 11 23 ...
#> $ Cover_Type : Factor w/ 7 levels "class_1","class_2",..: 1 2 2 2 2 2 1 2 1 3 ...To keep it fast, we only run for one epoch (one pass over the training data).
m1 <- h2o.deeplearning(
model_id="dl_model_first",
training_frame = train,
validation_frame = valid, ## validation dataset: used for scoring and early stopping
x = predictors,
y = response,
#activation="Rectifier", ## default
#hidden=c(200,200), ## default: 2 hidden layers with 200 neurons each
epochs = 1,
variable_importances=T ## not enabled by default
)
#>
|
| | 0%
|
|======= | 10%
|
|============== | 20%
|
|===================== | 30%
|
|============================ | 40%
|
|=================================== | 50%
|
|========================================== | 60%
|
|================================================= | 70%
|
|======================================================== | 80%
|
|=============================================================== | 90%
|
|======================================================================| 100%
summary(m1)
#> Model Details:
#> ==============
#>
#> H2OMultinomialModel: deeplearning
#> Model Key: dl_model_first
#> Status of Neuron Layers: predicting Cover_Type, 7-class classification, multinomial distribution, CrossEntropy loss, 53,007 weights/biases, 633.2 KB, 383,519 training samples, mini-batch size 1
#> layer units type dropout l1 l2 mean_rate rate_rms momentum
#> 1 1 56 Input 0.00 % NA NA NA NA NA
#> 2 2 200 Rectifier 0.00 % 0.000000 0.000000 0.049043 0.209607 0.000000
#> 3 3 200 Rectifier 0.00 % 0.000000 0.000000 0.010094 0.009352 0.000000
#> 4 4 7 Softmax NA 0.000000 0.000000 0.123164 0.300241 0.000000
#> mean_weight weight_rms mean_bias bias_rms
#> 1 NA NA NA NA
#> 2 -0.010410 0.118736 0.006004 0.115481
#> 3 -0.024505 0.118881 0.696468 0.402678
#> 4 -0.401315 0.506471 -0.529662 0.127334
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on training data. **
#> ** Metrics reported on temporary training frame with 9917 samples **
#>
#> Training Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.126
#> RMSE: (Extract with `h2o.rmse`) 0.355
#> Logloss: (Extract with `h2o.logloss`) 0.406
#> Mean Per-Class Error: 0.338
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,train = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3067 539 6 0 2 1 41 0.1611
#> class_2 580 4069 49 0 14 50 10 0.1473
#> class_3 0 28 502 1 1 68 0 0.1633
#> class_4 0 0 31 15 0 2 0 0.6875
#> class_5 6 76 8 0 66 0 0 0.5769
#> class_6 3 33 95 0 0 155 0 0.4580
#> class_7 69 0 0 0 0 0 330 0.1729
#> Totals 3725 4745 691 16 83 276 381 0.1727
#> Rate
#> class_1 = 589 / 3,656
#> class_2 = 703 / 4,772
#> class_3 = 98 / 600
#> class_4 = 33 / 48
#> class_5 = 90 / 156
#> class_6 = 131 / 286
#> class_7 = 69 / 399
#> Totals = 1,713 / 9,917
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,train = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.827266
#> 2 2 0.983059
#> 3 3 0.997882
#> 4 4 0.999496
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on full validation frame **
#>
#> Validation Set Metrics:
#> =====================
#>
#> Extract validation frame with `h2o.getFrame("valid.hex")`
#> MSE: (Extract with `h2o.mse`) 0.129
#> RMSE: (Extract with `h2o.rmse`) 0.359
#> Logloss: (Extract with `h2o.logloss`) 0.418
#> Mean Per-Class Error: 0.332
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 35220 6644 15 0 28 9 584 0.1713
#> class_2 6936 48033 663 0 191 465 92 0.1480
#> class_3 0 261 6077 19 1 785 0 0.1492
#> class_4 0 0 312 204 0 46 0 0.6370
#> class_5 98 969 72 0 721 10 0 0.6144
#> class_6 14 353 1112 14 4 1967 0 0.4322
#> class_7 655 49 0 0 0 0 3395 0.1717
#> Totals 42923 56309 8251 237 945 3282 4071 0.1758
#> Rate
#> class_1 = 7,280 / 42,500
#> class_2 = 8,347 / 56,380
#> class_3 = 1,066 / 7,143
#> class_4 = 358 / 562
#> class_5 = 1,149 / 1,870
#> class_6 = 1,497 / 3,464
#> class_7 = 704 / 4,099
#> Totals = 20,401 / 116,018
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.824157
#> 2 2 0.983140
#> 3 3 0.998181
#> 4 4 0.999578
#> 5 5 0.999991
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#>
#>
#> Scoring History:
#> timestamp duration training_speed epochs iterations
#> 1 2020-11-20 00:45:27 0.000 sec NA 0.00000 0
#> 2 2020-11-20 00:45:32 6.317 sec 7614 obs/sec 0.09999 1
#> 3 2020-11-20 00:45:48 22.762 sec 10809 obs/sec 0.59900 6
#> 4 2020-11-20 00:46:03 37.179 sec 11913 obs/sec 1.09886 11
#> samples training_rmse training_logloss training_r2
#> 1 0.000000 NA NA NA
#> 2 34899.000000 0.46850 0.70860 0.89309
#> 3 209061.000000 0.39074 0.48955 0.92564
#> 4 383519.000000 0.35509 0.40628 0.93859
#> training_classification_error validation_rmse validation_logloss
#> 1 NA NA NA
#> 2 0.29001 0.46797 0.70318
#> 3 0.20067 0.39502 0.49726
#> 4 0.17273 0.35949 0.41816
#> validation_r2 validation_classification_error
#> 1 NA NA
#> 2 0.88775 0.28983
#> 3 0.92002 0.20923
#> 4 0.93376 0.17584
#>
#> Variable Importances: (Extract with `h2o.varimp`)
#> =================================================
#>
#> Variable Importances:
#> variable relative_importance scaled_importance
#> 1 Wilderness_Area.area_0 1.000000 1.000000
#> 2 Horizontal_Distance_To_Roadways 0.931456 0.931456
#> 3 Elevation 0.861825 0.861825
#> 4 Horizontal_Distance_To_Fire_Points 0.848471 0.848471
#> 5 Wilderness_Area.area_2 0.789438 0.789438
#> percentage
#> 1 0.033344
#> 2 0.031058
#> 3 0.028736
#> 4 0.028291
#> 5 0.026323
#>
#> ---
#> variable relative_importance scaled_importance percentage
#> 51 Hillshade_9am 0.416170 0.416170 0.013877
#> 52 Slope 0.376747 0.376747 0.012562
#> 53 Hillshade_3pm 0.354328 0.354328 0.011815
#> 54 Aspect 0.273095 0.273095 0.009106
#> 55 Soil_Type.missing(NA) 0.000000 0.000000 0.000000
#> 56 Wilderness_Area.missing(NA) 0.000000 0.000000 0.000000Inspect the model in Flow for more information about model building etc. by issuing a cell with the content getModel “dl_model_first”, and pressing Ctrl-Enter.
46.5.2 Variable Importances
Variable importances for Neural Network models are notoriously difficult to compute, and there are many pitfalls. H2O Deep Learning has implemented the method of Gedeon, and returns relative variable importances in descending order of importance.
head(as.data.frame(h2o.varimp(m1)))
#> variable relative_importance scaled_importance
#> 1 Wilderness_Area.area_0 1.000 1.000
#> 2 Horizontal_Distance_To_Roadways 0.931 0.931
#> 3 Elevation 0.862 0.862
#> 4 Horizontal_Distance_To_Fire_Points 0.848 0.848
#> 5 Wilderness_Area.area_2 0.789 0.789
#> 6 Wilderness_Area.area_1 0.762 0.762
#> percentage
#> 1 0.0333
#> 2 0.0311
#> 3 0.0287
#> 4 0.0283
#> 5 0.0263
#> 6 0.025446.5.3 Early Stopping
Now we run another, smaller network, and we let it stop automatically once the misclassification rate converges (specifically, if the moving average of length 2 does not improve by at least 1% for 2 consecutive scoring events). We also sample the validation set to 10,000 rows for faster scoring.
m2 <- h2o.deeplearning(
model_id="dl_model_faster",
training_frame=train,
validation_frame=valid,
x=predictors,
y=response,
hidden=c(32,32,32), ## small network, runs faster
epochs=1000000, ## hopefully converges earlier...
score_validation_samples=10000, ## sample the validation dataset (faster)
stopping_rounds=2,
stopping_metric="misclassification", ## could be "MSE","logloss","r2"
stopping_tolerance=0.01
)
#>
|
| | 0%
|
|======================================================================| 100%
summary(m2)
#> Model Details:
#> ==============
#>
#> H2OMultinomialModel: deeplearning
#> Model Key: dl_model_faster
#> Status of Neuron Layers: predicting Cover_Type, 7-class classification, multinomial distribution, CrossEntropy loss, 4,167 weights/biases, 57.9 KB, 6,997,636 training samples, mini-batch size 1
#> layer units type dropout l1 l2 mean_rate rate_rms momentum
#> 1 1 56 Input 0.00 % NA NA NA NA NA
#> 2 2 32 Rectifier 0.00 % 0.000000 0.000000 0.044750 0.205196 0.000000
#> 3 3 32 Rectifier 0.00 % 0.000000 0.000000 0.000365 0.000203 0.000000
#> 4 4 32 Rectifier 0.00 % 0.000000 0.000000 0.000650 0.000469 0.000000
#> 5 5 7 Softmax NA 0.000000 0.000000 0.081947 0.251862 0.000000
#> mean_weight weight_rms mean_bias bias_rms
#> 1 NA NA NA NA
#> 2 0.002544 0.302103 0.183948 0.343792
#> 3 -0.042678 0.401781 0.630921 0.764434
#> 4 0.018843 0.577631 0.723080 0.573754
#> 5 -3.421288 3.540264 -4.262941 2.090440
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on training data. **
#> ** Metrics reported on temporary training frame with 9899 samples **
#>
#> Training Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.108
#> RMSE: (Extract with `h2o.rmse`) 0.329
#> Logloss: (Extract with `h2o.logloss`) 0.359
#> Mean Per-Class Error: 0.209
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,train = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3041 513 0 0 2 1 43 0.1553
#> class_2 453 4303 40 0 36 35 10 0.1177
#> class_3 0 25 495 17 1 52 0 0.1610
#> class_4 0 0 11 38 0 4 0 0.2830
#> class_5 9 43 2 0 116 1 0 0.3216
#> class_6 2 29 62 4 2 200 0 0.3311
#> class_7 28 1 0 0 0 0 280 0.0939
#> Totals 3533 4914 610 59 157 293 333 0.1441
#> Rate
#> class_1 = 559 / 3,600
#> class_2 = 574 / 4,877
#> class_3 = 95 / 590
#> class_4 = 15 / 53
#> class_5 = 55 / 171
#> class_6 = 99 / 299
#> class_7 = 29 / 309
#> Totals = 1,426 / 9,899
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,train = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.855945
#> 2 2 0.986463
#> 3 3 0.998485
#> 4 4 0.999596
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on temporary validation frame with 9964 samples **
#>
#> Validation Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.112
#> RMSE: (Extract with `h2o.rmse`) 0.334
#> Logloss: (Extract with `h2o.logloss`) 0.376
#> Mean Per-Class Error: 0.245
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3093 507 0 0 4 1 36 0.1505
#> class_2 457 4221 36 0 44 33 6 0.1201
#> class_3 0 25 529 20 0 69 0 0.1773
#> class_4 0 0 12 33 0 4 0 0.3265
#> class_5 8 64 11 0 98 0 0 0.4586
#> class_6 2 25 72 2 2 198 0 0.3422
#> class_7 47 1 0 0 0 0 304 0.1364
#> Totals 3607 4843 660 55 148 305 346 0.1493
#> Rate
#> class_1 = 548 / 3,641
#> class_2 = 576 / 4,797
#> class_3 = 114 / 643
#> class_4 = 16 / 49
#> class_5 = 83 / 181
#> class_6 = 103 / 301
#> class_7 = 48 / 352
#> Totals = 1,488 / 9,964
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.850662
#> 2 2 0.986451
#> 3 3 0.997290
#> 4 4 0.999498
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#>
#>
#> Scoring History:
#> timestamp duration training_speed epochs iterations
#> 1 2020-11-20 00:46:05 0.000 sec NA 0.00000 0
#> 2 2020-11-20 00:46:06 1.165 sec 90270 obs/sec 0.28580 1
#> 3 2020-11-20 00:46:11 6.524 sec 108717 obs/sec 2.00480 7
#> 4 2020-11-20 00:46:16 11.558 sec 113586 obs/sec 3.72313 13
#> 5 2020-11-20 00:46:22 17.093 sec 117990 obs/sec 5.72920 20
#> 6 2020-11-20 00:46:27 22.467 sec 121073 obs/sec 7.73277 27
#> 7 2020-11-20 00:46:33 27.777 sec 123275 obs/sec 9.73939 34
#> 8 2020-11-20 00:46:38 32.886 sec 125556 obs/sec 11.73989 41
#> 9 2020-11-20 00:46:43 37.997 sec 127220 obs/sec 13.74839 48
#> 10 2020-11-20 00:46:49 43.645 sec 129171 obs/sec 16.03798 56
