12 Multilevel Models
Multilevel models… remember features of each cluster in the data as they learn about all of the clusters. Depending upon the variation among clusters, which is learned from the data as well, the model pools information across clusters. This pooling tends to improve estimates about each cluster. This improved estimation leads to several, more pragmatic sounding, benefits of the multilevel approach. (p. 356)
These benefits include:
- improved estimates for repeated sampling (i.e., in longitudinal data)
- improved estimates when there are imbalances among subsamples
- estimates of the variation across subsamples
- avoiding simplistic averaging by retaining variation across subsamples
All of these benefits flow out of the same strategy and model structure. You learn one basic design and you get all of this for free.
When it comes to regression, multilevel regression deserves to be the default approach. There are certainly contexts in which it would be better to use an old-fashioned single-level model. But the contexts in which multilevel models are superior are much more numerous. It is better to begin to build a multilevel analysis, and then realize it’s unnecessary, than to overlook it. And once you grasp the basic multilevel stragety, it becomes much easier to incorporate related tricks such as allowing for measurement error in the data and even model missing data itself (Chapter 14). (p. 356)
I’m totally on board with this. After learning about the multilevel model, I see it everywhere. For more on the sentiment it should be the default, check out McElreath’s blog post, Multilevel Regression as Default.
12.1 Example: Multilevel tadpoles
Let’s get the reedfrogs data from rethinking.
library(rethinking)
data(reedfrogs)
d <- reedfrogsDetach rethinking and load brms.
rm(reedfrogs)
detach(package:rethinking, unload = T)
library(brms)Go ahead and acquaint yourself with the reedfrogs.
library(tidyverse)
d %>%
glimpse()## Observations: 48
## Variables: 5
## $ density <int> 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 25, 25, 25, 25, …
## $ pred <fct> no, no, no, no, no, no, no, no, pred, pred, pred, pred, pred, pred, pred, pred, …
## $ size <fct> big, big, big, big, small, small, small, small, big, big, big, big, small, small…
## $ surv <int> 9, 10, 7, 10, 9, 9, 10, 9, 4, 9, 7, 6, 7, 5, 9, 9, 24, 23, 22, 25, 23, 23, 23, 2…
## $ propsurv <dbl> 0.9000000, 1.0000000, 0.7000000, 1.0000000, 0.9000000, 0.9000000, 1.0000000, 0.9…Making the tank cluster variable is easy.
d <-
d %>%
mutate(tank = 1:nrow(d))Here’s the formula for the un-pooled model in which each tank gets its own intercept.
\[\begin{align*} \text{surv}_i & \sim \text{Binomial} (n_i, p_i) \\ \text{logit} (p_i) & = \alpha_{\text{tank}_i} \\ \alpha_{\text{tank}} & \sim \text{Normal} (0, 5) \end{align*}\]
And \(n_i = \text{density}_i\). Now we’ll fit this simple aggregated binomial model much like we practiced in Chapter 10.
b12.1 <-
brm(data = d, family = binomial,
surv | trials(density) ~ 0 + factor(tank),
prior(normal(0, 5), class = b),
iter = 2000, warmup = 500, chains = 4, cores = 4,
seed = 12)The formula for the multilevel alternative is
\[\begin{align*} \text{surv}_i & \sim \text{Binomial} (n_i, p_i) \\ \text{logit} (p_i) & = \alpha_{\text{tank}_i} \\ \alpha_{\text{tank}} & \sim \text{Normal} (\alpha, \sigma) \\ \alpha & \sim \text{Normal} (0, 1) \\ \sigma & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
You specify the corresponding multilevel model like this.
b12.2 <-
brm(data = d, family = binomial,
surv | trials(density) ~ 1 + (1 | tank),
prior = c(prior(normal(0, 1), class = Intercept),
prior(cauchy(0, 1), class = sd)),
iter = 4000, warmup = 1000, chains = 4, cores = 4,
seed = 12)The syntax for the varying effects follows the lme4 style, ( <varying parameter(s)> | <grouping variable(s)> ). In this case (1 | tank) indicates only the intercept, 1, varies by tank. The extent to which parameters vary is controlled by the prior, prior(cauchy(0, 1), class = sd), which is parameterized in the standard deviation metric. Do note that last part. It’s common in multilevel software to model in the variance metric, instead.
Let’s do the WAIC comparisons.
b12.1 <- add_criterion(b12.1, "waic")
b12.2 <- add_criterion(b12.2, "waic")
w <- loo_compare(b12.1, b12.2, criterion = "waic")
print(w, simplify = F)## elpd_diff se_diff elpd_waic se_elpd_waic p_waic se_p_waic waic se_waic
## b12.2 0.0 0.0 -99.9 3.6 20.8 0.8 199.9 7.3
## b12.1 -0.5 2.2 -100.4 4.6 22.4 0.6 200.9 9.3The se_diff is large relative to the elpd_diff. If we convert the \(\text{elpd}\) difference to the WAIC metric, the message stays the same.
cbind(waic_diff = w[, 1] * -2,
se = w[, 2] * 2)## waic_diff se
## b12.2 0.0000000 0.000000
## b12.1 0.9724156 4.491781I’m not going to show it here, but if you’d like a challenge, try comparing the models with the LOO. You’ll learn all about high pareto_k values, kfold() recommendations, and challenges implementing those kfold() recommendations. If you’re interested, pour yourself a calming adult beverage, execute the code below, and check out the Kfold(): “Error: New factor levels are not allowed” thread in the Stan forums.
b12.1 <- add_criterion(b12.1, "loo")
b12.2 <- add_criterion(b12.2, "loo")But back on track, here’s our prep work for Figure 12.1.
post <- posterior_samples(b12.2, add_chain = T)
post_mdn <-
coef(b12.2, robust = T)$tank[, , ] %>%
as_tibble() %>%
bind_cols(d) %>%
mutate(post_mdn = inv_logit_scaled(Estimate))
post_mdn## # A tibble: 48 x 11
## Estimate Est.Error Q2.5 Q97.5 density pred size surv propsurv tank post_mdn
## <dbl> <dbl> <dbl> <dbl> <int> <fct> <fct> <int> <dbl> <int> <dbl>
## 1 2.08 0.852 0.629 4.00 10 no big 9 0.9 1 0.889
## 2 2.96 1.04 1.18 5.49 10 no big 10 1 2 0.951
## 3 0.969 0.680 -0.226 2.41 10 no big 7 0.7 3 0.725
## 4 2.95 1.07 1.16 5.44 10 no big 10 1 4 0.950
## 5 2.06 0.852 0.599 4.00 10 no small 9 0.9 5 0.887
## 6 2.06 0.849 0.587 4.06 10 no small 9 0.9 6 0.886
## 7 2.96 1.10 1.18 5.46 10 no small 10 1 7 0.951
## 8 2.07 0.850 0.617 4.02 10 no small 9 0.9 8 0.888
## 9 -0.178 0.604 -1.42 1.03 10 pred big 4 0.4 9 0.456
## 10 2.07 0.832 0.613 4.04 10 pred big 9 0.9 10 0.888
## # … with 38 more rowsFor kicks and giggles, let’s use a FiveThirtyEight-like theme for this chapter’s plots. An easy way to do so is with help from the ggthemes package.
# install.packages("ggthemes", dependencies = T)
library(ggthemes) Finally, here’s the ggplot2 code to reproduce Figure 12.1.
post_mdn %>%
ggplot(aes(x = tank)) +
geom_hline(yintercept = inv_logit_scaled(median(post$b_Intercept)), linetype = 2, size = 1/4) +
geom_vline(xintercept = c(16.5, 32.5), size = 1/4) +
geom_point(aes(y = propsurv), color = "orange2") +
geom_point(aes(y = post_mdn), shape = 1) +
coord_cartesian(ylim = c(0, 1)) +
scale_x_continuous(breaks = c(1, 16, 32, 48)) +
labs(title = "Multilevel shrinkage!",
subtitle = "The empirical proportions are in orange while the model-\nimplied proportions are the black circles. The dashed line is\nthe model-implied average survival proportion.") +
annotate("text", x = c(8, 16 + 8, 32 + 8), y = 0,
label = c("small tanks", "medium tanks", "large tanks")) +
theme_fivethirtyeight() +
theme(panel.grid = element_blank())
Here is our version of Figure 12.2.a.