#> 11 2020-11-20 00:46:54 48.693 sec 130235 obs/sec 18.04370 63
#> 12 2020-11-20 00:46:59 53.711 sec 131172 obs/sec 20.04967 70
#> 13 2020-11-20 00:46:59 53.740 sec 131167 obs/sec 20.04967 70
#> samples training_rmse training_logloss training_r2
#> 1 0.000000 NA NA NA
#> 2 99749.000000 0.43749 0.59375 0.89724
#> 3 699706.000000 0.37934 0.45952 0.92274
#> 4 1299427.000000 0.36669 0.43114 0.92781
#> 5 1999578.000000 0.35577 0.41289 0.93205
#> 6 2698851.000000 0.35258 0.40475 0.93326
#> 7 3399193.000000 0.34105 0.38773 0.93755
#> 8 4097398.000000 0.33517 0.37329 0.93968
#> 9 4798393.000000 0.33161 0.36779 0.94096
#> 10 5597496.000000 0.32921 0.35920 0.94181
#> 11 6297522.000000 0.32682 0.35087 0.94265
#> 12 6997636.000000 0.32666 0.35614 0.94271
#> 13 6997636.000000 0.32921 0.35920 0.94181
#> training_classification_error validation_rmse validation_logloss
#> 1 NA NA NA
#> 2 0.25366 0.43677 0.59368
#> 3 0.19376 0.38519 0.47204
#> 4 0.18032 0.37263 0.44703
#> 5 0.16971 0.36044 0.42456
#> 6 0.16365 0.35549 0.41467
#> 7 0.15719 0.34788 0.40580
#> 8 0.15173 0.33894 0.38546
#> 9 0.14426 0.33504 0.38034
#> 10 0.14405 0.33441 0.37603
#> 11 0.14304 0.33181 0.36860
#> 12 0.14143 0.33281 0.37346
#> 13 0.14405 0.33441 0.37603
#> validation_r2 validation_classification_error
#> 1 NA NA
#> 2 0.90345 0.25161
#> 3 0.92491 0.19791
#> 4 0.92973 0.18446
#> 5 0.93425 0.17021
#> 6 0.93604 0.16831
#> 7 0.93875 0.16038
#> 8 0.94186 0.15295
#> 9 0.94319 0.14954
#> 10 0.94340 0.14934
#> 11 0.94428 0.14934
#> 12 0.94394 0.15004
#> 13 0.94340 0.14934
#>
#> Variable Importances: (Extract with `h2o.varimp`)
#> =================================================
#>
#> Variable Importances:
#> variable relative_importance scaled_importance
#> 1 Horizontal_Distance_To_Roadways 1.000000 1.000000
#> 2 Wilderness_Area.area_0 0.987520 0.987520
#> 3 Elevation 0.977226 0.977226
#> 4 Wilderness_Area.area_1 0.936496 0.936496
#> 5 Soil_Type.type_21 0.839471 0.839471
#> percentage
#> 1 0.034230
#> 2 0.033803
#> 3 0.033451
#> 4 0.032056
#> 5 0.028735
#>
#> ---
#> variable relative_importance scaled_importance
#> 51 Soil_Type.type_14 0.272257 0.272257
#> 52 Vertical_Distance_To_Hydrology 0.246618 0.246618
#> 53 Slope 0.165276 0.165276
#> 54 Aspect 0.049482 0.049482
#> 55 Soil_Type.missing(NA) 0.000000 0.000000
#> 56 Wilderness_Area.missing(NA) 0.000000 0.000000
#> percentage
#> 51 0.009319
#> 52 0.008442
#> 53 0.005657
#> 54 0.001694
#> 55 0.000000
#> 56 0.000000
plot(m2)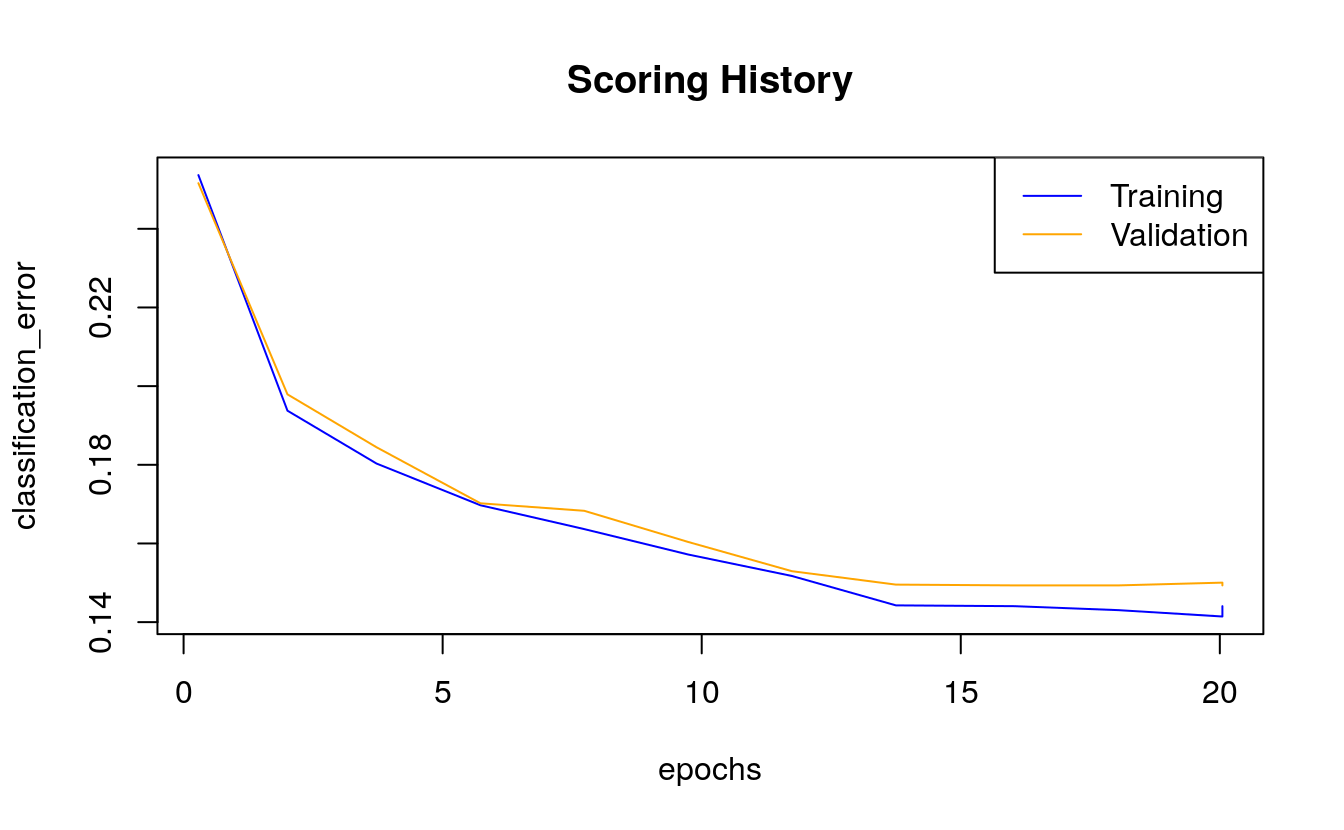
46.5.4 Adaptive Learning Rate
By default, H2O Deep Learning uses an adaptive learning rate (ADADELTA) for its stochastic gradient descent optimization. There are only two tuning parameters for this method: rho and epsilon, which balance the global and local search efficiencies. rho is the similarity to prior weight updates (similar to momentum), and epsilon is a parameter that prevents the optimization to get stuck in local optima. Defaults are rho=0.99 and epsilon=1e-8. For cases where convergence speed is very important, it might make sense to perform a few runs to optimize these two parameters (e.g., with rho in c(0.9,0.95,0.99,0.999) and epsilon in c(1e-10,1e-8,1e-6,1e-4)). Of course, as always with grid searches, caution has to be applied when extrapolating grid search results to a different parameter regime (e.g., for more epochs or different layer topologies or activation functions, etc.).
If adaptive_rate is disabled, several manual learning rate parameters become important: rate, rate_annealing, rate_decay, momentum_start, momentum_ramp, momentum_stable and nesterov_accelerated_gradient, the discussion of which we leave to H2O Deep Learning booklet.
46.5.5 Tuning
With some tuning, it is possible to obtain less than 10% test set error rate in about one minute. Error rates of below 5% are possible with larger models. Note that deep tree methods can be more effective for this dataset than Deep Learning, as they directly partition the space into sectors, which seems to be needed here.
m3 <- h2o.deeplearning(
model_id="dl_model_tuned",
training_frame=train,
validation_frame=valid,
x=predictors,
y=response,
overwrite_with_best_model=F, ## Return final model after 10 epochs, even if not the best
hidden=c(128,128,128), ## more hidden layers -> more complex interactions
epochs=10, ## to keep it short enough
score_validation_samples=10000, ## downsample validation set for faster scoring
score_duty_cycle=0.025, ## don't score more than 2.5% of the wall time
adaptive_rate=F, ## manually tuned learning rate
rate=0.01,
rate_annealing=2e-6,
momentum_start=0.2, ## manually tuned momentum
momentum_stable=0.4,
momentum_ramp=1e7,
l1=1e-5, ## add some L1/L2 regularization
l2=1e-5,
max_w2=10 ## helps stability for Rectifier
)
#>
|
| | 0%
|
|== | 3%
|
|==== | 6%
|
|====== | 9%
|
|======== | 11%
|
|========== | 14%
|
|============ | 17%
|
|============== | 20%
|
|================ | 23%
|
|================== | 26%
|
|==================== | 29%
|
|====================== | 32%
|
|======================== | 34%
|
|========================== | 37%
|
|============================ | 40%
|
|============================== | 43%
|
|================================ | 46%
|
|================================== | 49%
|
|==================================== | 52%
|
|====================================== | 54%
|
|======================================== | 57%
|
|========================================== | 60%
|
|============================================ | 63%
|
|============================================== | 66%
|
|================================================ | 69%
|
|================================================== | 72%
|
|==================================================== | 74%
|
|====================================================== | 77%
|
|======================================================== | 80%
|
|========================================================== | 83%
|
|============================================================ | 86%
|
|============================================================== | 89%
|
|================================================================ | 92%
|
|================================================================== | 95%
|
|==================================================================== | 97%
|
|======================================================================| 100%
summary(m3)
#> Model Details:
#> ==============
#>
#> H2OMultinomialModel: deeplearning
#> Model Key: dl_model_tuned
#> Status of Neuron Layers: predicting Cover_Type, 7-class classification, multinomial distribution, CrossEntropy loss, 41,223 weights/biases, 332.9 KB, 3,500,387 training samples, mini-batch size 1
#> layer units type dropout l1 l2 mean_rate rate_rms momentum
#> 1 1 56 Input 0.00 % NA NA NA NA NA
#> 2 2 128 Rectifier 0.00 % 0.000010 0.000010 0.001250 0.000000 0.270008
#> 3 3 128 Rectifier 0.00 % 0.000010 0.000010 0.001250 0.000000 0.270008
#> 4 4 128 Rectifier 0.00 % 0.000010 0.000010 0.001250 0.000000 0.270008
#> 5 5 7 Softmax NA 0.000010 0.000010 0.001250 0.000000 0.270008
#> mean_weight weight_rms mean_bias bias_rms
#> 1 NA NA NA NA
#> 2 -0.012577 0.312181 0.023897 0.327174
#> 3 -0.058654 0.222585 0.835404 0.353978
#> 4 -0.057502 0.216801 0.801143 0.205884
#> 5 -0.033170 0.269806 0.003331 0.833177
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on training data. **
#> ** Metrics reported on temporary training frame with 9853 samples **
#>
#> Training Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0542
#> RMSE: (Extract with `h2o.rmse`) 0.233
#> Logloss: (Extract with `h2o.logloss`) 0.181
#> Mean Per-Class Error: 0.116
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,train = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3414 219 0 0 3 0 18 0.0657
#> class_2 285 4487 7 0 12 4 2 0.0646
#> class_3 0 19 560 8 1 29 0 0.0924
#> class_4 0 0 1 42 0 1 0 0.0455
#> class_5 4 32 0 0 107 1 0 0.2569
#> class_6 0 18 45 0 0 215 0 0.2266
#> class_7 18 1 0 0 0 0 300 0.0596
#> Totals 3721 4776 613 50 123 250 320 0.0739
#> Rate
#> class_1 = 240 / 3,654
#> class_2 = 310 / 4,797
#> class_3 = 57 / 617
#> class_4 = 2 / 44
#> class_5 = 37 / 144
#> class_6 = 63 / 278
#> class_7 = 19 / 319
#> Totals = 728 / 9,853
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,train = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.926114
#> 2 2 0.996549
#> 3 3 0.999696
#> 4 4 1.000000
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on temporary validation frame with 9980 samples **
#>
#> Validation Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0611
#> RMSE: (Extract with `h2o.rmse`) 0.247
#> Logloss: (Extract with `h2o.logloss`) 0.201
#> Mean Per-Class Error: 0.135
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3378 233 0 0 4 1 17 0.0702
#> class_2 307 4451 5 0 30 6 6 0.0737
#> class_3 1 12 547 12 1 34 0 0.0988
#> class_4 0 0 4 41 0 9 0 0.2407
#> class_5 2 22 0 0 142 1 0 0.1497
#> class_6 0 27 52 4 0 281 0 0.2280
#> class_7 29 1 0 0 0 0 320 0.0857
#> Totals 3717 4746 608 57 177 332 343 0.0822
#> Rate
#> class_1 = 255 / 3,633
#> class_2 = 354 / 4,805
#> class_3 = 60 / 607
#> class_4 = 13 / 54
#> class_5 = 25 / 167
#> class_6 = 83 / 364
#> class_7 = 30 / 350
#> Totals = 820 / 9,980
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.917836
#> 2 2 0.996293
#> 3 3 0.999800
#> 4 4 1.000000
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#>
#>
#> Scoring History:
#> timestamp duration training_speed epochs iterations
#> 1 2020-11-20 00:46:59 0.000 sec NA 0.00000 0
#> 2 2020-11-20 00:47:04 5.374 sec 19667 obs/sec 0.28570 1
#> 3 2020-11-20 00:47:16 17.004 sec 24298 obs/sec 1.14580 4
#> 4 2020-11-20 00:47:27 27.634 sec 26041 obs/sec 2.00380 7
#> 5 2020-11-20 00:47:37 38.130 sec 26919 obs/sec 2.86322 10
#> 6 2020-11-20 00:47:47 48.268 sec 27612 obs/sec 3.72185 13
#> 7 2020-11-20 00:47:58 58.391 sec 28070 obs/sec 4.57999 16
#> 8 2020-11-20 00:48:08 1 min 8.665 sec 28342 obs/sec 5.44094 19
#> 9 2020-11-20 00:48:18 1 min 18.808 sec 28589 obs/sec 6.30286 22
#> 10 2020-11-20 00:48:28 1 min 29.079 sec 28738 obs/sec 7.16387 25
#> 11 2020-11-20 00:48:39 1 min 39.471 sec 28814 obs/sec 8.02484 28
#> 12 2020-11-20 00:48:47 1 min 47.630 sec 28540 obs/sec 8.59717 30
#> 13 2020-11-20 00:48:58 1 min 58.814 sec 28428 obs/sec 9.45631 33
#> 14 2020-11-20 00:49:05 2 min 5.602 sec 28530 obs/sec 10.02933 35
#> samples training_rmse training_logloss training_r2
#> 1 0.000000 NA NA NA
#> 2 99715.000000 0.42091 0.54792 0.90389
#> 3 399903.000000 0.36110 0.40892 0.92926
#> 4 699355.000000 0.32465 0.33522 0.94282
#> 5 999306.000000 0.30337 0.29947 0.95007
#> 6 1298980.000000 0.28769 0.26896 0.95510
#> 7 1598486.000000 0.27389 0.24600 0.95930
#> 8 1898968.000000 0.26872 0.23760 0.96083
#> 9 2199794.000000 0.25677 0.21771 0.96423
#> 10 2500298.000000 0.25132 0.20910 0.96574
#> 11 2800789.000000 0.24956 0.20557 0.96621
#> 12 3000543.000000 0.23992 0.19289 0.96877
#> 13 3300393.000000 0.23879 0.18893 0.96907
#> 14 3500387.000000 0.23290 0.18055 0.97057
#> training_classification_error validation_rmse validation_logloss
#> 1 NA NA NA
#> 2 0.23414 0.42117 0.54686
#> 3 0.17446 0.36241 0.41089