# this makes the output of `sample_n()` reproducible
set.seed(12)
post %>%
sample_n(100) %>%
expand(nesting(iter, b_Intercept, sd_tank__Intercept),
x = seq(from = -4, to = 5, length.out = 100)) %>%
ggplot(aes(x = x, group = iter)) +
geom_line(aes(y = dnorm(x, b_Intercept, sd_tank__Intercept)),
alpha = .2, color = "orange2") +
labs(title = "Population survival distribution",
subtitle = "The Gaussians are on the log-odds scale.") +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(-3, 4)) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 13),
plot.subtitle = element_text(size = 10))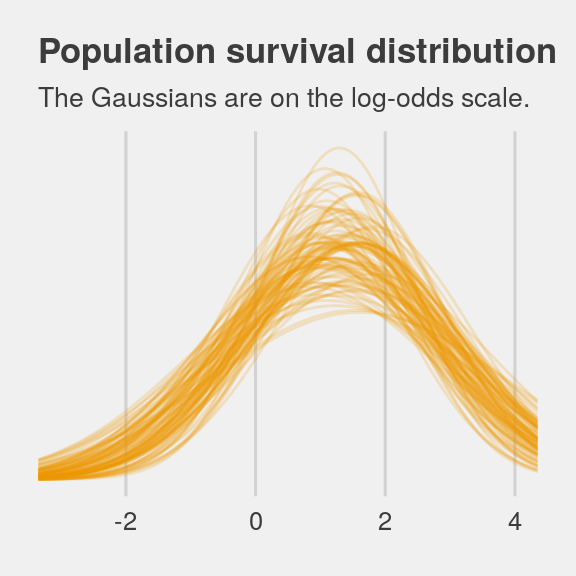
Note the uncertainty in terms of both location \(\alpha\) and scale \(\sigma\). Now here’s the code for Figure 12.2.b.
ggplot(data = post,
aes(x = rnorm(n = nrow(post),
mean = b_Intercept,
sd = sd_tank__Intercept) %>%
inv_logit_scaled())) +
geom_density(size = 0, fill = "orange2") +
scale_y_continuous(NULL, breaks = NULL) +
ggtitle("Probability of survival") +
theme_fivethirtyeight()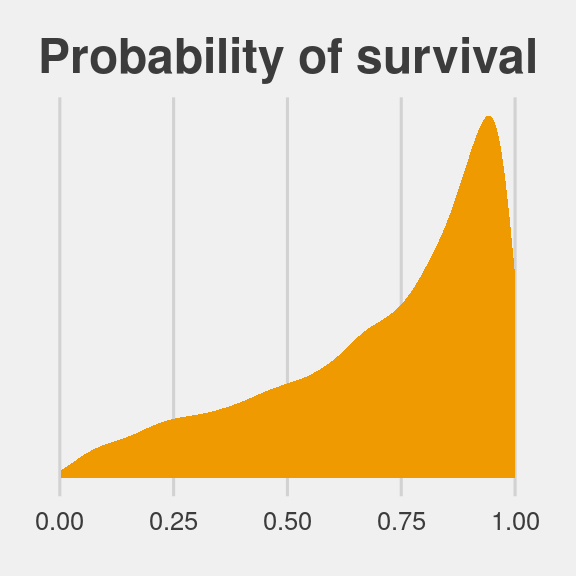
Note how we sampled 12,000 imaginary tanks rather than McElreath’s 8,000. This is because we had 12,000 HMC iterations (i.e., execute nrow(post)).
The aes() code, above, was a bit much. To get a sense of how it worked, consider this:
set.seed(12)
rnorm(n = 1,
mean = post$b_Intercept,
sd = post$sd_tank__Intercept) %>%
inv_logit_scaled()## [1] 0.2902134First, we took one random draw from a normal distribution with a mean of the first row in post$b_Intercept and a standard deviation of the value from the first row in post$sd_tank__Intercept, and passed it through the inv_logit_scaled() function. By replacing the 1 with nrow(post), we do this nrow(post) times (i.e., 12,000). Our orange density, then, is the summary of that process.
12.1.0.1 Overthinking: Prior for variance components.
Yep, you can use the exponential distribution for your priors in brms. Here it is for model b12.2.
b12.2.e <-
update(b12.2,
prior = c(prior(normal(0, 1), class = Intercept),
prior(exponential(1), class = sd)))The model summary:
print(b12.2.e)## Family: binomial
## Links: mu = logit
## Formula: surv | trials(density) ~ 1 + (1 | tank)
## Data: d (Number of observations: 48)
## Samples: 4 chains, each with iter = 4000; warmup = 1000; thin = 1;
## total post-warmup samples = 12000
##
## Group-Level Effects:
## ~tank (Number of levels: 48)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 1.61 0.21 1.25 2.08 3270 1.00
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 1.31 0.25 0.83 1.81 2196 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).If you’re curious how the exponential prior compares to the posterior, you might just plot.
tibble(x = seq(from = 0, to = 6, by = .01)) %>%
ggplot() +
# the prior
geom_ribbon(aes(x = x, ymin = 0, ymax = dexp(x, rate = 1)),
fill = "orange2", alpha = 1/3) +
# the posterior
geom_density(data = posterior_samples(b12.2.e),
aes(x = sd_tank__Intercept),
fill = "orange2", size = 0) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(0, 5)) +
labs(title = "Bonus prior/posterior plot\nfor sd_tank__Intercept",
subtitle = "The prior is the semitransparent ramp in the\nbackground. The posterior is the solid orange\nmound.") +
theme_fivethirtyeight()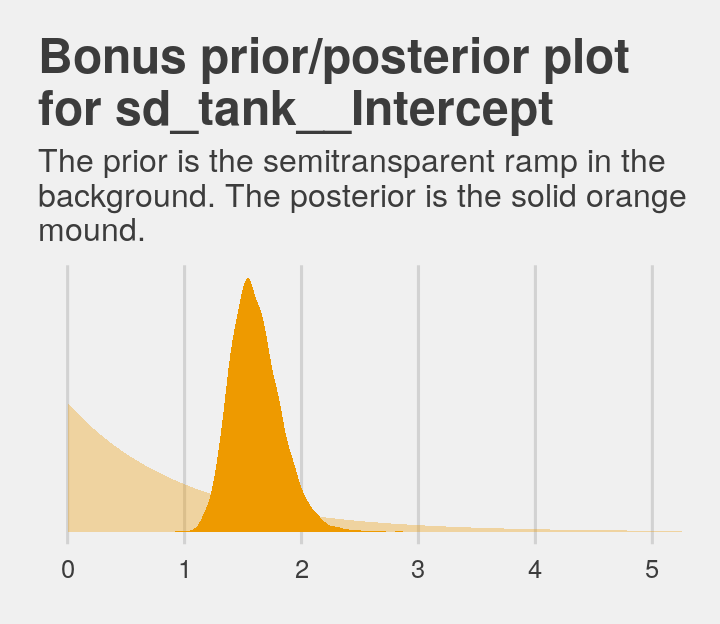
12.2 Varying effects and the underfitting/overfitting trade-off
Varying intercepts are just regularized estimates, but adaptively regularized by estimating how diverse the clusters are while estimating the features of each cluster. This fact is not easy to grasp…
A major benefit of using varying effects estimates, instead of the empirical raw estimates, is that they provide more accurate estimates of the individual cluster (tank) intercepts. On average, the varying effects actually provide a better estimate of the individual tank (cluster) means. The reason that the varying intercepts provides better estimates is that they do a better job trading off underfitting and overfitting. (p. 364)
In this section, we explicate this by contrasting three perspectives:
- Complete pooling (i.e., a single-\(\alpha\) model)
- No pooling (i.e., the single-level \(\alpha_{\text{tank}_i}\) model)
- Partial pooling (i.e., the multilevel model for which \(\alpha_{\text{tank}} \sim \text{Normal} (\alpha, \sigma)\))
To demonstrate [the magic of the multilevel model], we’ll simulate some tadpole data. That way, we’ll know the true per-pond survival probabilities. Then we can compare the no-pooling estimates to the partial pooling estimates, by computing how close each gets to the true values they are trying to estimate. The rest of this section shows how to do such a simulation. (p. 365)
12.2.1 The model.
The simulation formula should look familiar.
\[\begin{align*} \text{surv}_i & \sim \text{Binomial} (n_i, p_i) \\ \text{logit} (p_i) & = \alpha_{\text{pond}_i} \\ \alpha_{\text{pond}} & \sim \text{Normal} (\alpha, \sigma) \\ \alpha & \sim \text{Normal} (0, 1) \\ \sigma & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
12.2.2 Assign values to the parameters.
a <- 1.4
sigma <- 1.5
n_ponds <- 60
set.seed(12)
(
dsim <-
tibble(pond = 1:n_ponds,
ni = rep(c(5, 10, 25, 35), each = n_ponds / 4) %>% as.integer(),
true_a = rnorm(n = n_ponds, mean = a, sd = sigma))
)## # A tibble: 60 x 3
## pond ni true_a
## <int> <int> <dbl>
## 1 1 5 -0.821
## 2 2 5 3.77
## 3 3 5 -0.0351
## 4 4 5 0.0200
## 5 5 5 -1.60
## 6 6 5 0.992
## 7 7 5 0.927
## 8 8 5 0.458
## 9 9 5 1.24
## 10 10 5 2.04
## # … with 50 more rows12.2.3 Sumulate survivors.
Each pond \(i\) has \(n_i\) potential survivors, and nature flips each tadpole’s coin, so to speak, with probability of survival \(p_i\). This probability \(p_i\) is implied by the model definition, and is equal to:
\[p_i = \frac{\text{exp} (\alpha_i)}{1 + \text{exp} (\alpha_i)}\]
The model uses a logit link, and so the probability is defined by the [
inv_logit_scaled()] function. (p. 367)
set.seed(12)
(
dsim <-
dsim %>%
mutate(si = rbinom(n = n(), prob = inv_logit_scaled(true_a), size = ni))
)## # A tibble: 60 x 4
## pond ni true_a si
## <int> <int> <dbl> <int>
## 1 1 5 -0.821 0
## 2 2 5 3.77 5
## 3 3 5 -0.0351 4
## 4 4 5 0.0200 3
## 5 5 5 -1.60 0
## 6 6 5 0.992 5
## 7 7 5 0.927 5
## 8 8 5 0.458 3
## 9 9 5 1.24 5
## 10 10 5 2.04 5
## # … with 50 more rows12.2.4 Compute the no-pooling estimates.
The no-pooling estimates (i.e., \(\alpha_{\text{tank}_i}\)) are the results of simple algebra.
(
dsim <-
dsim %>%
mutate(p_nopool = si / ni)
)## # A tibble: 60 x 5
## pond ni true_a si p_nopool
## <int> <int> <dbl> <int> <dbl>
## 1 1 5 -0.821 0 0
## 2 2 5 3.77 5 1
## 3 3 5 -0.0351 4 0.8
## 4 4 5 0.0200 3 0.6
## 5 5 5 -1.60 0 0
## 6 6 5 0.992 5 1
## 7 7 5 0.927 5 1
## 8 8 5 0.458 3 0.6
## 9 9 5 1.24 5 1
## 10 10 5 2.04 5 1
## # … with 50 more rows“These are the same no-pooling estimates you’d get by fitting a model with a dummy variable for each pond and flat priors that induce no regularization” (p. 367).
12.2.5 Compute the partial-pooling estimates.
To follow along with McElreath, set chains = 1, cores = 1 to fit with one chain.
b12.3 <-
brm(data = dsim, family = binomial,
si | trials(ni) ~ 1 + (1 | pond),
prior = c(prior(normal(0, 1), class = Intercept),
prior(cauchy(0, 1), class = sd)),
iter = 10000, warmup = 1000, chains = 1, cores = 1,
seed = 12)print(b12.3)## Family: binomial
## Links: mu = logit
## Formula: si | trials(ni) ~ 1 + (1 | pond)
## Data: dsim (Number of observations: 60)
## Samples: 1 chains, each with iter = 10000; warmup = 1000; thin = 1;
## total post-warmup samples = 9000
##
## Group-Level Effects:
## ~pond (Number of levels: 60)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 1.30 0.19 0.97 1.71 3186 1.00
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 1.28 0.20 0.91 1.68 3016 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).I’m not aware that you can use McElreath’s depth=2 trick in brms for summary() or print(). But can get that information with the coef() function.
coef(b12.3)$pond[c(1:2, 59:60), , ] %>%
round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## 1 -1.08 0.89 -3.01 0.54
## 2 2.30 1.02 0.49 4.47
## 59 0.97 0.37 0.26 1.71
## 60 1.42 0.41 0.66 2.25Note how we just peeked at the top and bottom two rows with the c(1:2, 59:60) part of the code, there. Somewhat discouragingly, coef() doesn’t return the ‘Eff.Sample’ or ‘Rhat’ columns as in McElreath’s output. We can still extract that information, though. For \(\hat{R}\), the solution is simple; use the brms::rhat() function.
rhat(b12.3)## b_Intercept sd_pond__Intercept r_pond[1,Intercept] r_pond[2,Intercept]
## 1.0010076 0.9999010 1.0000283 0.9999926
## r_pond[3,Intercept] r_pond[4,Intercept] r_pond[5,Intercept] r_pond[6,Intercept]
## 0.9999020 0.9999937 0.9998954 0.9999349
## r_pond[7,Intercept] r_pond[8,Intercept] r_pond[9,Intercept] r_pond[10,Intercept]
## 0.9999039 0.9998913 0.9999165 0.9998949
## r_pond[11,Intercept] r_pond[12,Intercept] r_pond[13,Intercept] r_pond[14,Intercept]
## 0.9999421 1.0000767 0.9999453 0.9999021
## r_pond[15,Intercept] r_pond[16,Intercept] r_pond[17,Intercept] r_pond[18,Intercept]
## 1.0001642 1.0001294 1.0000320 0.9998950
## r_pond[19,Intercept] r_pond[20,Intercept] r_pond[21,Intercept] r_pond[22,Intercept]
## 0.9998891 1.0000294 0.9999855 0.9999565
## r_pond[23,Intercept] r_pond[24,Intercept] r_pond[25,Intercept] r_pond[26,Intercept]
## 0.9998916 0.9998919 1.0001516 1.0002602
## r_pond[27,Intercept] r_pond[28,Intercept] r_pond[29,Intercept] r_pond[30,Intercept]
## 1.0001181 0.9998902 0.9998953 0.9999522
## r_pond[31,Intercept] r_pond[32,Intercept] r_pond[33,Intercept] r_pond[34,Intercept]
## 1.0002802 0.9998892 1.0006365 1.0002835
## r_pond[35,Intercept] r_pond[36,Intercept] r_pond[37,Intercept] r_pond[38,Intercept]
## 1.0001983 1.0004425 1.0000902 1.0000279
## r_pond[39,Intercept] r_pond[40,Intercept] r_pond[41,Intercept] r_pond[42,Intercept]
## 1.0001111 1.0000348 1.0002134 1.0004902
## r_pond[43,Intercept] r_pond[44,Intercept] r_pond[45,Intercept] r_pond[46,Intercept]
## 1.0006306 1.0004420 1.0000674 0.9999369
## r_pond[47,Intercept] r_pond[48,Intercept] r_pond[49,Intercept] r_pond[50,Intercept]
## 0.9999679 0.9999494 0.9998969 1.0000209
## r_pond[51,Intercept] r_pond[52,Intercept] r_pond[53,Intercept] r_pond[54,Intercept]
## 1.0002716 1.0004067 0.9999185 0.9998901
## r_pond[55,Intercept] r_pond[56,Intercept] r_pond[57,Intercept] r_pond[58,Intercept]
## 1.0003178 1.0002133 0.9999249 0.9999009
## r_pond[59,Intercept] r_pond[60,Intercept] lp__
## 1.0001104 1.0000400 1.0000022Extracting the ‘Eff.Sample’ values is a little more complicated. There is no effsamples() function. However, we do have neff_ratio().