#> 4 0.14544 0.33231 0.34976
#> 5 0.11864 0.31353 0.31560
#> 6 0.10738 0.29535 0.27967
#> 7 0.10058 0.28128 0.25850
#> 8 0.09540 0.27812 0.25019
#> 9 0.08901 0.26701 0.23320
#> 10 0.08140 0.26332 0.22801
#> 11 0.08566 0.25778 0.21911
#> 12 0.07734 0.24912 0.20497
#> 13 0.07592 0.25180 0.20628
#> 14 0.07389 0.24714 0.20143
#> validation_r2 validation_classification_error
#> 1 NA NA
#> 2 0.91352 0.23808
#> 3 0.93597 0.17575
#> 4 0.94616 0.15100
#> 5 0.95208 0.13176
#> 6 0.95747 0.11894
#> 7 0.96143 0.10762
#> 8 0.96229 0.10701
#> 9 0.96524 0.09409
#> 10 0.96620 0.09389
#> 11 0.96760 0.08868
#> 12 0.96974 0.08236
#> 13 0.96909 0.08617
#> 14 0.97022 0.08216
#>
#> Variable Importances: (Extract with `h2o.varimp`)
#> =================================================
#>
#> Variable Importances:
#> variable relative_importance scaled_importance
#> 1 Elevation 1.000000 1.000000
#> 2 Horizontal_Distance_To_Roadways 0.845648 0.845648
#> 3 Horizontal_Distance_To_Fire_Points 0.806406 0.806406
#> 4 Wilderness_Area.area_0 0.613771 0.613771
#> 5 Wilderness_Area.area_2 0.577823 0.577823
#> percentage
#> 1 0.051920
#> 2 0.043906
#> 3 0.041869
#> 4 0.031867
#> 5 0.030001
#>
#> ---
#> variable relative_importance scaled_importance percentage
#> 51 Soil_Type.type_17 0.143857 0.143857 0.007469
#> 52 Soil_Type.type_7 0.143357 0.143357 0.007443
#> 53 Soil_Type.type_14 0.142947 0.142947 0.007422
#> 54 Soil_Type.type_24 0.135752 0.135752 0.007048
#> 55 Soil_Type.missing(NA) 0.000000 0.000000 0.000000
#> 56 Wilderness_Area.missing(NA) 0.000000 0.000000 0.000000Let’s compare the training error with the validation and test set errors
h2o.performance(m3, train=T) ## sampled training data (from model building)
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on training data. **
#> ** Metrics reported on temporary training frame with 9853 samples **
#>
#> Training Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0542
#> RMSE: (Extract with `h2o.rmse`) 0.233
#> Logloss: (Extract with `h2o.logloss`) 0.181
#> Mean Per-Class Error: 0.116
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,train = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3414 219 0 0 3 0 18 0.0657
#> class_2 285 4487 7 0 12 4 2 0.0646
#> class_3 0 19 560 8 1 29 0 0.0924
#> class_4 0 0 1 42 0 1 0 0.0455
#> class_5 4 32 0 0 107 1 0 0.2569
#> class_6 0 18 45 0 0 215 0 0.2266
#> class_7 18 1 0 0 0 0 300 0.0596
#> Totals 3721 4776 613 50 123 250 320 0.0739
#> Rate
#> class_1 = 240 / 3,654
#> class_2 = 310 / 4,797
#> class_3 = 57 / 617
#> class_4 = 2 / 44
#> class_5 = 37 / 144
#> class_6 = 63 / 278
#> class_7 = 19 / 319
#> Totals = 728 / 9,853
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,train = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.926114
#> 2 2 0.996549
#> 3 3 0.999696
#> 4 4 1.000000
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
h2o.performance(m3, valid=T) ## sampled validation data (from model building)
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on temporary validation frame with 9980 samples **
#>
#> Validation Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0611
#> RMSE: (Extract with `h2o.rmse`) 0.247
#> Logloss: (Extract with `h2o.logloss`) 0.201
#> Mean Per-Class Error: 0.135
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3378 233 0 0 4 1 17 0.0702
#> class_2 307 4451 5 0 30 6 6 0.0737
#> class_3 1 12 547 12 1 34 0 0.0988
#> class_4 0 0 4 41 0 9 0 0.2407
#> class_5 2 22 0 0 142 1 0 0.1497
#> class_6 0 27 52 4 0 281 0 0.2280
#> class_7 29 1 0 0 0 0 320 0.0857
#> Totals 3717 4746 608 57 177 332 343 0.0822
#> Rate
#> class_1 = 255 / 3,633
#> class_2 = 354 / 4,805
#> class_3 = 60 / 607
#> class_4 = 13 / 54
#> class_5 = 25 / 167
#> class_6 = 83 / 364
#> class_7 = 30 / 350
#> Totals = 820 / 9,980
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.917836
#> 2 2 0.996293
#> 3 3 0.999800
#> 4 4 1.000000
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
h2o.performance(m3, newdata=train) ## full training data
#> H2OMultinomialMetrics: deeplearning
#>
#> Test Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0567
#> RMSE: (Extract with `h2o.rmse`) 0.238
#> Logloss: (Extract with `h2o.logloss`) 0.188
#> Mean Per-Class Error: 0.122
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>, <data>)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 118796 7547 1 0 120 58 598 0.0655
#> class_2 10285 158771 251 0 629 316 90 0.0679
#> class_3 2 646 19442 296 47 1009 0 0.0933
#> class_4 0 2 166 1435 0 55 0 0.1345
#> class_5 71 1084 87 0 4451 26 1 0.2219
#> class_6 12 504 1363 104 5 8445 0 0.1905
#> class_7 860 95 0 0 2 0 11343 0.0778
#> Totals 130026 168649 21310 1835 5254 9909 12032 0.0754
#> Rate
#> class_1 = 8,324 / 127,120
#> class_2 = 11,571 / 170,342
#> class_3 = 2,000 / 21,442
#> class_4 = 223 / 1,658
#> class_5 = 1,269 / 5,720
#> class_6 = 1,988 / 10,433
#> class_7 = 957 / 12,300
#> Totals = 26,332 / 349,015
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>, <data>)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.924553
#> 2 2 0.996662
#> 3 3 0.999811
#> 4 4 0.999966
#> 5 5 0.999997
#> 6 6 1.000000
#> 7 7 1.000000
h2o.performance(m3, newdata=valid) ## full validation data
#> H2OMultinomialMetrics: deeplearning
#>
#> Test Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0626
#> RMSE: (Extract with `h2o.rmse`) 0.25
#> Logloss: (Extract with `h2o.logloss`) 0.208
#> Mean Per-Class Error: 0.138
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>, <data>)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 39405 2809 2 0 55 15 214 0.0728
#> class_2 3684 52186 91 0 256 122 41 0.0744
#> class_3 5 257 6389 117 12 363 0 0.1056
#> class_4 0 0 59 473 0 30 0 0.1584
#> class_5 29 403 40 0 1388 10 0 0.2578
#> class_6 4 223 488 31 2 2716 0 0.2159
#> class_7 321 24 0 0 1 0 3753 0.0844
#> Totals 43448 55902 7069 621 1714 3256 4008 0.0837
#> Rate
#> class_1 = 3,095 / 42,500
#> class_2 = 4,194 / 56,380
#> class_3 = 754 / 7,143
#> class_4 = 89 / 562
#> class_5 = 482 / 1,870
#> class_6 = 748 / 3,464
#> class_7 = 346 / 4,099
#> Totals = 9,708 / 116,018
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>, <data>)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.916323
#> 2 2 0.995716
#> 3 3 0.999690
#> 4 4 0.999974
#> 5 5 0.999991
#> 6 6 1.000000
#> 7 7 1.000000
h2o.performance(m3, newdata=test) ## full test data
#> H2OMultinomialMetrics: deeplearning
#>
#> Test Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0623
#> RMSE: (Extract with `h2o.rmse`) 0.25
#> Logloss: (Extract with `h2o.logloss`) 0.207
#> Mean Per-Class Error: 0.132
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>, <data>)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 39222 2714 0 0 51 8 225 0.0710
#> class_2 3722 52326 109 1 227 148 46 0.0752
#> class_3 1 272 6437 124 18 317 0 0.1021
#> class_4 0 0 53 452 0 22 0 0.1423
#> class_5 24 397 29 0 1443 10 0 0.2417
#> class_6 2 186 480 35 2 2765 0 0.2032
#> class_7 345 31 0 0 1 0 3734 0.0917
#> Totals 43316 55926 7108 612 1742 3270 4005 0.0828
#> Rate
#> class_1 = 2,998 / 42,220
#> class_2 = 4,253 / 56,579
#> class_3 = 732 / 7,169
#> class_4 = 75 / 527
#> class_5 = 460 / 1,903
#> class_6 = 705 / 3,470
#> class_7 = 377 / 4,111
#> Totals = 9,600 / 115,979
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>, <data>)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.917226
#> 2 2 0.995499
#> 3 3 0.999664
#> 4 4 0.999957
#> 5 5 0.999991
#> 6 6 1.000000
#> 7 7 1.000000To confirm that the reported confusion matrix on the validation set (here, the test set) was correct, we make a prediction on the test set and compare the confusion matrices explicitly:
pred <- h2o.predict(m3, test)
#>
|
| | 0%
|
|======================================================================| 100%
pred
#> predict class_1 class_2 class_3 class_4 class_5 class_6 class_7
#> 1 class_1 7.67e-01 2.32e-01 3.62e-05 2.36e-05 1.01e-04 2.71e-05 4.81e-04
#> 2 class_1 9.99e-01 8.44e-04 2.48e-09 1.06e-08 1.01e-07 1.14e-10 1.74e-08
#> 3 class_1 1.00e+00 1.08e-06 2.41e-11 9.61e-13 3.16e-11 7.83e-09 7.40e-08
#> 4 class_1 9.99e-01 1.27e-03 8.51e-07 5.55e-09 2.91e-10 1.54e-07 2.17e-05
#> 5 class_2 2.58e-02 9.67e-01 2.39e-06 1.80e-07 6.60e-03 4.24e-04 1.70e-05
#> 6 class_2 2.14e-05 5.11e-01 4.43e-05 2.61e-09 4.89e-01 2.17e-07 9.74e-09
#>
#> [115979 rows x 8 columns]
test$Accuracy <- pred$predict == test$Cover_Type
1-mean(test$Accuracy)
#> [1] 0.082846.5.6 Hyper-parameter Tuning with Grid Search
Since there are a lot of parameters that can impact model accuracy, hyper-parameter tuning is especially important for Deep Learning:
For speed, we will only train on the first 10,000 rows of the training dataset:
sampled_train=train[1:10000,]The simplest hyperparameter search method is a brute-force scan of the full Cartesian product of all combinations specified by a grid search:
hyper_params <- list(
hidden=list(c(32,32,32),c(64,64)),
input_dropout_ratio=c(0,0.05),
rate=c(0.01,0.02),
rate_annealing=c(1e-8,1e-7,1e-6)
)
hyper_params
#> $hidden
#> $hidden[[1]]
#> [1] 32 32 32
#>
#> $hidden[[2]]
#> [1] 64 64
#>
#>
#> $input_dropout_ratio
#> [1] 0.00 0.05
#>
#> $rate
#> [1] 0.01 0.02
#>
#> $rate_annealing
#> [1] 1e-08 1e-07 1e-06
grid <- h2o.grid(
algorithm="deeplearning",
grid_id="dl_grid",
training_frame=sampled_train,
validation_frame=valid,
x=predictors,
y=response,
epochs=10,
stopping_metric="misclassification",
stopping_tolerance=1e-2, ## stop when misclassification does not improve by >=1% for 2 scoring events
stopping_rounds=2,
score_validation_samples=10000, ## downsample validation set for faster scoring
score_duty_cycle=0.025, ## don't score more than 2.5% of the wall time
adaptive_rate=F, ## manually tuned learning rate
momentum_start=0.5, ## manually tuned momentum
momentum_stable=0.9,
momentum_ramp=1e7,
l1=1e-5,
l2=1e-5,
activation=c("Rectifier"),
max_w2=10, ## can help improve stability for Rectifier
hyper_params=hyper_params
)
#>
|
| | 0%
|
|======================================================================| 100%
grid
#> H2O Grid Details
#> ================
#>
#> Grid ID: dl_grid
#> Used hyper parameters:
#> - hidden
#> - input_dropout_ratio
#> - rate
#> - rate_annealing
#> Number of models: 24
#> Number of failed models: 0
#>
#> Hyper-Parameter Search Summary: ordered by increasing logloss
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 1 [64, 64] 0.0 0.01 1.0E-7 dl_grid_model_10
#> 2 [64, 64] 0.0 0.01 1.0E-8 dl_grid_model_2
#> 3 [64, 64] 0.0 0.01 1.0E-6 dl_grid_model_18
#> 4 [64, 64] 0.0 0.02 1.0E-8 dl_grid_model_6
#> 5 [64, 64] 0.05 0.02 1.0E-7 dl_grid_model_16
#> logloss
#> 1 0.5546777038299052
#> 2 0.561723243566788
#> 3 0.5703110009036815
#> 4 0.5766211363933275
#> 5 0.5766301225510833
#>
#> ---
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 19 [32, 32, 32] 0.05 0.02 1.0E-8 dl_grid_model_7
#> 20 [32, 32, 32] 0.05 0.02 1.0E-6 dl_grid_model_23
#> 21 [64, 64] 0.0 0.02 1.0E-7 dl_grid_model_14
#> 22 [64, 64] 0.05 0.02 1.0E-8 dl_grid_model_8
#> 23 [32, 32, 32] 0.0 0.02 1.0E-8 dl_grid_model_5
#> 24 [32, 32, 32] 0.0 0.01 1.0E-6 dl_grid_model_17
#> logloss
#> 19 0.6212765978773134
#> 20 0.6375004485315976
#> 21 0.6391900652964455
#> 22 0.6442429274125692