neff_ratio(b12.3)## b_Intercept sd_pond__Intercept r_pond[1,Intercept] r_pond[2,Intercept]
## 0.3350679 0.3540338 1.2134717 1.6142412
## r_pond[3,Intercept] r_pond[4,Intercept] r_pond[5,Intercept] r_pond[6,Intercept]
## 1.8111203 1.5697587 1.3219172 1.6447324
## r_pond[7,Intercept] r_pond[8,Intercept] r_pond[9,Intercept] r_pond[10,Intercept]
## 1.6139521 1.9021429 1.4611080 1.7580230
## r_pond[11,Intercept] r_pond[12,Intercept] r_pond[13,Intercept] r_pond[14,Intercept]
## 1.9484691 1.8707600 1.7644988 2.0296344
## r_pond[15,Intercept] r_pond[16,Intercept] r_pond[17,Intercept] r_pond[18,Intercept]
## 1.8619893 1.3099899 1.3956490 1.6420323
## r_pond[19,Intercept] r_pond[20,Intercept] r_pond[21,Intercept] r_pond[22,Intercept]
## 1.7322525 1.6474163 1.7327984 1.3041271
## r_pond[23,Intercept] r_pond[24,Intercept] r_pond[25,Intercept] r_pond[26,Intercept]
## 1.4883350 1.5551357 1.3973067 1.5916201
## r_pond[27,Intercept] r_pond[28,Intercept] r_pond[29,Intercept] r_pond[30,Intercept]
## 1.6421408 1.7900393 1.7344241 1.7519775
## r_pond[31,Intercept] r_pond[32,Intercept] r_pond[33,Intercept] r_pond[34,Intercept]
## 1.4170788 1.4571529 0.9085235 0.9761805
## r_pond[35,Intercept] r_pond[36,Intercept] r_pond[37,Intercept] r_pond[38,Intercept]
## 1.0005429 1.0015009 1.1238062 0.9988977
## r_pond[39,Intercept] r_pond[40,Intercept] r_pond[41,Intercept] r_pond[42,Intercept]
## 1.3998742 1.0532292 1.1991255 0.9586475
## r_pond[43,Intercept] r_pond[44,Intercept] r_pond[45,Intercept] r_pond[46,Intercept]
## 1.0581333 1.0558455 0.9889237 1.2660532
## r_pond[47,Intercept] r_pond[48,Intercept] r_pond[49,Intercept] r_pond[50,Intercept]
## 0.8995469 1.3890079 1.3271646 0.9313268
## r_pond[51,Intercept] r_pond[52,Intercept] r_pond[53,Intercept] r_pond[54,Intercept]
## 0.9957368 0.9632408 1.1974916 1.1699048
## r_pond[55,Intercept] r_pond[56,Intercept] r_pond[57,Intercept] r_pond[58,Intercept]
## 0.7901757 1.0671998 1.1244886 0.8253512
## r_pond[59,Intercept] r_pond[60,Intercept] lp__
## 1.0000085 1.0162799 0.2343567The brms::neff_ratio() function returns ratios of the effective samples over the total number of post-warmup iterations. So if we know the neff_ratio() values and the number of post-warmup iterations, the ‘Eff.Sample’ values are just a little algebra away. A quick solution is to look at the ‘total post-warmup samples’ line at the top of our print() output. Another way is to extract that information from our brm() fit object. I’m not aware of a way to do that directly, but we can extract the iter value (i.e., b12.2$fit@sim$iter), the warmup value (i.e., b12.2$fit@sim$warmup), and the number of chains (i.e., b12.2$fit@sim$chains). With those values in hand, simple algebra will return the ‘total post-warmup samples’ value. E.g.,
(n_iter <- (b12.3$fit@sim$iter - b12.3$fit@sim$warmup) * b12.3$fit@sim$chains)## [1] 9000And now we have n_iter, we can calculate the ‘Eff.Sample’ values.
neff_ratio(b12.3) %>%
data.frame() %>%
rownames_to_column() %>%
set_names("parameter", "neff_ratio") %>%
mutate(eff_sample = (neff_ratio * n_iter) %>% round(digits = 0)) %>%
head()## parameter neff_ratio eff_sample
## 1 b_Intercept 0.3350679 3016
## 2 sd_pond__Intercept 0.3540338 3186
## 3 r_pond[1,Intercept] 1.2134717 10921
## 4 r_pond[2,Intercept] 1.6142412 14528
## 5 r_pond[3,Intercept] 1.8111203 16300
## 6 r_pond[4,Intercept] 1.5697587 14128Digressions aside, let’s get ready for the diagnostic plot of Figure 12.3.
dsim %>%
glimpse()## Observations: 60
## Variables: 5
## $ pond <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2…
## $ ni <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 10, 10, 10, 10, 10, 10, 10, 10, 10,…
## $ true_a <dbl> -0.82085139, 3.76575421, -0.03511672, 0.01999213, -1.59646315, 0.99155593, 0.926…
## $ si <int> 0, 5, 4, 3, 0, 5, 5, 3, 5, 5, 3, 3, 3, 4, 4, 6, 10, 9, 9, 9, 9, 10, 10, 6, 3, 8,…
## $ p_nopool <dbl> 0.00, 1.00, 0.80, 0.60, 0.00, 1.00, 1.00, 0.60, 1.00, 1.00, 0.60, 0.60, 0.60, 0.…# we could have included this step in the block of code below, if we wanted to
p_partpool <-
coef(b12.3)$pond[, , ] %>%
as_tibble() %>%
transmute(p_partpool = inv_logit_scaled(Estimate))
dsim <-
dsim %>%
bind_cols(p_partpool) %>%
mutate(p_true = inv_logit_scaled(true_a)) %>%
mutate(nopool_error = abs(p_nopool - p_true),
partpool_error = abs(p_partpool - p_true))
dsim %>%
glimpse()## Observations: 60
## Variables: 9
## $ pond <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,…
## $ ni <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 10, 10, 10, 10, 10, 10, 10, 1…
## $ true_a <dbl> -0.82085139, 3.76575421, -0.03511672, 0.01999213, -1.59646315, 0.99155593,…
## $ si <int> 0, 5, 4, 3, 0, 5, 5, 3, 5, 5, 3, 3, 3, 4, 4, 6, 10, 9, 9, 9, 9, 10, 10, 6,…
## $ p_nopool <dbl> 0.00, 1.00, 0.80, 0.60, 0.00, 1.00, 1.00, 0.60, 1.00, 1.00, 0.60, 0.60, 0.…
## $ p_partpool <dbl> 0.2534224, 0.9091564, 0.8106577, 0.6825460, 0.2580885, 0.9085185, 0.909099…
## $ p_true <dbl> 0.3055830, 0.9773737, 0.4912217, 0.5049979, 0.1684765, 0.7293951, 0.716461…
## $ nopool_error <dbl> 0.305582963, 0.022626343, 0.308778278, 0.095002134, 0.168476520, 0.2706048…
## $ partpool_error <dbl> 0.052160537, 0.068217208, 0.319435969, 0.177548141, 0.089612009, 0.1791233…Here is our code for Figure 12.3. The extra data processing for dfline is how we get the values necessary for the horizontal summary lines.
dfline <-
dsim %>%
select(ni, nopool_error:partpool_error) %>%
gather(key, value, -ni) %>%
group_by(key, ni) %>%
summarise(mean_error = mean(value)) %>%
mutate(x = c( 1, 16, 31, 46),
xend = c(15, 30, 45, 60))
dsim %>%
ggplot(aes(x = pond)) +
geom_vline(xintercept = c(15.5, 30.5, 45.4),
color = "white", size = 2/3) +
geom_point(aes(y = nopool_error), color = "orange2") +
geom_point(aes(y = partpool_error), shape = 1) +
geom_segment(data = dfline,
aes(x = x, xend = xend,
y = mean_error, yend = mean_error),
color = rep(c("orange2", "black"), each = 4),
linetype = rep(1:2, each = 4)) +
scale_x_continuous(breaks = c(1, 10, 20, 30, 40, 50, 60)) +
annotate("text", x = c(15 - 7.5, 30 - 7.5, 45 - 7.5, 60 - 7.5), y = .45,
label = c("tiny (5)", "small (10)", "medium (25)", "large (35)")) +
labs(y = "absolute error",
title = "Estimate error by model type",
subtitle = "The horizontal axis displays pond number. The vertical axis measures\nthe absolute error in the predicted proportion of survivors, compared to\nthe true value used in the simulation. The higher the point, the worse\nthe estimate. No-pooling shown in orange. Partial pooling shown in black.\nThe orange and dashed black lines show the average error for each kind\nof estimate, across each initial density of tadpoles (pond size). Smaller\nponds produce more error, but the partial pooling estimates are better\non average, especially in smaller ponds.") +
theme_fivethirtyeight() +
theme(panel.grid = element_blank(),
plot.subtitle = element_text(size = 10))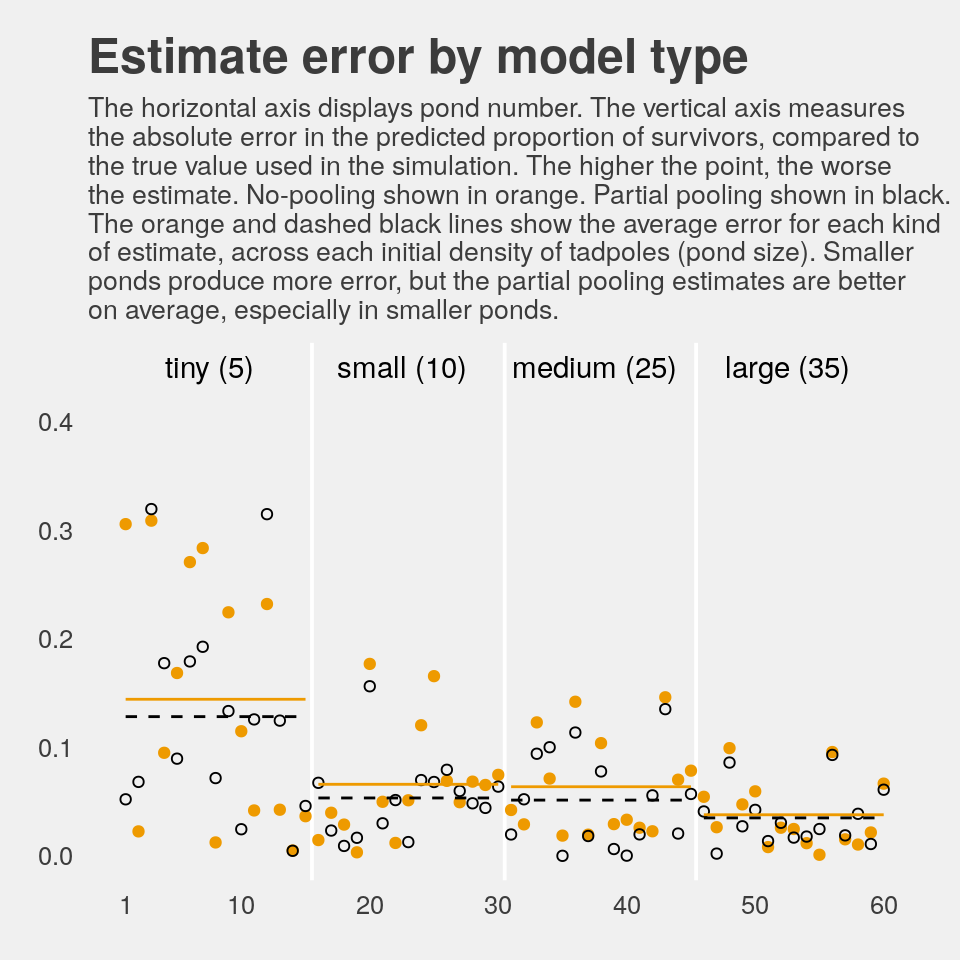
If you wanted to quantify the difference in simple summaries, you might do something like this:
dsim %>%
select(ni, nopool_error:partpool_error) %>%
gather(key, value, -ni) %>%
group_by(key) %>%
summarise(mean_error = mean(value) %>% round(digits = 3),
median_error = median(value) %>% round(digits = 3))## # A tibble: 2 x 3
## key mean_error median_error
## <chr> <dbl> <dbl>
## 1 nopool_error 0.078 0.05
## 2 partpool_error 0.067 0.052I originally learned about the multilevel in order to work with longitudinal data. In that context, I found the basic principles of a multilevel structure quite intuitive. The concept of partial pooling, however, took me some time to wrap my head around. If you’re struggling with this, be patient and keep chipping away.
When McElreath lectured on this topic in 2015, he traced partial pooling to statistician Charles M. Stein. In 1977, Efron and Morris wrote the now classic paper, Stein’s Paradox in Statistics, which does a nice job breaking down why partial pooling can be so powerful. One of the primary examples they used in the paper was of 1970 batting average data. If you’d like more practice seeing how partial pooling works–or if you just like baseball–, check out my blog post, Stein’s Paradox and What Partial Pooling Can Do For You.
12.2.5.1 Overthinking: Repeating the pond simulation.
Within the brms workflow, we can reuse a compiled model with update(). But first, we’ll simulate new data.
a <- 1.4
sigma <- 1.5
n_ponds <- 60
set.seed(1999) # for new data, set a new seed
new_dsim <-
tibble(pond = 1:n_ponds,
ni = rep(c(5, 10, 25, 35), each = n_ponds / 4) %>% as.integer(),
true_a = rnorm(n = n_ponds, mean = a, sd = sigma)) %>%
mutate(si = rbinom(n = n(), prob = inv_logit_scaled(true_a), size = ni)) %>%
mutate(p_nopool = si / ni)
glimpse(new_dsim)## Observations: 60
## Variables: 5
## $ pond <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2…
## $ ni <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 10, 10, 10, 10, 10, 10, 10, 10, 10,…
## $ true_a <dbl> 2.4990087, 1.3432554, 3.2045137, 3.6047030, 1.6005354, 2.1797409, 0.5759270, -0.…
## $ si <int> 4, 4, 5, 4, 4, 4, 2, 4, 3, 5, 4, 5, 2, 2, 5, 10, 7, 10, 10, 8, 10, 9, 5, 10, 10,…
## $ p_nopool <dbl> 0.80, 0.80, 1.00, 0.80, 0.80, 0.80, 0.40, 0.80, 0.60, 1.00, 0.80, 1.00, 0.40, 0.…Fit the new model.
b12.3_new <-
update(b12.3,
newdata = new_dsim,
iter = 10000, warmup = 1000, chains = 1, cores = 1)print(b12.3_new)## Family: binomial
## Links: mu = logit
## Formula: si | trials(ni) ~ 1 + (1 | pond)
## Data: new_dsim (Number of observations: 60)
## Samples: 1 chains, each with iter = 10000; warmup = 1000; thin = 1;
## total post-warmup samples = 9000
##
## Group-Level Effects:
## ~pond (Number of levels: 60)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 1.26 0.18 0.95 1.65 2944 1.00
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 1.52 0.20 1.14 1.91 3446 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Why not plot the first simulation versus the second one?