#> 23 0.6459711748312551
#> 24 0.6812551946441254Let’s see which model had the lowest validation error:
grid <- h2o.getGrid("dl_grid",sort_by="err",decreasing=FALSE)
grid
#> H2O Grid Details
#> ================
#>
#> Grid ID: dl_grid
#> Used hyper parameters:
#> - hidden
#> - input_dropout_ratio
#> - rate
#> - rate_annealing
#> Number of models: 24
#> Number of failed models: 0
#>
#> Hyper-Parameter Search Summary: ordered by increasing err
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 1 [64, 64] 0.0 0.01 1.0E-7 dl_grid_model_10
#> 2 [64, 64] 0.0 0.01 1.0E-6 dl_grid_model_18
#> 3 [64, 64] 0.0 0.02 1.0E-8 dl_grid_model_6
#> 4 [64, 64] 0.0 0.01 1.0E-8 dl_grid_model_2
#> 5 [64, 64] 0.0 0.02 1.0E-6 dl_grid_model_22
#> err
#> 1 0.24202739178246527
#> 2 0.2456545765095951
#> 3 0.2458638323473378
#> 4 0.24802717011287584
#> 5 0.24890612569610182
#>
#> ---
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 19 [64, 64] 0.05 0.02 1.0E-7 dl_grid_model_16
#> 20 [64, 64] 0.05 0.01 1.0E-6 dl_grid_model_20
#> 21 [32, 32, 32] 0.05 0.02 1.0E-6 dl_grid_model_23
#> 22 [32, 32, 32] 0.0 0.02 1.0E-8 dl_grid_model_5
#> 23 [64, 64] 0.05 0.02 1.0E-8 dl_grid_model_8
#> 24 [32, 32, 32] 0.0 0.01 1.0E-6 dl_grid_model_17
#> err
#> 19 0.2705517172324021
#> 20 0.27265469061876246
#> 21 0.27676707426185504
#> 22 0.277966440271674
#> 23 0.2797343529885289
#> 24 0.28279912402946444
## To see what other "sort_by" criteria are allowed
#grid <- h2o.getGrid("dl_grid",sort_by="wrong_thing",decreasing=FALSE)
## Sort by logloss
h2o.getGrid("dl_grid",sort_by="logloss",decreasing=FALSE)
#> H2O Grid Details
#> ================
#>
#> Grid ID: dl_grid
#> Used hyper parameters:
#> - hidden
#> - input_dropout_ratio
#> - rate
#> - rate_annealing
#> Number of models: 24
#> Number of failed models: 0
#>
#> Hyper-Parameter Search Summary: ordered by increasing logloss
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 1 [64, 64] 0.0 0.01 1.0E-7 dl_grid_model_10
#> 2 [64, 64] 0.0 0.01 1.0E-8 dl_grid_model_2
#> 3 [64, 64] 0.0 0.01 1.0E-6 dl_grid_model_18
#> 4 [64, 64] 0.0 0.02 1.0E-8 dl_grid_model_6
#> 5 [64, 64] 0.05 0.02 1.0E-7 dl_grid_model_16
#> logloss
#> 1 0.5546777038299052
#> 2 0.561723243566788
#> 3 0.5703110009036815
#> 4 0.5766211363933275
#> 5 0.5766301225510833
#>
#> ---
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 19 [32, 32, 32] 0.05 0.02 1.0E-8 dl_grid_model_7
#> 20 [32, 32, 32] 0.05 0.02 1.0E-6 dl_grid_model_23
#> 21 [64, 64] 0.0 0.02 1.0E-7 dl_grid_model_14
#> 22 [64, 64] 0.05 0.02 1.0E-8 dl_grid_model_8
#> 23 [32, 32, 32] 0.0 0.02 1.0E-8 dl_grid_model_5
#> 24 [32, 32, 32] 0.0 0.01 1.0E-6 dl_grid_model_17
#> logloss
#> 19 0.6212765978773134
#> 20 0.6375004485315976
#> 21 0.6391900652964455
#> 22 0.6442429274125692
#> 23 0.6459711748312551
#> 24 0.6812551946441254
## Find the best model and its full set of parameters
grid@summary_table[1,]
#> Hyper-Parameter Search Summary: ordered by increasing err
#> hidden input_dropout_ratio rate rate_annealing model_ids
#> 1 [64, 64] 0.0 0.01 1.0E-7 dl_grid_model_10
#> err
#> 1 0.24202739178246527
best_model <- h2o.getModel(grid@model_ids[[1]])
best_model
#> Model Details:
#> ==============
#>
#> H2OMultinomialModel: deeplearning
#> Model ID: dl_grid_model_10
#> Status of Neuron Layers: predicting Cover_Type, 7-class classification, multinomial distribution, CrossEntropy loss, 8,263 weights/biases, 72.2 KB, 100,000 training samples, mini-batch size 1
#> layer units type dropout l1 l2 mean_rate rate_rms momentum
#> 1 1 56 Input 0.00 % NA NA NA NA NA
#> 2 2 64 Rectifier 0.00 % 0.000010 0.000010 0.009901 0.000000 0.504000
#> 3 3 64 Rectifier 0.00 % 0.000010 0.000010 0.009901 0.000000 0.504000
#> 4 4 7 Softmax NA 0.000010 0.000010 0.009901 0.000000 0.504000
#> mean_weight weight_rms mean_bias bias_rms
#> 1 NA NA NA NA
#> 2 -0.013262 0.211380 0.184134 0.174737
#> 3 -0.064339 0.188289 0.874184 0.139451
#> 4 -0.007710 0.393877 -0.000827 0.599978
#>
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on training data. **
#> ** Metrics reported on full training frame **
#>
#> Training Set Metrics:
#> =====================
#>
#> Extract training frame with `h2o.getFrame("RTMP_sid_9717_9")`
#> MSE: (Extract with `h2o.mse`) 0.162
#> RMSE: (Extract with `h2o.rmse`) 0.402
#> Logloss: (Extract with `h2o.logloss`) 0.503
#> Mean Per-Class Error: 0.44
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,train = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 2718 879 2 0 0 0 89 0.2630
#> class_2 630 4108 75 0 0 17 5 0.1504
#> class_3 1 38 584 1 0 6 0 0.0730
#> class_4 0 0 34 10 0 0 0 0.7727
#> class_5 15 113 6 0 22 0 0 0.8590
#> class_6 0 61 179 0 0 69 0 0.7767
#> class_7 61 1 0 0 0 0 276 0.1834
#> Totals 3425 5200 880 11 22 92 370 0.2213
#> Rate
#> class_1 = 970 / 3,688
#> class_2 = 727 / 4,835
#> class_3 = 46 / 630
#> class_4 = 34 / 44
#> class_5 = 134 / 156
#> class_6 = 240 / 309
#> class_7 = 62 / 338
#> Totals = 2,213 / 10,000
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,train = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.778700
#> 2 2 0.981500
#> 3 3 0.997000
#> 4 4 0.999500
#> 5 5 0.999900
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on temporary validation frame with 10003 samples **
#>
#> Validation Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.177
#> RMSE: (Extract with `h2o.rmse`) 0.421
#> Logloss: (Extract with `h2o.logloss`) 0.555
#> Mean Per-Class Error: 0.479
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 2569 988 0 0 0 1 85 0.2948
#> class_2 692 4113 54 0 0 22 4 0.1580
#> class_3 0 46 540 1 0 9 0 0.0940
#> class_4 0 2 36 8 0 0 0 0.8261
#> class_5 9 147 0 0 16 1 0 0.9075
#> class_6 0 56 178 0 0 45 0 0.8387
#> class_7 89 1 0 0 0 0 291 0.2362
#> Totals 3359 5353 808 9 16 78 380 0.2420
#> Rate
#> class_1 = 1,074 / 3,643
#> class_2 = 772 / 4,885
#> class_3 = 56 / 596
#> class_4 = 38 / 46
#> class_5 = 157 / 173
#> class_6 = 234 / 279
#> class_7 = 90 / 381
#> Totals = 2,421 / 10,003
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.757973
#> 2 2 0.974708
#> 3 3 0.997001
#> 4 4 0.999200
#> 5 5 0.999900
#> 6 6 1.000000
#> 7 7 1.000000
print(best_model@allparameters)
#> $model_id
#> [1] "dl_grid_model_10"
#>
#> $training_frame
#> [1] "RTMP_sid_9717_9"
#>
#> $validation_frame
#> [1] "valid.hex"
#>
#> $nfolds
#> [1] 0
#>
#> $keep_cross_validation_models
#> [1] TRUE
#>
#> $keep_cross_validation_predictions
#> [1] FALSE
#>
#> $keep_cross_validation_fold_assignment
#> [1] FALSE
#>
#> $fold_assignment
#> [1] "AUTO"
#>
#> $ignore_const_cols
#> [1] TRUE
#>
#> $score_each_iteration
#> [1] FALSE
#>
#> $balance_classes
#> [1] FALSE
#>
#> $max_after_balance_size
#> [1] 5
#>
#> $max_confusion_matrix_size
#> [1] 20
#>
#> $max_hit_ratio_k
#> [1] 0
#>
#> $overwrite_with_best_model
#> [1] TRUE
#>
#> $use_all_factor_levels
#> [1] TRUE
#>
#> $standardize
#> [1] TRUE
#>
#> $activation
#> [1] "Rectifier"
#>
#> $hidden
#> [1] 64 64
#>
#> $epochs
#> [1] 10
#>
#> $train_samples_per_iteration
#> [1] -2
#>
#> $target_ratio_comm_to_comp
#> [1] 0.05
#>
#> $seed
#> [1] "1840239639861217278"
#>
#> $adaptive_rate
#> [1] FALSE
#>
#> $rho
#> [1] 0.99
#>
#> $epsilon
#> [1] 1e-08
#>
#> $rate
#> [1] 0.01
#>
#> $rate_annealing
#> [1] 1e-07
#>
#> $rate_decay
#> [1] 1
#>
#> $momentum_start
#> [1] 0.5
#>
#> $momentum_ramp
#> [1] 1e+07
#>
#> $momentum_stable
#> [1] 0.9
#>
#> $nesterov_accelerated_gradient
#> [1] TRUE
#>
#> $input_dropout_ratio
#> [1] 0
#>
#> $l1
#> [1] 1e-05
#>
#> $l2
#> [1] 1e-05
#>
#> $max_w2
#> [1] 10
#>
#> $initial_weight_distribution
#> [1] "UniformAdaptive"
#>
#> $initial_weight_scale
#> [1] 1
#>
#> $loss
#> [1] "Automatic"
#>
#> $distribution
#> [1] "AUTO"
#>
#> $quantile_alpha
#> [1] 0.5
#>
#> $tweedie_power
#> [1] 1.5
#>
#> $huber_alpha
#> [1] 0.9
#>
#> $score_interval
#> [1] 5
#>
#> $score_training_samples
#> [1] 10000
#>
#> $score_validation_samples
#> [1] 10000
#>
#> $score_duty_cycle
#> [1] 0.025
#>
#> $classification_stop
#> [1] 0
#>
#> $regression_stop
#> [1] 1e-06
#>
#> $stopping_rounds
#> [1] 2
#>
#> $stopping_metric
#> [1] "misclassification"
#>
#> $stopping_tolerance
#> [1] 0.01
#>
#> $max_runtime_secs
#> [1] 1.8e+308
#>
#> $score_validation_sampling
#> [1] "Uniform"
#>
#> $diagnostics
#> [1] TRUE
#>
#> $fast_mode
#> [1] TRUE
#>
#> $force_load_balance
#> [1] TRUE
#>
#> $variable_importances
#> [1] TRUE
#>
#> $replicate_training_data
#> [1] TRUE
#>
#> $single_node_mode
#> [1] FALSE
#>
#> $shuffle_training_data
#> [1] FALSE
#>
#> $missing_values_handling
#> [1] "MeanImputation"
#>
#> $quiet_mode
#> [1] FALSE
#>
#> $autoencoder
#> [1] FALSE
#>
#> $sparse
#> [1] FALSE
#>
#> $col_major
#> [1] FALSE
#>
#> $average_activation
#> [1] 0
#>
#> $sparsity_beta
#> [1] 0
#>
#> $max_categorical_features
#> [1] 2147483647
#>
#> $reproducible
#> [1] FALSE
#>
#> $export_weights_and_biases
#> [1] FALSE
#>
#> $mini_batch_size
#> [1] 1
#>
#> $categorical_encoding
#> [1] "AUTO"
#>
#> $elastic_averaging
#> [1] FALSE
#>
#> $elastic_averaging_moving_rate
#> [1] 0.9
#>
#> $elastic_averaging_regularization
#> [1] 0.001
#>
#> $x
#> [1] "Soil_Type" "Wilderness_Area"
#> [3] "Elevation" "Aspect"
#> [5] "Slope" "Horizontal_Distance_To_Hydrology"
#> [7] "Vertical_Distance_To_Hydrology" "Horizontal_Distance_To_Roadways"
#> [9] "Hillshade_9am" "Hillshade_Noon"
#> [11] "Hillshade_3pm" "Horizontal_Distance_To_Fire_Points"
#>
#> $y
#> [1] "Cover_Type"
print(h2o.performance(best_model, valid=T))
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on temporary validation frame with 10003 samples **
#>
#> Validation Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.177
#> RMSE: (Extract with `h2o.rmse`) 0.421
#> Logloss: (Extract with `h2o.logloss`) 0.555
#> Mean Per-Class Error: 0.479
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 2569 988 0 0 0 1 85 0.2948
#> class_2 692 4113 54 0 0 22 4 0.1580
#> class_3 0 46 540 1 0 9 0 0.0940
#> class_4 0 2 36 8 0 0 0 0.8261
#> class_5 9 147 0 0 16 1 0 0.9075
#> class_6 0 56 178 0 0 45 0 0.8387
#> class_7 89 1 0 0 0 0 291 0.2362
#> Totals 3359 5353 808 9 16 78 380 0.2420
#> Rate
#> class_1 = 1,074 / 3,643
#> class_2 = 772 / 4,885
#> class_3 = 56 / 596
#> class_4 = 38 / 46
#> class_5 = 157 / 173
#> class_6 = 234 / 279
#> class_7 = 90 / 381
#> Totals = 2,421 / 10,003
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.757973
#> 2 2 0.974708
#> 3 3 0.997001
#> 4 4 0.999200
#> 5 5 0.999900
#> 6 6 1.000000
#> 7 7 1.000000
print(h2o.logloss(best_model, valid=T))
#> [1] 0.55546.5.7 Random Hyper-Parameter Search
Often, hyper-parameter search for more than 4 parameters can be done more efficiently with random parameter search than with grid search. Basically, chances are good to find one of many good models in less time than performing an exhaustive grid search. We simply build up to max_models models with parameters drawn randomly from user-specified distributions (here, uniform). For this example, we use the adaptive learning rate and focus on tuning the network architecture and the regularization parameters. We also let the grid search stop automatically once the performance at the top of the leaderboard doesn’t change much anymore, i.e., once the search has converged.
hyper_params <- list(
activation=c("Rectifier","Tanh","Maxout","RectifierWithDropout","TanhWithDropout","MaxoutWithDropout"),
hidden=list(c(20,20),c(50,50),c(30,30,30),c(25,25,25,25)),
input_dropout_ratio=c(0,0.05),
l1=seq(0,1e-4,1e-6),
l2=seq(0,1e-4,1e-6)
)
hyper_params
## Stop once the top 5 models are within 1% of each other (i.e., the windowed average varies less than 1%)
search_criteria = list(strategy = "RandomDiscrete", max_runtime_secs = 360, max_models = 100, seed=1234567, stopping_rounds=5, stopping_tolerance=1e-2)
dl_random_grid <- h2o.grid(
algorithm="deeplearning",
grid_id = "dl_grid_random",
training_frame=sampled_train,
validation_frame=valid,
x=predictors,
y=response,
epochs=1,
stopping_metric="logloss",
stopping_tolerance=1e-2, ## stop when logloss does not improve by >=1% for 2 scoring events
stopping_rounds=2,
score_validation_samples=10000, ## downsample validation set for faster scoring
score_duty_cycle=0.025, ## don't score more than 2.5% of the wall time
max_w2=10, ## can help improve stability for Rectifier
hyper_params = hyper_params,
search_criteria = search_criteria
)
grid <- h2o.getGrid("dl_grid_random",sort_by="logloss",decreasing=FALSE)
grid
grid@summary_table[1,]
best_model <- h2o.getModel(grid@model_ids[[1]]) ## model with lowest logloss
best_modelLet’s look at the model with the lowest validation misclassification rate:
grid <- h2o.getGrid("dl_grid",sort_by="err",decreasing=FALSE)
best_model <- h2o.getModel(grid@model_ids[[1]]) ## model with lowest classification error (on validation, since it was available during training)
h2o.confusionMatrix(best_model,valid=T)
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 2569 988 0 0 0 1 85 0.2948
#> class_2 692 4113 54 0 0 22 4 0.1580
#> class_3 0 46 540 1 0 9 0 0.0940
#> class_4 0 2 36 8 0 0 0 0.8261
#> class_5 9 147 0 0 16 1 0 0.9075
#> class_6 0 56 178 0 0 45 0 0.8387
#> class_7 89 1 0 0 0 0 291 0.2362
#> Totals 3359 5353 808 9 16 78 380 0.2420
#> Rate
#> class_1 = 1,074 / 3,643
#> class_2 = 772 / 4,885
#> class_3 = 56 / 596
#> class_4 = 38 / 46
#> class_5 = 157 / 173
#> class_6 = 234 / 279
#> class_7 = 90 / 381
#> Totals = 2,421 / 10,003
best_params <- best_model@allparameters
best_params$activation
#> [1] "Rectifier"
best_params$hidden
#> [1] 64 64
best_params$input_dropout_ratio
#> [1] 0
best_params$l1
#> [1] 1e-05
best_params$l2
#> [1] 1e-0546.5.8 Checkpointing
Let’s continue training the manually tuned model from before, for 2 more epochs. Note that since many important parameters such as epochs, l1, l2, max_w2, score_interval, train_samples_per_iteration, input_dropout_ratio, hidden_dropout_ratios, score_duty_cycle, classification_stop, regression_stop, variable_importances, force_load_balance can be modified between checkpoint restarts, it is best to specify as many parameters as possible explicitly.
max_epochs <- 12 ## Add two more epochs
m_cont <- h2o.deeplearning(
model_id="dl_model_tuned_continued",
checkpoint="dl_model_tuned",
training_frame=train,
validation_frame=valid,
x=predictors,
y=response,
hidden=c(128,128,128), ## more hidden layers -> more complex interactions
epochs=max_epochs, ## hopefully long enough to converge (otherwise restart again)
stopping_metric="logloss", ## logloss is directly optimized by Deep Learning
stopping_tolerance=1e-2, ## stop when validation logloss does not improve by >=1% for 2 scoring events
stopping_rounds=2,
score_validation_samples=10000, ## downsample validation set for faster scoring
score_duty_cycle=0.025, ## don't score more than 2.5% of the wall time
adaptive_rate=F, ## manually tuned learning rate
rate=0.01,
rate_annealing=2e-6,
momentum_start=0.2, ## manually tuned momentum
momentum_stable=0.4,
momentum_ramp=1e7,
l1=1e-5, ## add some L1/L2 regularization
l2=1e-5,
max_w2=10 ## helps stability for Rectifier
)
summary(m_cont)
plot(m_cont)
Once we are satisfied with the results, we can save the model to disk (on the cluster). In this example, we store the model in a directory called mybest_deeplearning_covtype_model, which will be created for us since force=TRUE.
path <- h2o.saveModel(m_cont,
path = file.path(data_out_dir, "mybest_deeplearning_covtype_model"), force=TRUE)It can be loaded later with the following command:
print(path)
#> [1] "/home/rstudio/all/output/data/mybest_deeplearning_covtype_model/dl_model_tuned_continued"
m_loaded <- h2o.loadModel(path)
summary(m_loaded)
#> Model Details:
#> ==============
#>
#> H2OMultinomialModel: deeplearning
#> Model Key: dl_model_tuned_continued
#> Status of Neuron Layers: predicting Cover_Type, 7-class classification, multinomial distribution, CrossEntropy loss, 41,223 weights/biases, 333.0 KB, 3,600,182 training samples, mini-batch size 1
#> layer units type dropout l1 l2 mean_rate rate_rms momentum
#> 1 1 56 Input 0.00 % NA NA NA NA NA
#> 2 2 128 Rectifier 0.00 % 0.000010 0.000010 0.001219 0.000000 0.272004
#> 3 3 128 Rectifier 0.00 % 0.000010 0.000010 0.001219 0.000000 0.272004
#> 4 4 128 Rectifier 0.00 % 0.000010 0.000010 0.001219 0.000000 0.272004
#> 5 5 7 Softmax NA 0.000010 0.000010 0.001219 0.000000 0.272004
#> mean_weight weight_rms mean_bias bias_rms
#> 1 NA NA NA NA
#> 2 -0.012577 0.312181 0.023897 0.327174
#> 3 -0.058654 0.222585 0.835404 0.353978
#> 4 -0.057502 0.216801 0.801143 0.205884
#> 5 -0.033170 0.269806 0.003331 0.833177
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on training data. **
#> ** Metrics reported on temporary training frame with 9930 samples **
#>
#> Training Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0545
#> RMSE: (Extract with `h2o.rmse`) 0.233
#> Logloss: (Extract with `h2o.logloss`) 0.182
#> Mean Per-Class Error: 0.127
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,train = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3367 200 0 0 6 3 22 0.0642
#> class_2 285 4507 6 0 15 10 4 0.0663
#> class_3 0 16 596 5 1 28 0 0.0774
#> class_4 0 0 9 35 0 0 0 0.2045
#> class_5 2 26 5 0 126 0 0 0.2075
#> class_6 0 21 40 1 0 247 0 0.2006
#> class_7 23 1 0 0 0 0 323 0.0692
#> Totals 3677 4771 656 41 148 288 349 0.0734
#> Rate
#> class_1 = 231 / 3,598
#> class_2 = 320 / 4,827
#> class_3 = 50 / 646
#> class_4 = 9 / 44
#> class_5 = 33 / 159
#> class_6 = 62 / 309
#> class_7 = 24 / 347
#> Totals = 729 / 9,930
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,train = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.926586
#> 2 2 0.996375
#> 3 3 0.999698
#> 4 4 0.999899
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#> H2OMultinomialMetrics: deeplearning
#> ** Reported on validation data. **
#> ** Metrics reported on temporary validation frame with 9882 samples **
#>
#> Validation Set Metrics:
#> =====================
#>
#> MSE: (Extract with `h2o.mse`) 0.0638
#> RMSE: (Extract with `h2o.rmse`) 0.253
#> Logloss: (Extract with `h2o.logloss`) 0.212
#> Mean Per-Class Error: 0.136
#> Confusion Matrix: Extract with `h2o.confusionMatrix(<model>,valid = TRUE)`)
#> =========================================================================
#> Confusion Matrix: Row labels: Actual class; Column labels: Predicted class
#> class_1 class_2 class_3 class_4 class_5 class_6 class_7 Error
#> class_1 3331 230 0 0 2 4 21 0.0716
#> class_2 307 4446 13 0 21 10 8 0.0747
#> class_3 0 23 562 11 0 28 0 0.0994
#> class_4 0 0 6 40 0 0 0 0.1304
#> class_5 1 31 3 0 130 2 0 0.2216
#> class_6 0 27 56 2 0 230 0 0.2698
#> class_7 26 3 0 0 0 0 308 0.0861
#> Totals 3665 4760 640 53 153 274 337 0.0845
#> Rate
#> class_1 = 257 / 3,588
#> class_2 = 359 / 4,805
#> class_3 = 62 / 624
#> class_4 = 6 / 46
#> class_5 = 37 / 167
#> class_6 = 85 / 315
#> class_7 = 29 / 337
#> Totals = 835 / 9,882
#>
#> Hit Ratio Table: Extract with `h2o.hit_ratio_table(<model>,valid = TRUE)`
#> =======================================================================
#> Top-7 Hit Ratios:
#> k hit_ratio
#> 1 1 0.915503
#> 2 2 0.995750
#> 3 3 0.999696
#> 4 4 1.000000
#> 5 5 1.000000
#> 6 6 1.000000
#> 7 7 1.000000
#>
#>
#>
#>
#> Scoring History:
#> timestamp duration training_speed epochs iterations
#> 1 2020-11-20 00:46:59 0.000 sec NA 0.00000 0
#> 2 2020-11-20 00:47:04 5.374 sec 19667 obs/sec 0.28570 1
#> 3 2020-11-20 00:47:16 17.004 sec 24298 obs/sec 1.14580 4
#> 4 2020-11-20 00:47:27 27.634 sec 26041 obs/sec 2.00380 7
#> 5 2020-11-20 00:47:37 38.130 sec 26919 obs/sec 2.86322 10
#> 6 2020-11-20 00:47:47 48.268 sec 27612 obs/sec 3.72185 13
#> 7 2020-11-20 00:47:58 58.391 sec 28070 obs/sec 4.57999 16
#> 8 2020-11-20 00:48:08 1 min 8.665 sec 28342 obs/sec 5.44094 19
#> 9 2020-11-20 00:48:18 1 min 18.808 sec 28589 obs/sec 6.30286 22
#> 10 2020-11-20 00:48:28 1 min 29.079 sec 28738 obs/sec 7.16387 25
#> 11 2020-11-20 00:48:39 1 min 39.471 sec 28814 obs/sec 8.02484 28
#> 12 2020-11-20 00:48:47 1 min 47.630 sec 28540 obs/sec 8.59717 30
#> 13 2020-11-20 00:48:58 1 min 58.814 sec 28428 obs/sec 9.45631 33
#> 14 2020-11-20 00:49:05 2 min 5.602 sec 28530 obs/sec 10.02933 35
#> 15 2020-11-20 00:50:13 2 min 9.147 sec 28572 obs/sec 10.31526 36
#> 16 2020-11-20 00:50:13 2 min 9.345 sec 28571 obs/sec 10.31526 36
#> samples training_rmse training_logloss training_r2
#> 1 0.000000 NA NA NA
#> 2 99715.000000 0.42091 0.54792 0.90389
#> 3 399903.000000 0.36110 0.40892 0.92926
#> 4 699355.000000 0.32465 0.33522 0.94282
#> 5 999306.000000 0.30337 0.29947 0.95007
#> 6 1298980.000000 0.28769 0.26896 0.95510
#> 7 1598486.000000 0.27389 0.24600 0.95930
#> 8 1898968.000000 0.26872 0.23760 0.96083
#> 9 2199794.000000 0.25677 0.21771 0.96423
#> 10 2500298.000000 0.25132 0.20910 0.96574
#> 11 2800789.000000 0.24956 0.20557 0.96621
#> 12 3000543.000000 0.23992 0.19289 0.96877
#> 13 3300393.000000 0.23879 0.18893 0.96907
#> 14 3500387.000000 0.23290 0.18055 0.97057
#> 15 3600182.000000 0.23164 0.17838 0.97259
#> 16 3600182.000000 0.23348 0.18200 0.97215
#> training_classification_error validation_rmse validation_logloss
#> 1 NA NA NA
#> 2 0.23414 0.42117 0.54686
#> 3 0.17446 0.36241 0.41089
#> 4 0.14544 0.33231 0.34976
#> 5 0.11864 0.31353 0.31560
#> 6 0.10738 0.29535 0.27967
#> 7 0.10058 0.28128 0.25850
#> 8 0.09540 0.27812 0.25019
#> 9 0.08901 0.26701 0.23320
#> 10 0.08140 0.26332 0.22801
#> 11 0.08566 0.25778 0.21911
#> 12 0.07734 0.24912 0.20497
#> 13 0.07592 0.25180 0.20628
#> 14 0.07389 0.24714 0.20143
#> 15 0.07301 0.24964 0.20878
#> 16 0.07341 0.25264 0.21220
#> validation_r2 validation_classification_error
#> 1 NA NA
#> 2 0.91352 0.23808
#> 3 0.93597 0.17575
#> 4 0.94616 0.15100
#> 5 0.95208 0.13176
#> 6 0.95747 0.11894
#> 7 0.96143 0.10762
#> 8 0.96229 0.10701
#> 9 0.96524 0.09409
#> 10 0.96620 0.09389
#> 11 0.96760 0.08868
#> 12 0.96974 0.08236
#> 13 0.96909 0.08617
#> 14 0.97022 0.08216
#> 15 0.96814 0.08187
#> 16 0.96737 0.08450
#>
#> Variable Importances: (Extract with `h2o.varimp`)
#> =================================================
#>
#> Variable Importances:
#> variable relative_importance scaled_importance
#> 1 Elevation 1.000000 1.000000
#> 2 Horizontal_Distance_To_Roadways 0.845648 0.845648
#> 3 Horizontal_Distance_To_Fire_Points 0.806406 0.806406
#> 4 Wilderness_Area.area_0 0.613771 0.613771
#> 5 Wilderness_Area.area_2 0.577823 0.577823
#> percentage
#> 1 0.051920
#> 2 0.043906
#> 3 0.041869
#> 4 0.031867
#> 5 0.030001
#>
#> ---
#> variable relative_importance scaled_importance percentage
#> 51 Soil_Type.type_17 0.143857 0.143857 0.007469
#> 52 Soil_Type.type_7 0.143357 0.143357 0.007443
#> 53 Soil_Type.type_14 0.142947 0.142947 0.007422
#> 54 Soil_Type.type_24 0.135752 0.135752 0.007048
#> 55 Soil_Type.missing(NA) 0.000000 0.000000 0.000000
#> 56 Wilderness_Area.missing(NA) 0.000000 0.000000 0.000000This model is fully functional and can be inspected, restarted, or used to score a dataset, etc. Note that binary compatibility between H2O versions is currently not guaranteed.