bind_rows(posterior_samples(b12.3),
posterior_samples(b12.3_new)) %>%
mutate(model = rep(c("b12.3", "b12.3_new"), each = n() / 2)) %>%
ggplot(aes(x = b_Intercept, y = sd_pond__Intercept)) +
stat_density_2d(geom = "raster",
aes(fill = stat(density)),
contour = F, n = 200) +
geom_vline(xintercept = a, color = "orange3", linetype = 3) +
geom_hline(yintercept = sigma, color = "orange3", linetype = 3) +
scale_fill_gradient(low = "grey25", high = "orange3") +
ggtitle("Our simulation posteriors contrast a bit",
subtitle = expression(paste(alpha, " is on the x and ", sigma, " is on the y, both in log-odds. The dotted lines intersect at the true values."))) +
coord_cartesian(xlim = c(.7, 2),
ylim = c(.8, 1.9)) +
theme_fivethirtyeight() +
theme(legend.position = "none",
panel.grid = element_blank()) +
facet_wrap(~model, ncol = 2)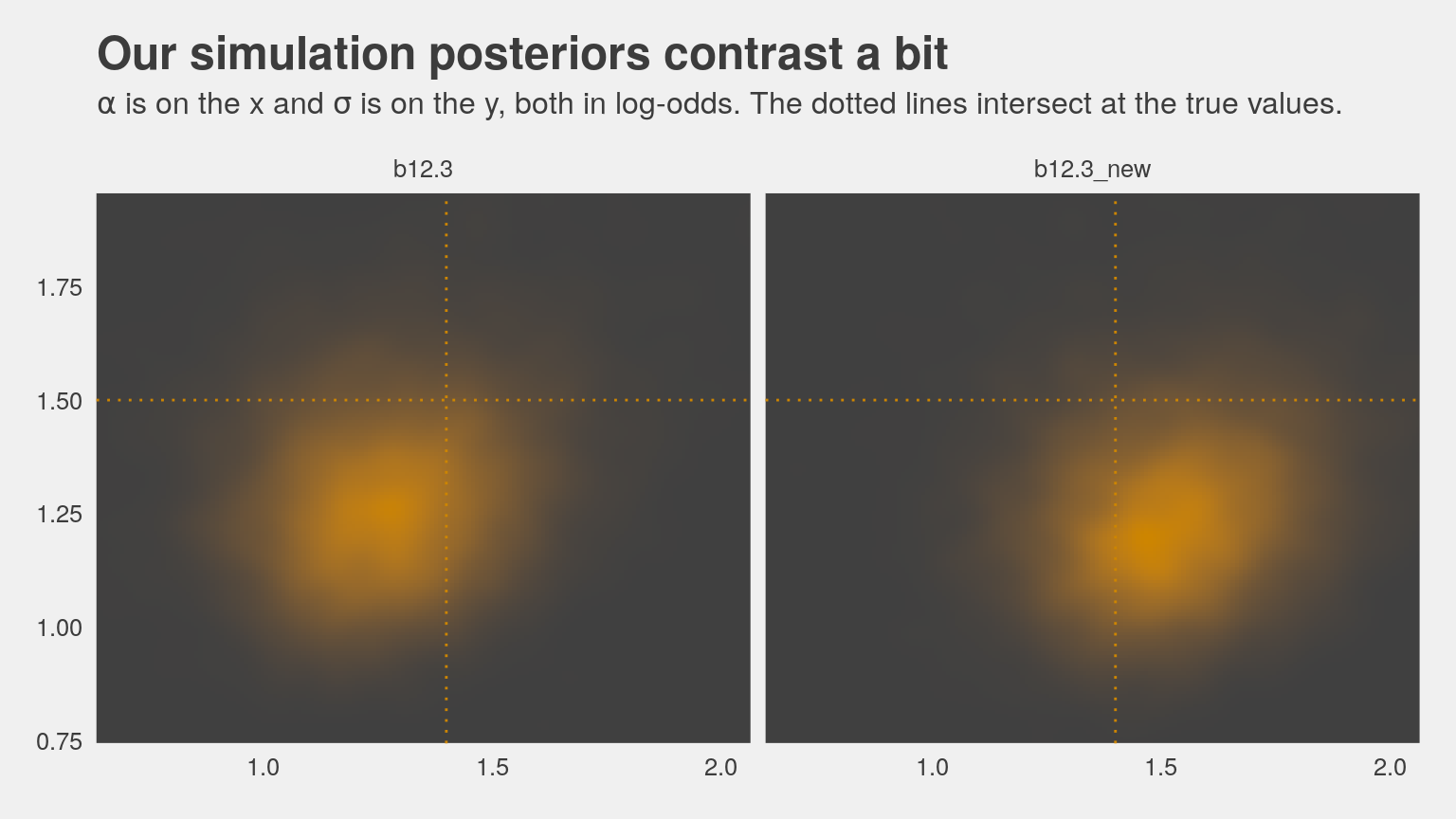
If you’d like the stanfit portion of your brm() object, subset with $fit. Take b12.3, for example. You might check out its structure via b12.3$fit %>% str(). Here’s the actual Stan code.
b12.3$fit@ stanmodel## S4 class stanmodel '124b09250c4c1f2a0b31156b2b547c4a' coded as follows:
## // generated with brms 2.9.0
## functions {
## }
## data {
## int<lower=1> N; // number of observations
## int Y[N]; // response variable
## int trials[N]; // number of trials
## // data for group-level effects of ID 1
## int<lower=1> N_1;
## int<lower=1> M_1;
## int<lower=1> J_1[N];
## vector[N] Z_1_1;
## int prior_only; // should the likelihood be ignored?
## }
## transformed data {
## }
## parameters {
## real temp_Intercept; // temporary intercept
## vector<lower=0>[M_1] sd_1; // group-level standard deviations
## vector[N_1] z_1[M_1]; // unscaled group-level effects
## }
## transformed parameters {
## // group-level effects
## vector[N_1] r_1_1 = (sd_1[1] * (z_1[1]));
## }
## model {
## vector[N] mu = temp_Intercept + rep_vector(0, N);
## for (n in 1:N) {
## mu[n] += r_1_1[J_1[n]] * Z_1_1[n];
## }
## // priors including all constants
## target += normal_lpdf(temp_Intercept | 0, 1);
## target += cauchy_lpdf(sd_1 | 0, 1)
## - 1 * cauchy_lccdf(0 | 0, 1);
## target += normal_lpdf(z_1[1] | 0, 1);
## // likelihood including all constants
## if (!prior_only) {
## target += binomial_logit_lpmf(Y | trials, mu);
## }
## }
## generated quantities {
## // actual population-level intercept
## real b_Intercept = temp_Intercept;
## }
## And you can get the data of a given brm() fit object like so.
b12.3$data %>%
head()## si ni pond
## 1 0 5 1
## 2 5 5 2
## 3 4 5 3
## 4 3 5 4
## 5 0 5 5
## 6 5 5 612.3 More than one type of cluster
“We can use and often should use more than one type of cluster in the same model” (p. 370).