46.5.9 Cross-Validation
For N-fold cross-validation, specify nfolds>1 instead of (or in addition to) a validation frame, and N+1 models will be built: 1 model on the full training data, and N models with each 1/N-th of the data held out (there are different holdout strategies). Those N models then score on the held out data, and their combined predictions on the full training data are scored to get the cross-validation metrics.
dlmodel <- h2o.deeplearning(
x=predictors,
y=response,
training_frame=train,
hidden=c(10,10),
epochs=1,
nfolds=5,
fold_assignment="Modulo" # can be "AUTO", "Modulo", "Random" or "Stratified"
)
dlmodelN-fold cross-validation is especially useful with early stopping, as the main model will pick the ideal number of epochs from the convergence behavior of the cross-validation models.
46.6 Regression and Binary Classification
Assume we want to turn the multi-class problem above into a binary classification problem. We create a binary response as follows:
train$bin_response <- ifelse(train[,response] == "class_1", 0, 1)Let’s build a quick model and inspect the model:
dlmodel <- h2o.deeplearning(
x=predictors,
y="bin_response",
training_frame=train,
hidden=c(10,10),
epochs=0.1
)
summary(dlmodel)Instead of a binary classification model, we find a regression model (H2ORegressionModel) that contains only 1 output neuron (instead of 2). The reason is that the response was a numerical feature (ordinal numbers 0 and 1), and H2O Deep Learning was run with distribution=AUTO, which defaulted to a Gaussian regression problem for a real-valued response. H2O Deep Learning supports regression for distributions other than Gaussian such as Poisson, Gamma, Tweedie, Laplace. It also supports Huber loss and per-row offsets specified via an offset_column. We refer to our H2O Deep Learning regression code examples for more information.
To perform classification, the response must first be turned into a categorical (factor) feature:
train$bin_response <- as.factor(train$bin_response) ##make categorical
dlmodel <- h2o.deeplearning(
x=predictors,
y="bin_response",
training_frame=train,
hidden=c(10,10),
epochs=0.1
#balance_classes=T ## enable this for high class imbalance
)
summary(dlmodel) ## Now the model metrics contain AUC for binary classification
plot(h2o.performance(dlmodel)) ## display ROC curve
Now the model performs (binary) classification, and has multiple (2) output neurons.
46.7 Unsupervised Anomaly detection
For instructions on how to build unsupervised models with H2O Deep Learning, we refer to our previous Tutorial on Anomaly Detection with H2O Deep Learning and our MNIST Anomaly detection code example, as well as our Stacked AutoEncoder R code example and another one for Unsupervised Pretraining with an AutoEncoder R code example.
46.8 H2O Deep Learning Tips & Tricks
46.8.1 Performance Tuning
The Definitive H2O Deep Learning Performance Tuning blog post covers many of the following points that affect the computational efficiency, so it’s highly recommended.
46.8.2 Activation Functions
While sigmoids have been used historically for neural networks, H2O Deep Learning implements Tanh, a scaled and shifted variant of the sigmoid which is symmetric around 0. Since its output values are bounded by -1..1, the stability of the neural network is rarely endangered. However, the derivative of the tanh function is always non-zero and back-propagation (training) of the weights is more computationally expensive than for rectified linear units, or Rectifier, which is max(0,x) and has vanishing gradient for x<=0, leading to much faster training speed for large networks and is often the fastest path to accuracy on larger problems. In case you encounter instabilities with the Rectifier (in which case model building is automatically aborted), try a limited value to re-scale the weights: max_w2=10. The Maxout activation function is computationally more expensive, but can lead to higher accuracy. It is a generalized version of the Rectifier with two non-zero channels. In practice, the Rectifier (and RectifierWithDropout, see below) is the most versatile and performant option for most problems.
46.8.3 Generalization Techniques
L1 and L2 penalties can be applied by specifying the l1 and l2 parameters. Intuition: L1 lets only strong weights survive (constant pulling force towards zero), while L2 prevents any single weight from getting too big. Dropout has recently been introduced as a powerful generalization technique, and is available as a parameter per layer, including the input layer. input_dropout_ratio controls the amount of input layer neurons that are randomly dropped (set to zero), while hidden_dropout_ratios are specified for each hidden layer. The former controls overfitting with respect to the input data (useful for high-dimensional noisy data), while the latter controls overfitting of the learned features. Note that hidden_dropout_ratios require the activation function to end with …WithDropout.
46.8.4 Early stopping and optimizing for lowest validation error
By default, Deep Learning training stops when the stopping_metric does not improve by at least stopping_tolerance (0.01 means 1% improvement) for stopping_rounds consecutive scoring events on the training (or validation) data. By default, overwrite_with_best_model is enabled and the model returned after training for the specified number of epochs (or after stopping early due to convergence) is the model that has the best training set error (according to the metric specified by stopping_metric), or, if a validation set is provided, the lowest validation set error. Note that the training or validation set errors can be based on a subset of the training or validation data, depending on the values for score_validation_samples or score_training_samples, see below. For early stopping on a predefined error rate on the training data (accuracy for classification or MSE for regression), specify classification_stop or regression_stop.
46.8.5 Training Samples per MapReduce Iteration
The parameter train_samples_per_iteration matters especially in multi-node operation. It controls the number of rows trained on for each MapReduce iteration. Depending on the value selected, one MapReduce pass can sample observations, and multiple such passes are needed to train for one epoch. All H2O compute nodes then communicate to agree on the best model coefficients (weights/biases) so far, and the model may then be scored (controlled by other parameters below). The default value of -2 indicates auto-tuning, which attemps to keep the communication overhead at 5% of the total runtime. The parameter target_ratio_comm_to_comp controls this ratio. This parameter is explained in more detail in the H2O Deep Learning booklet,
46.8.6 Categorical Data
For categorical data, a feature with K factor levels is automatically one-hot encoded (horizontalized) into K-1 input neurons. Hence, the input neuron layer can grow substantially for datasets with high factor counts. In these cases, it might make sense to reduce the number of hidden neurons in the first hidden layer, such that large numbers of factor levels can be handled. In the limit of 1 neuron in the first hidden layer, the resulting model is similar to logistic regression with stochastic gradient descent, except that for classification problems, there’s still a softmax output layer, and that the activation function is not necessarily a sigmoid (Tanh). If variable importances are computed, it is recommended to turn on use_all_factor_levels (K input neurons for K levels). The experimental option max_categorical_features uses feature hashing to reduce the number of input neurons via the hash trick at the expense of hash collisions and reduced accuracy. Another way to reduce the dimensionality of the (categorical) features is to use h2o.glrm(), we refer to the GLRM tutorial for more details.
46.8.7 Sparse Data
If the input data is sparse (many zeros), then it might make sense to enable the sparse option. This will result in the input not being standardized (0 mean, 1 variance), but only de-scaled (1 variance) and 0 values remain 0, leading to more efficient back-propagation. Sparsity is also a reason why CPU implementations can be faster than GPU implementations, because they can take advantage of if/else statements more effectively.
46.8.8 Missing Values
H2O Deep Learning automatically does mean imputation for missing values during training (leaving the input layer activation at 0 after standardizing the values). For testing, missing test set values are also treated the same way by default. See the h2o.impute function to do your own mean imputation.
46.8.9 Loss functions, Distributions, Offsets, Observation Weights
H2O Deep Learning supports advanced statistical features such as multiple loss functions, non-Gaussian distributions, per-row offsets and observation weights. In addition to Gaussian distributions and Squared loss, H2O Deep Learning supports Poisson, Gamma, Tweedie and Laplace distributions. It also supports Absolute and Huber loss and per-row offsets specified via an offset_column. Observation weights are supported via a user-specified weights_column.
We refer to our H2O Deep Learning R test code examples for more information.