12.3.1 Multilevel chimpanzees.
The initial multilevel update from model b10.4 from the last chapter follows the statistical formula
\[\begin{align*} \text{left_pull}_i & \sim \text{Binomial} (n_i = 1, p_i) \\ \text{logit} (p_i) & = \alpha + \alpha_{\text{actor}_i} + (\beta_1 + \beta_2 \text{condition}_i) \text{prosoc_left}_i \\ \alpha_{\text{actor}} & \sim \text{Normal} (0, \sigma_{\text{actor}}) \\ \alpha & \sim \text{Normal} (0, 10) \\ \beta_1 & \sim \text{Normal} (0, 10) \\ \beta_2 & \sim \text{Normal} (0, 10) \\ \sigma_{\text{actor}} & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
Notice that \(\alpha\) is inside the linear model, not inside the Gaussian prior for \(\alpha_\text{actor}\). This is mathematically equivalent to what [we] did with the tadpoles earlier in the chapter. You can always take the mean out of a Gaussian distribution and treat that distribution as a constant plus a Gaussian distribution centered on zero.
This might seem a little weird at first, so it might help train your intuition by experimenting in R. (p. 371)
Behold our two identical Gaussians in a tidy tibble.
set.seed(12)
two_gaussians <-
tibble(y1 = rnorm(n = 1e4, mean = 10, sd = 1),
y2 = 10 + rnorm(n = 1e4, mean = 0, sd = 1))Let’s follow McElreath’s advice to make sure they are same by superimposing the density of one on the other.
two_gaussians %>%
ggplot() +
geom_density(aes(x = y1),
size = 0, fill = "orange1", alpha = 1/3) +
geom_density(aes(x = y2),
size = 0, fill = "orange4", alpha = 1/3) +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "Our simulated Gaussians") +
theme_fivethirtyeight()
Yep, those Gaussians look about the same.
Let’s get the chimpanzees data from rethinking.
library(rethinking)
data(chimpanzees)
d <- chimpanzeesDetach rethinking and reload brms.
rm(chimpanzees)
detach(package:rethinking, unload = T)
library(brms)For our brms model with varying intercepts for actor but not block, we employ the pulled_left ~ 1 + ... + (1 | actor) syntax, specifically omitting a (1 | block) section.
b12.4 <-
brm(data = d, family = binomial,
pulled_left | trials(1) ~ 1 + prosoc_left + prosoc_left:condition + (1 | actor),
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = b),
prior(cauchy(0, 1), class = sd)),
# I'm using 4 cores, instead of the `cores=3` in McElreath's code
iter = 5000, warmup = 1000, chains = 4, cores = 4,
control = list(adapt_delta = 0.95),
seed = 12)The initial solutions came with a few divergent transitions. Increasing adapt_delta to 0.95 solved the problem. You can also solve the problem with more strongly regularizing priors such as normal(0, 2) on the intercept and slope parameters (see recommendations from the Stan team). Consider trying both methods and comparing the results. They’re similar.
Here we add the actor-level deviations to the fixed intercept, the grand mean.
post <- posterior_samples(b12.4)
post %>%
select(starts_with("r_actor")) %>%
gather() %>%
# this is how we might add the grand mean to the actor-level deviations
mutate(value = value + post$b_Intercept) %>%
group_by(key) %>%
summarise(mean = mean(value) %>% round(digits = 2))## # A tibble: 7 x 2
## key mean
## <chr> <dbl>
## 1 r_actor[1,Intercept] -0.71
## 2 r_actor[2,Intercept] 4.55
## 3 r_actor[3,Intercept] -1.02
## 4 r_actor[4,Intercept] -1.02
## 5 r_actor[5,Intercept] -0.71
## 6 r_actor[6,Intercept] 0.23
## 7 r_actor[7,Intercept] 1.77Here’s another way to get at the same information, this time using coef() and a little formatting help from the stringr::str_c() function. Just for kicks, we’ll throw in the 95% intervals, too.
coef(b12.4)$actor[, c(1, 3:4), 1] %>%
as_tibble() %>%
round(digits = 2) %>%
# here we put the credible intervals in an APA-6-style format
mutate(`95% CIs` = str_c("[", Q2.5, ", ", Q97.5, "]"),
actor = str_c("chimp #", 1:7)) %>%
rename(mean = Estimate) %>%
select(actor, mean, `95% CIs`) %>%
knitr::kable()| actor | mean | 95% CIs |
|---|---|---|
| chimp #1 | -0.71 | [-1.25, -0.19] |
| chimp #2 | 4.55 | [2.56, 8.29] |
| chimp #3 | -1.02 | [-1.59, -0.48] |
| chimp #4 | -1.02 | [-1.57, -0.48] |
| chimp #5 | -0.71 | [-1.24, -0.2] |
| chimp #6 | 0.23 | [-0.29, 0.76] |
| chimp #7 | 1.77 | [1.04, 2.59] |
If you prefer the posterior median to the mean, just add a robust = T argument inside the coef() function.
12.3.2 Two types of cluster.
The full statistical model follows the form
\[\begin{align*} \text{left_pull}_i & \sim \text{Binomial} (n_i = 1, p_i) \\ \text{logit} (p_i) & = \alpha + \alpha_{\text{actor}_i} + \alpha_{\text{block}_i} + (\beta_1 + \beta_2 \text{condition}_i) \text{prosoc_left}_i \\ \alpha_{\text{actor}} & \sim \text{Normal} (0, \sigma_{\text{actor}}) \\ \alpha_{\text{block}} & \sim \text{Normal} (0, \sigma_{\text{actor}}) \\ \alpha & \sim \text{Normal} (0, 10) \\ \beta_1 & \sim \text{Normal} (0, 10) \\ \beta_2 & \sim \text{Normal} (0, 10) \\ \sigma_{\text{actor}} & \sim \text{HalfCauchy} (0, 1) \\ \sigma_{\text{block}} & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
Our brms model with varying intercepts for both actor and block now employs the ... (1 | actor) + (1 | block) syntax.
b12.5 <-
update(b12.4,
newdata = d,
formula = pulled_left | trials(1) ~ 1 + prosoc_left + prosoc_left:condition +
(1 | actor) + (1 | block),
iter = 6000, warmup = 1000, cores = 4, chains = 4,
control = list(adapt_delta = 0.99),
seed = 12)This time we increased adapt_delta to 0.99 to avoid divergent transitions. We can look at the primary coefficients with print(). McElreath encouraged us to inspect the trace plots. Here they are.
library(bayesplot)
color_scheme_set("orange")
post <- posterior_samples(b12.5, add_chain = T)
post %>%
select(-lp__, -iter) %>%
mcmc_trace(facet_args = list(ncol = 4)) +
scale_x_continuous(breaks = c(0, 2500, 5000)) +
theme_fivethirtyeight() +
theme(legend.position = c(.75, .06))
The trace plots look great. We may as well examine the \(n_\text{eff} / N\) ratios, too.
neff_ratio(b12.5) %>%
mcmc_neff() +
theme_fivethirtyeight()
About half of them are lower than we might like, but none are in the embarrassing \(n_\text{eff} / N \leq .1\) range. Let’s look at the summary of the main parameters.
print(b12.5)## Family: binomial
## Links: mu = logit
## Formula: pulled_left | trials(1) ~ prosoc_left + (1 | actor) + (1 | block) + prosoc_left:condition
## Data: d (Number of observations: 504)
## Samples: 4 chains, each with iter = 6000; warmup = 1000; thin = 1;
## total post-warmup samples = 20000
##
## Group-Level Effects:
## ~actor (Number of levels: 7)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 2.29 0.95 1.13 4.67 5323 1.00
##
## ~block (Number of levels: 6)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 0.22 0.18 0.01 0.68 8197 1.00
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.46 0.97 -1.39 2.51 4400 1.00
## prosoc_left 0.83 0.26 0.31 1.35 16343 1.00
## prosoc_left:condition -0.14 0.30 -0.73 0.46 16404 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).This time, we’ll need to use brms::ranef() to get those depth=2-type estimates in the same metric displayed in the text. With ranef(), you get the group-specific estimates in a deviance metric. The coef() function, in contrast, yields the group-specific estimates in what you might call the natural metric. We’ll get more language for this in the next chapter.