46.8.10 Exporting Weights and Biases
The model parameters (weights connecting two adjacent layers and per-neuron bias terms) can be stored as H2O Frames (like a dataset) by enabling export_weights_and_biases, and they can be accessed as follows:
iris_dl <- h2o.deeplearning(1:4,5,as.h2o(iris),
export_weights_and_biases=T)
#>
|
| | 0%
|
|======================================================================| 100%
#>
|
| | 0%
|
|======================================================================| 100%
h2o.weights(iris_dl, matrix_id=1)
#> Sepal.Length Sepal.Width Petal.Length Petal.Width
#> 1 -0.08727 0.08843 0.06402 -0.0314
#> 2 -0.00817 0.09096 -0.10902 -0.1999
#> 3 -0.05568 0.11660 0.00118 0.0278
#> 4 -0.13747 0.16943 -0.11356 0.0695
#> 5 -0.14982 0.00388 -0.05328 -0.0753
#> 6 -0.14871 0.15230 0.12295 -0.0175
#>
#> [200 rows x 4 columns]
h2o.weights(iris_dl, matrix_id=2)
#> C1 C2 C3 C4 C5 C6 C7 C8 C9
#> 1 0.09922 -0.0737 0.0921 0.11622 -0.0889 -0.043104 5.64e-02 -0.1037 -0.0155
#> 2 0.01543 -0.1036 -0.0357 -0.09692 -0.0969 0.000631 6.69e-03 -0.0106 0.0297
#> 3 -0.08334 0.0735 -0.0631 0.00805 0.0119 0.010224 1.10e-02 -0.1004 0.0454
#> 4 -0.00585 0.0203 -0.0937 0.05366 -0.1037 -0.050496 3.49e-05 -0.0217 -0.0244
#> 5 0.01657 -0.0364 -0.1045 -0.08537 0.0634 -0.100332 -1.94e-03 0.0471 -0.0114
#> 6 -0.00568 0.0898 0.0601 0.06598 -0.0867 -0.092247 -4.26e-02 -0.0206 -0.1070
#> C10 C11 C12 C13 C14 C15 C16 C17 C18
#> 1 -0.1037 0.12306 0.0828 -8.01e-02 0.00487 -0.0338 -0.0448 0.10986 0.11101
#> 2 -0.0461 0.03715 0.1107 3.22e-02 -0.08504 -0.1165 -0.0546 -0.01159 0.08451
#> 3 0.0926 0.00158 0.0666 -1.59e-02 0.02369 -0.0195 0.1005 0.10698 0.03303
#> 4 -0.0769 0.04105 0.0816 -7.38e-05 -0.04802 -0.0825 -0.1114 0.00993 0.00866
#> 5 -0.1222 -0.05741 0.0779 6.50e-02 0.02841 -0.1332 0.0897 -0.02826 -0.08883
#> 6 0.0166 0.04336 -0.0590 -1.17e-01 0.01500 0.0616 -0.0939 0.08423 0.03156
#> C19 C20 C21 C22 C23 C24 C25 C26 C27
#> 1 0.0279 0.11850 -0.06033 0.0720 0.02171 0.0361 -0.0392 -0.01419 -0.08691
#> 2 0.0738 -0.08932 -0.00893 0.0381 0.02044 -0.0630 0.0302 0.05416 0.09318
#> 3 -0.1027 -0.11099 0.09545 0.1205 0.02601 -0.0227 -0.0839 -0.04459 0.00911
#> 4 -0.1152 0.11715 -0.05190 0.0109 0.04553 -0.0654 0.0645 -0.01076 -0.10635
#> 5 -0.0669 -0.00797 0.07151 -0.0643 -0.05882 -0.0318 -0.0337 0.00382 -0.01218
#> 6 0.0215 0.07660 0.00198 -0.0933 -0.00699 -0.0747 -0.0591 -0.00485 -0.06191
#> C28 C29 C30 C31 C32 C33 C34 C35 C36
#> 1 -0.1078 -0.0540 -0.0577 0.03776 -0.0273 -0.00146 -0.0164 -0.05582 0.08007
#> 2 -0.1014 -0.0870 0.0941 -0.12114 0.0978 -0.06492 -0.0483 -0.09885 0.00175
#> 3 -0.0906 -0.0162 -0.0483 -0.00759 -0.0018 -0.09254 -0.0279 0.01888 0.05916
#> 4 0.0552 -0.1164 -0.0525 0.01530 0.0565 -0.06215 0.1058 -0.11409 -0.07624
#> 5 -0.0859 -0.0810 0.1005 -0.01161 0.1056 0.10438 -0.1253 0.00412 0.07896
#> 6 0.0724 -0.0363 -0.0823 -0.03472 0.0287 -0.04848 0.1104 -0.01983 -0.07281
#> C37 C38 C39 C40 C41 C42 C43 C44 C45
#> 1 -0.0408 0.0202 -0.0912 -0.0950 0.00153 0.050771 0.0972 -0.0529 -0.0386
#> 2 -0.0672 -0.0922 0.0391 0.0258 0.10753 -0.118988 0.0799 0.0800 -0.0700
#> 3 -0.1080 0.0683 -0.0343 0.0654 0.11535 0.059139 0.0248 0.0524 0.0459
#> 4 0.1119 -0.0945 -0.0982 0.1156 -0.08058 -0.000276 0.0271 0.0569 0.0523
#> 5 0.0585 -0.1251 0.0198 -0.1114 -0.01061 -0.028604 -0.0708 0.0999 -0.0749
#> 6 -0.1170 -0.1011 -0.0767 0.0429 0.09823 0.001663 -0.0690 -0.1087 0.0817
#> C46 C47 C48 C49 C50 C51 C52 C53 C54
#> 1 -0.00495 0.0261 0.0123 0.00054 -0.07792 0.0903 -0.0484 -0.00793 0.0474
#> 2 0.00520 -0.0525 0.0211 -0.07820 -0.06067 -0.1086 0.0147 -0.05654 0.0971
#> 3 -0.10585 -0.0895 0.1066 0.08412 0.00978 -0.0087 -0.1159 0.10388 0.0447
#> 4 -0.08418 0.0310 -0.0189 -0.12115 0.10033 -0.0268 0.0325 -0.04819 0.0941
#> 5 -0.12854 -0.0195 -0.1028 0.05147 0.00242 -0.1270 -0.0138 -0.09283 -0.0763
#> 6 -0.03785 0.0764 -0.0462 0.07912 -0.02986 -0.0723 0.0235 0.03853 -0.0654
#> C55 C56 C57 C58 C59 C60 C61 C62 C63
#> 1 0.0710 0.0248 0.10158 -0.0776 0.0209 -0.1133 -0.0764 0.0873 -0.0396
#> 2 0.0611 0.0409 -0.05078 0.0296 0.1110 0.0328 -0.0682 -0.0223 -0.0318
#> 3 -0.0204 -0.0630 0.00464 0.1197 -0.1004 0.1085 -0.0119 0.0968 -0.0242
#> 4 -0.0888 -0.1081 0.02116 0.0443 0.0794 0.0560 0.1056 0.0139 -0.0214
#> 5 0.0127 -0.0617 0.10378 0.0788 0.0274 0.0422 0.0494 -0.0756 0.0237
#> 6 0.1107 0.0159 0.02334 -0.0778 0.0551 0.0600 -0.0984 0.1107 0.0121
#> C64 C65 C66 C67 C68 C69 C70 C71 C72
#> 1 0.01735 0.05589 0.1217 0.1152 -0.1125 -0.1196 0.1032 -0.0441 0.0363
#> 2 -0.02541 0.01858 0.0335 0.0684 0.0795 0.1046 0.0476 -0.0323 -0.1038
#> 3 0.10870 0.05590 0.0811 -0.0299 0.1080 -0.0345 0.1051 -0.0986 -0.0360
#> 4 0.10235 -0.03597 0.0825 -0.0221 0.0155 0.1170 0.0986 0.0535 0.0222
#> 5 0.00551 0.00052 0.0144 -0.0632 0.0217 0.0783 0.0154 -0.1001 0.0576
#> 6 -0.07756 -0.07299 -0.1047 -0.0803 0.0911 0.0712 0.0878 -0.0955 -0.0107
#> C73 C74 C75 C76 C77 C78 C79 C80 C81
#> 1 0.0605 -0.0930 0.0486 -0.0485 -0.0138 -0.0293 0.0620 0.015862 -0.0752
#> 2 0.0368 -0.0976 -0.0605 -0.0477 0.0138 0.0989 0.0284 0.041057 -0.0350
#> 3 -0.1072 -0.0172 0.0759 -0.0635 -0.1172 -0.0996 0.1220 0.019579 -0.0838
#> 4 0.0442 0.0240 -0.0917 0.0404 -0.1139 0.1119 -0.0470 0.077751 -0.1154
#> 5 -0.0896 0.0251 -0.1252 -0.1138 -0.0444 0.0919 -0.0506 -0.118346 -0.0952
#> 6 0.1034 0.0693 0.0748 -0.0376 -0.0957 -0.0320 0.0346 -0.000704 -0.0892
#> C82 C83 C84 C85 C86 C87 C88 C89 C90
#> 1 -0.0545 -0.0904 0.0255 -0.0801 -0.12667 -0.0706 0.0340 -0.0314 0.0871
#> 2 -0.0603 0.0949 -0.0510 0.0523 -0.01742 -0.0565 -0.0756 -0.0129 -0.1079
#> 3 0.0169 -0.1134 0.0720 -0.0796 -0.00818 -0.0818 0.1117 -0.0576 0.0318
#> 4 0.0766 -0.0271 0.0940 0.0428 -0.01845 0.0918 0.0931 -0.0728 -0.1225
#> 5 -0.1252 0.0824 -0.1001 0.0734 0.03268 -0.0249 -0.0804 0.0202 0.0695
#> 6 0.1013 0.0603 0.0243 0.0764 -0.06331 -0.0687 0.0522 0.1065 -0.0146
#> C91 C92 C93 C94 C95 C96 C97 C98 C99
#> 1 -0.0723 -0.10262 0.06217 0.0126 0.0289 -0.04439 0.0203 0.00073 0.1182
#> 2 0.1165 0.03143 -0.00860 -0.0174 -0.0897 0.04950 -0.1010 0.11860 0.0741
#> 3 0.0171 0.00154 0.03618 0.0934 0.1066 -0.00407 0.1100 0.00837 -0.0931
#> 4 -0.1027 -0.08362 -0.11232 -0.1092 -0.0557 -0.09350 0.0209 -0.05964 0.1073
#> 5 0.0588 -0.08040 -0.00674 -0.0443 0.0352 0.06605 -0.1136 -0.01119 -0.0669
#> 6 0.0211 0.10580 -0.04343 -0.0953 0.0841 0.09216 0.1009 -0.02239 -0.0746
#> C100 C101 C102 C103 C104 C105 C106 C107 C108
#> 1 -0.00382 -0.0584 -0.075041 0.0181 -0.1138 0.04924 -0.00237 0.0084 0.0267
#> 2 -0.08639 0.0601 -0.045887 -0.1310 -0.0503 0.01928 -0.10937 -0.0784 0.1030
#> 3 0.02960 -0.0924 0.007817 -0.0186 -0.0609 -0.11277 0.09329 0.0467 0.1171
#> 4 -0.03832 0.1098 0.000204 -0.0286 -0.0179 -0.11539 -0.08778 -0.0861 -0.1014
#> 5 -0.07517 0.0442 -0.058510 0.0496 -0.0283 -0.06950 0.03562 -0.0724 0.0116
#> 6 -0.05534 -0.1144 0.040886 0.0280 0.0746 0.00368 0.11511 0.0611 0.0542
#> C109 C110 C111 C112 C113 C114 C115 C116 C117
#> 1 0.05077 -0.0537 0.09629 -0.1002 0.0411 -0.0559 -0.0369 -0.0143 -0.0928
#> 2 0.02056 -0.1042 -0.05218 0.0690 0.0630 0.0337 0.1145 -0.0584 0.0124
#> 3 0.04553 0.1084 -0.00267 -0.0280 -0.0181 0.1114 0.0933 -0.0616 0.0489
#> 4 0.09500 -0.0617 0.11894 -0.1045 0.1002 0.0768 -0.0346 0.0579 0.0824
#> 5 -0.11509 -0.0922 0.02908 0.0403 -0.0183 0.0607 0.0749 0.0159 0.0892
#> 6 -0.00813 0.0297 0.00379 -0.0390 -0.0634 -0.0537 -0.0499 0.1089 0.0161
#> C118 C119 C120 C121 C122 C123 C124 C125 C126
#> 1 -0.09483 0.0319 0.0207 0.04826 0.0206 0.0670 -0.1220 0.0839 -0.0107
#> 2 0.00242 0.0897 0.1059 0.00823 0.0239 -0.0984 0.0541 -0.0961 0.0589
#> 3 -0.02265 0.0538 0.0521 0.11505 0.0800 -0.0080 -0.0104 0.1143 -0.0847
#> 4 0.09629 0.0784 -0.0516 0.03132 -0.0360 -0.0373 -0.0755 -0.1220 -0.0493
#> 5 0.05811 -0.0998 -0.0909 -0.05390 -0.0243 -0.0748 0.0666 -0.0360 -0.0892
#> 6 -0.01299 -0.0709 -0.1150 -0.00316 0.0591 0.1156 -0.0372 -0.0855 -0.0888
#> C127 C128 C129 C130 C131 C132 C133 C134 C135
#> 1 -0.0998 0.0041 0.05413 -0.04725 -0.106027 -0.0233 -0.0768 0.10447 0.1147
#> 2 0.0722 -0.0363 0.00700 0.09280 -0.030555 0.0547 0.0384 0.08132 0.0491
#> 3 0.0933 0.0626 0.07563 0.00749 0.099890 -0.0524 -0.0213 0.00507 0.1031
#> 4 0.0765 0.0306 0.04845 -0.10919 -0.054409 0.0434 -0.0287 -0.00289 -0.0413
#> 5 -0.0132 -0.0226 -0.00962 -0.02548 -0.110555 -0.0655 -0.0823 0.03574 -0.1310
#> 6 -0.0779 0.0857 0.06422 0.09022 0.000698 -0.0218 -0.0369 0.09625 -0.0745
#> C136 C137 C138 C139 C140 C141 C142 C143 C144
#> 1 -0.1175 -0.0842 0.1102 -0.0903 0.0817 0.1099 -0.0219 -0.00132 -0.0211
#> 2 -0.1116 0.0120 0.0820 0.0650 -0.0667 -0.0635 -0.0284 -0.00582 0.0211
#> 3 -0.0809 -0.0114 -0.0110 0.1088 0.1022 -0.0279 0.0328 -0.02339 -0.0102
#> 4 -0.0556 -0.0471 -0.1045 -0.0210 -0.0532 0.1096 -0.1246 -0.01739 0.0166
#> 5 -0.0240 0.0685 0.0242 -0.0421 0.0565 -0.0100 0.1013 0.09419 0.0545
#> 6 0.1143 -0.0633 0.0819 0.0977 -0.0302 -0.1121 0.0737 -0.00939 0.0378
#> C145 C146 C147 C148 C149 C150 C151 C152 C153
#> 1 0.00257 -0.0798 -0.06659 0.08133 0.10511 0.11599 0.1190 -0.10115 -0.0247
#> 2 -0.04248 0.0798 -0.11102 -0.07493 -0.12109 -0.07802 -0.1270 -0.05793 0.0243
#> 3 -0.07912 0.0714 0.02401 -0.08736 0.06847 0.08393 0.1161 -0.08348 0.0293
#> 4 -0.04530 0.1103 0.00953 0.07496 -0.05063 0.11827 0.1172 0.10812 0.0733
#> 5 -0.09323 -0.0149 -0.08976 0.00419 0.00937 0.06417 -0.0233 0.00712 -0.0507
#> 6 0.01909 0.0412 -0.12036 -0.01885 0.03945 -0.00654 -0.0648 -0.07612 0.0586
#> C154 C155 C156 C157 C158 C159 C160 C161 C162
#> 1 -0.0603 -0.026166 0.0498 -0.03230 0.0394 -0.1163 0.10240 0.06856 -0.1095
#> 2 0.0816 0.004778 0.0341 -0.10377 0.0363 0.0400 -0.00461 -0.07024 0.1137
#> 3 0.0265 -0.006385 0.0521 0.06509 -0.1039 0.1122 -0.03994 0.11202 -0.0406
#> 4 -0.0399 -0.105556 -0.1176 -0.00921 -0.0164 0.0420 -0.01304 0.00197 0.0141
#> 5 -0.0721 0.067108 0.0671 0.01139 -0.0597 0.0997 0.00855 -0.01677 -0.0407
#> 6 -0.0423 -0.000734 0.1185 0.08029 0.1028 -0.0455 -0.01404 0.00577 0.0885
#> C163 C164 C165 C166 C167 C168 C169 C170 C171
#> 1 -0.08364 -0.0693 -0.1185 0.0151 0.0798 -0.0285 0.03434 -9.15e-02 0.03736
#> 2 -0.00749 -0.0414 -0.0714 0.0523 -0.0148 -0.1090 0.00709 1.03e-01 0.00428
#> 3 -0.12564 0.1009 -0.0907 0.1042 -0.1250 -0.0186 -0.09155 2.01e-02 -0.00363
#> 4 -0.05828 0.0378 0.0990 0.0572 -0.0922 -0.0227 0.03143 5.26e-02 0.07796
#> 5 0.08742 -0.0684 0.1001 -0.0603 -0.0147 -0.0294 -0.08002 4.16e-02 -0.03292
#> 6 -0.09761 0.0527 -0.0509 -0.0633 0.1149 -0.1084 -0.11013 -3.22e-05 -0.07412
#> C172 C173 C174 C175 C176 C177 C178 C179 C180
#> 1 0.0250 0.0832 -0.12026 0.0936 0.0561 0.0632 -0.0469 0.0652 0.0618
#> 2 0.1108 -0.0791 0.08166 -0.1057 -0.1110 0.0698 0.1078 0.0834 0.0705
#> 3 0.0238 -0.0586 0.00887 -0.0337 -0.1028 0.0842 0.0968 0.0318 0.0200
#> 4 -0.0227 0.0170 -0.03040 0.0996 -0.0503 -0.1019 -0.0867 0.0213 0.0304
#> 5 -0.1060 0.0052 -0.04499 -0.0645 0.0280 -0.1180 0.0596 -0.0634 0.0798
#> 6 0.0668 0.0689 -0.02872 -0.0752 0.1049 -0.1009 0.1184 -0.0679 -0.1066
#> C181 C182 C183 C184 C185 C186 C187 C188 C189
#> 1 0.0160 -0.00221 0.0587 -0.11178 0.0792 -0.03686 0.0993 0.1064 0.0921
#> 2 0.1072 -0.08584 -0.1170 0.07138 0.0782 0.04343 0.0481 -0.0331 -0.1101
#> 3 0.0393 0.06467 0.0566 -0.11520 0.0748 0.00957 -0.0636 0.1101 -0.0530
#> 4 -0.0690 0.05167 0.1062 -0.06575 -0.0820 0.07668 0.0103 0.0234 0.1194
#> 5 0.0721 -0.13225 0.0504 0.00225 0.0315 -0.11703 -0.0173 -0.1283 -0.1221
#> 6 0.1083 -0.07209 0.1151 -0.02829 -0.0444 -0.01343 0.0852 0.1004 -0.0832
#> C190 C191 C192 C193 C194 C195 C196 C197 C198
#> 1 -0.0498 -0.0652 -0.0665 0.0995 -0.00982 0.01226 0.0878 0.1174 0.0283
#> 2 0.0156 -0.0796 0.0585 -0.0826 -0.12440 -0.08259 -0.0138 -0.0785 -0.0431
#> 3 -0.0037 -0.0163 -0.0286 0.0608 0.00151 -0.03948 0.1081 -0.0135 -0.0290
#> 4 -0.1017 -0.1100 -0.1222 0.0586 -0.11240 -0.06053 0.0266 0.0600 0.0378
#> 5 -0.0293 0.1071 0.0379 -0.0495 -0.08287 0.00948 0.0829 0.0612 -0.0681
#> 6 -0.0958 0.1062 -0.0457 0.0700 -0.05297 0.06044 -0.0521 -0.0756 -0.0177
#> C199 C200
#> 1 0.068107 0.0285
#> 2 -0.112693 -0.0460
#> 3 -0.003496 0.0881
#> 4 0.085758 -0.0324
#> 5 -0.000338 0.0220
#> 6 -0.107439 0.1040
#>
#> [200 rows x 200 columns]
h2o.weights(iris_dl, matrix_id=3)
#> C1 C2 C3 C4 C5 C6 C7 C8 C9 C10
#> 1 -0.655 0.662 -0.5264 0.642 -0.0366 0.1237 0.0143 -0.282 -0.1194 -0.632
#> 2 0.400 0.585 -0.0969 -0.538 0.6306 -0.2069 -0.2360 -0.255 -0.4565 -0.379
#> 3 -0.423 0.651 -0.3014 -0.112 -0.6332 -0.0475 0.6402 0.675 -0.0224 -0.396
#> C11 C12 C13 C14 C15 C16 C17 C18 C19 C20
#> 1 0.364 0.444 -0.169 -0.1594 -0.4144 -0.3101 -0.0463 -0.598 -0.253 0.475
#> 2 -0.174 -0.113 -0.588 -0.2760 0.0355 0.3696 0.0887 -0.130 0.275 -0.405
#> 3 -0.480 0.451 -0.176 0.0023 -0.0190 0.0142 0.5751 0.305 -0.613 0.463
#> C21 C22 C23 C24 C25 C26 C27 C28 C29 C30
#> 1 -0.248 0.13778 0.307 0.5855 0.0727 0.205 0.2261 0.317 0.21440 -0.199
#> 2 -0.457 0.44922 0.325 -0.0102 0.0701 0.202 -0.0194 -0.407 -0.45659 -0.222
#> 3 0.229 -0.00607 -0.495 0.2003 -0.1129 0.410 -0.2814 0.263 -0.00509 0.464
#> C31 C32 C33 C34 C35 C36 C37 C38 C39 C40
#> 1 0.0391 0.226 0.3171 0.274 -0.00189 -0.558 0.4651 -0.0112 0.308 -0.3646
#> 2 0.3295 0.548 0.0517 -0.109 -0.26907 0.568 0.0236 -0.3574 0.243 -0.5135
#> 3 -0.2861 0.630 -0.0766 -0.449 0.12883 -0.465 0.1860 0.1268 -0.282 -0.0842
#> C41 C42 C43 C44 C45 C46 C47 C48 C49 C50
#> 1 -0.2394 0.402 0.339 -0.412 0.0337 0.668 0.357 -0.103 0.402 -0.2222
#> 2 0.0994 0.369 -0.396 0.516 0.3022 0.502 -0.273 -0.243 -0.587 0.0822
#> 3 -0.3813 -0.124 0.504 -0.354 -0.6548 -0.601 -0.418 -0.315 -0.357 -0.5537
#> C51 C52 C53 C54 C55 C56 C57 C58 C59 C60 C61
#> 1 -0.380 0.550 -0.499 0.399 -0.584 -0.448 -0.546 -0.360 -0.160 -0.218 0.0764
#> 2 0.515 0.573 0.425 0.550 0.228 0.198 -0.302 0.245 0.577 -0.235 0.3004
#> 3 -0.320 -0.525 -0.666 0.634 -0.334 -0.457 -0.267 0.670 0.550 -0.191 0.4525
#> C62 C63 C64 C65 C66 C67 C68 C69 C70 C71
#> 1 0.1300 0.290 -0.463 -0.583 -0.644 0.499 -0.0503 -0.655 -0.166 0.432
#> 2 0.4563 0.235 -0.416 -0.140 0.229 -0.678 -0.4541 0.254 0.367 0.606
#> 3 -0.0444 0.489 0.400 -0.138 0.379 0.136 -0.4982 -0.349 0.268 -0.258
#> C72 C73 C74 C75 C76 C77 C78 C79 C80 C81
#> 1 -0.3303 -0.226 -0.6726 -0.5286 -0.179 -0.244 -0.593 -0.685 -0.00832 -0.658
#> 2 0.0117 0.532 -0.4495 -0.0238 -0.560 -0.189 -0.391 0.387 -0.21606 0.305
#> 3 -0.6785 -0.292 -0.0684 0.3148 -0.588 0.422 -0.654 -0.365 0.19645 -0.292
#> C82 C83 C84 C85 C86 C87 C88 C89 C90 C91
#> 1 -0.164 -0.3590 0.483 0.00443 0.0615 0.6462 0.0367 0.540 0.317 -0.322
#> 2 -0.582 -0.5422 -0.103 0.19771 -0.6030 0.6169 -0.1886 0.641 -0.626 -0.379
#> 3 0.630 0.0702 -0.315 -0.28642 -0.0482 0.0784 0.3326 0.645 0.638 0.230
#> C92 C93 C94 C95 C96 C97 C98 C99 C100 C101 C102
#> 1 -0.513 -0.052 -0.279 -0.609 -0.668 0.586 0.690 -0.267 -0.187 -0.204 -0.0702
#> 2 0.353 0.518 0.220 -0.556 -0.420 0.493 -0.307 -0.243 -0.490 -0.308 -0.2622
#> 3 0.271 0.544 -0.440 -0.441 -0.637 -0.603 0.137 0.374 0.543 0.470 0.5582
#> C103 C104 C105 C106 C107 C108 C109 C110 C111 C112
#> 1 0.2342 -0.1698 0.449 -0.0333 0.509 -0.589 -0.6357 0.569 0.612 0.348
#> 2 0.0455 0.3808 0.282 -0.6382 0.204 -0.398 0.0472 0.396 -0.568 0.516
#> 3 -0.2586 0.0876 -0.141 -0.1740 0.380 0.576 -0.1670 -0.610 -0.298 0.520
#> C113 C114 C115 C116 C117 C118 C119 C120 C121 C122
#> 1 -0.388 0.387 -0.3090 0.493469 0.518 -0.376 0.380 0.433 -0.440 0.203
#> 2 0.443 -0.215 0.0602 -0.073088 -0.492 -0.193 -0.648 0.105 0.523 0.632
#> 3 0.236 -0.367 0.0178 0.000603 -0.325 -0.142 -0.494 0.311 0.349 0.281
#> C123 C124 C125 C126 C127 C128 C129 C130 C131 C132
#> 1 -0.671 -0.5977 0.310 -0.170 -0.4563 -0.6298 -0.143 0.552 -0.3085 -0.280
#> 2 -0.120 -0.0753 0.255 -0.220 -0.0983 -0.0716 -0.349 -0.034 0.0278 0.626
#> 3 -0.238 0.3768 0.594 -0.382 0.5077 0.4091 0.105 0.263 -0.0275 -0.612
#> C133 C134 C135 C136 C137 C138 C139 C140 C141 C142
#> 1 -0.214 0.362 -0.1390 0.384 -0.612 0.0353 -0.4680 -0.606 0.3312 0.2481
#> 2 0.350 0.168 -0.0816 -0.449 0.611 0.1656 0.0621 0.657 -0.0137 -0.0406
#> 3 0.307 0.216 0.3351 -0.313 -0.463 -0.6402 -0.1030 0.234 0.0184 0.2340
#> C143 C144 C145 C146 C147 C148 C149 C150 C151 C152
#> 1 -0.6295 -0.450 0.366 -0.629 -0.477 0.4026 0.303 -0.586 -0.624 -0.148
#> 2 0.0188 0.219 -0.282 0.412 0.627 0.0944 -0.614 -0.294 -0.326 0.142
#> 3 0.5700 0.128 -0.249 -0.632 -0.460 -0.6853 -0.634 0.256 -0.376 0.290
#> C153 C154 C155 C156 C157 C158 C159 C160 C161 C162 C163
#> 1 0.614 -0.100 -0.297 -0.4826 -0.638 0.422 -0.2391 0.199 0.573 0.185 -0.0859
#> 2 -0.631 0.246 0.113 -0.0508 0.450 -0.297 -0.0996 0.361 0.178 -0.553 -0.0213
#> 3 0.331 0.549 -0.529 -0.6555 -0.329 0.589 -0.5104 0.500 0.611 0.359 -0.6433
#> C164 C165 C166 C167 C168 C169 C170 C171 C172 C173
#> 1 0.6746 0.436 0.144 0.0492 -0.339 -0.560 0.5439 -0.235 0.146 -0.367
#> 2 0.0474 -0.535 0.307 -0.1702 0.381 -0.152 0.0893 0.370 -0.546 0.109
#> 3 0.3603 0.371 0.529 -0.5257 0.346 0.455 -0.2905 0.290 -0.524 0.518
#> C174 C175 C176 C177 C178 C179 C180 C181 C182 C183
#> 1 0.3666 0.505 0.636 -0.295 -0.00705 0.637 0.0407 0.2719 0.296 -0.5035
#> 2 -0.4711 -0.434 -0.271 -0.317 0.12136 0.469 0.6614 -0.5424 -0.671 -0.2544
#> 3 0.0525 -0.353 -0.583 -0.177 -0.22265 0.436 -0.1481 0.0371 -0.507 0.0628
#> C184 C185 C186 C187 C188 C189 C190 C191 C192 C193
#> 1 0.1799 0.1757 0.473 0.0785 -0.550 -0.445 0.520 -0.138 -0.3662 -0.1049
#> 2 -0.6618 -0.0657 -0.137 -0.3014 0.207 -0.635 0.165 0.490 0.1307 -0.1004
#> 3 -0.0442 -0.3122 -0.511 0.6557 0.621 0.396 -0.574 -0.605 -0.0666 -0.0291
#> C194 C195 C196 C197 C198 C199 C200
#> 1 0.273 -0.5851 -0.677 -0.122 0.566 0.671 0.202
#> 2 -0.128 0.0945 -0.591 0.607 0.422 0.247 -0.357
#> 3 -0.263 0.5009 -0.184 0.222 0.311 0.254 0.494
#>
#> [3 rows x 200 columns]
h2o.biases(iris_dl, vector_id=1)
#> C1
#> 1 0.415
#> 2 0.468
#> 3 0.431
#> 4 0.405
#> 5 0.509
#> 6 0.432
#>
#> [200 rows x 1 column]
h2o.biases(iris_dl, vector_id=2)
#> C1
#> 1 1.005
#> 2 0.988
#> 3 1.001
#> 4 0.995
#> 5 0.983
#> 6 0.991
#>
#> [200 rows x 1 column]
h2o.biases(iris_dl, vector_id=3)
#> C1
#> 1 -0.00565
#> 2 0.00222
#> 3 -0.00339
#>
#> [3 rows x 1 column]
#plot weights connecting `Sepal.Length` to first hidden neurons
plot(as.data.frame(h2o.weights(iris_dl, matrix_id=1))[,1])
46.8.11 Reproducibility
Every run of DeepLearning results in different results since multithreading is done via Hogwild! that benefits from intentional lock-free race conditions between threads. To get reproducible results for small datasets and testing purposes, set reproducible=T and set seed=1337 (pick any integer). This will not work for big data for technical reasons, and is probably also not desired because of the significant slowdown (runs on 1 core only).
46.8.12 Scoring on Training/Validation Sets During Training
The training and/or validation set errors can be based on a subset of the training or validation data, depending on the values for score_validation_samples (defaults to 0: all) or score_training_samples (defaults to 10,000 rows, since the training error is only used for early stopping and monitoring). For large datasets, Deep Learning can automatically sample the validation set to avoid spending too much time in scoring during training, especially since scoring results are not currently displayed in the model returned to R.
Note that the default value of score_duty_cycle=0.1 limits the amount of time spent in scoring to 10%, so a large number of scoring samples won’t slow down overall training progress too much, but it will always score once after the first MapReduce iteration, and once at the end of training.
Stratified sampling of the validation dataset can help with scoring on datasets with class imbalance. Note that this option also requires balance_classes to be enabled (used to over/under-sample the training dataset, based on the max. relative size of the resulting training dataset, max_after_balance_size):
More information can be found in the H2O Deep Learning booklet, in our H2O SlideShare Presentations, our H2O YouTube channel, as well as on our H2O Github Repository, especially in our H2O Deep Learning R tests, and H2O Deep Learning Python tests.
46.9 All done, shutdown H2O
h2o.shutdown(prompt=FALSE)