ranef(b12.5)$actor[, , "Intercept"] %>%
round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## 1 -1.18 0.98 -3.27 0.68
## 2 4.18 1.68 1.79 8.24
## 3 -1.48 0.99 -3.57 0.35
## 4 -1.48 0.98 -3.58 0.38
## 5 -1.18 0.98 -3.27 0.68
## 6 -0.23 0.98 -2.29 1.62
## 7 1.32 1.00 -0.73 3.27ranef(b12.5)$block[, , "Intercept"] %>%
round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## 1 -0.18 0.23 -0.75 0.13
## 2 0.04 0.19 -0.33 0.46
## 3 0.06 0.19 -0.30 0.50
## 4 0.01 0.18 -0.38 0.40
## 5 -0.03 0.19 -0.46 0.33
## 6 0.11 0.20 -0.21 0.60We might make the coefficient plot of Figure 12.4.a like this:
stanplot(b12.5, pars = c("^r_", "^b_", "^sd_")) +
theme_fivethirtyeight() +
theme(axis.text.y = element_text(hjust = 0))
Once we get the posterior samples, it’s easy to compare the random variances as in Figure 12.4.b.
post %>%
ggplot(aes(x = sd_actor__Intercept)) +
geom_density(size = 0, fill = "orange1", alpha = 3/4) +
geom_density(aes(x = sd_block__Intercept),
size = 0, fill = "orange4", alpha = 3/4) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(0, 4)) +
labs(title = expression(sigma)) +
annotate("text", x = 2/3, y = 2, label = "block", color = "orange4") +
annotate("text", x = 2, y = 3/4, label = "actor", color = "orange1") +
theme_fivethirtyeight()
We might compare our models by their PSIS-LOO values.
b12.4 <- add_criterion(b12.4, "loo")
b12.5 <- add_criterion(b12.5, "loo")
loo_compare(b12.4, b12.5) %>%
print(simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## b12.4 0.0 0.0 -265.8 9.8 8.2 0.4 531.7 19.5
## b12.5 -0.4 0.9 -266.3 9.9 10.3 0.5 532.6 19.7The two models yield nearly-equivalent information criteria values. Yet recall what McElreath wrote: “There is nothing to gain here by selecting either model. The comparison of the two models tells a richer story” (p. 367).
12.4 Multilevel posterior predictions
… producing implied predictions from a fit model, is very helpful for understanding what the model means. Every model is a merger of sense and nonsense. When we understand a model, we can find its sense and control its nonsense. But as models get more complex, it is very difficult to impossible to understand them just by inspecting tables of posterior means and intervals. Exploring implied posterior predictions helps much more…
… The introduction of varying effects does introduce nuance, however.
First, we should no longer expect the model to exactly retrodict the sample, because adaptive regularization has as its goal to trade off poorer fit in sample for better inference and hopefully better fit out of sample. This is what shrinkage does for us…
Second, “prediction” in the context of a multilevel model requires additional choices. If we wish to validate a model against the specific clusters used to fit the model, that is one thing. But if we instead wish to compute predictions for new clusters, other than the one observed in the sample, that is quite another. We’ll consider each of these in turn, continuing to use the chimpanzees model from the previous section. (p. 376)
12.4.1 Posterior prediction for same clusters.
Like McElreath did in the text, we’ll do this two ways. Recall we use brms::fitted() in place of rethinking::link().
chimp <- 2
nd <-
tibble(prosoc_left = c(0, 1, 0, 1),
condition = c(0, 0, 1, 1),
actor = chimp)
(
chimp_2_fitted <-
fitted(b12.4,
newdata = nd) %>%
as_tibble() %>%
mutate(condition = factor(c("0/0", "1/0", "0/1", "1/1"),
levels = c("0/0", "1/0", "0/1", "1/1")))
)## # A tibble: 4 x 5
## Estimate Est.Error Q2.5 Q97.5 condition
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 0.980 0.0200 0.928 1.000 0/0
## 2 0.991 0.00981 0.965 1.000 1/0
## 3 0.980 0.0200 0.928 1.000 0/1
## 4 0.990 0.0109 0.961 1.000 1/1(
chimp_2_d <-
d %>%
filter(actor == chimp) %>%
group_by(prosoc_left, condition) %>%
summarise(prob = mean(pulled_left)) %>%
ungroup() %>%
mutate(condition = str_c(prosoc_left, "/", condition)) %>%
mutate(condition = factor(condition, levels = c("0/0", "1/0", "0/1", "1/1")))
)## # A tibble: 4 x 3
## prosoc_left condition prob
## <int> <fct> <dbl>
## 1 0 0/0 1
## 2 0 0/1 1
## 3 1 1/0 1
## 4 1 1/1 1McElreath didn’t show the corresponding plot in the text. It might look like this.
chimp_2_fitted %>%
# if you want to use `geom_line()` or `geom_ribbon()` with a factor on the x axis,
# you need to code something like `group = 1` in `aes()`
ggplot(aes(x = condition, y = Estimate, group = 1)) +
geom_ribbon(aes(ymin = Q2.5, ymax = Q97.5), fill = "orange1") +
geom_line(color = "blue") +
geom_point(data = chimp_2_d,
aes(y = prob),
color = "grey25") +
ggtitle("Chimp #2",
subtitle = "The posterior mean and 95%\nintervals are the blue line\nand orange band, respectively.\nThe empirical means are\nthe charcoal dots.") +
coord_cartesian(ylim = c(.75, 1)) +
theme_fivethirtyeight() +
theme(plot.subtitle = element_text(size = 10))
Do note how severely we’ve restricted the y-axis range. But okay, now let’s do things by hand. We’ll need to extract the posterior samples and look at the structure of the data.
post <- posterior_samples(b12.4)
glimpse(post)## Observations: 16,000
## Variables: 12
## $ b_Intercept <dbl> 0.46254505, 0.82205339, 0.62844196, 0.81494071, 0.44966323, 0.1…
## $ b_prosoc_left <dbl> 0.4974513, 0.5739029, 0.4698631, 0.8875959, 1.0904743, 0.553110…
## $ `b_prosoc_left:condition` <dbl> -0.01745575, 0.02418713, 0.28953029, -0.11792927, -0.16496230, …
## $ sd_actor__Intercept <dbl> 2.129032, 1.954739, 1.498115, 1.792798, 1.609654, 2.555877, 1.2…
## $ `r_actor[1,Intercept]` <dbl> -1.11765226, -1.37929461, -1.03594846, -1.33777820, -0.83068734…
## $ `r_actor[2,Intercept]` <dbl> 4.499278, 4.595988, 3.385730, 2.819580, 1.983078, 7.935862, 3.9…
## $ `r_actor[3,Intercept]` <dbl> -1.5550260, -1.5721361, -1.2130308, -1.8853882, -1.3194376, -1.…
## $ `r_actor[4,Intercept]` <dbl> -1.35703638, -1.70032471, -1.23101804, -1.79687510, -1.20526894…
## $ `r_actor[5,Intercept]` <dbl> -1.1350801, -1.1780740, -0.9810809, -1.3676574, -1.2667202, -0.…
## $ `r_actor[6,Intercept]` <dbl> -0.33454544, -0.65141018, -0.25114406, -0.26845627, -0.27853406…
## $ `r_actor[7,Intercept]` <dbl> 1.1285056, 0.8306487, 0.5047493, 2.4218469, 1.1319008, 2.002509…
## $ lp__ <dbl> -279.5003, -279.9949, -285.2442, -286.5966, -284.9667, -285.270…McElreath didn’t show what his R code 12.29 dens( post$a_actor[,5] ) would look like. But here’s our analogue.
post %>%
transmute(actor_5 = `r_actor[5,Intercept]`) %>%
ggplot(aes(x = actor_5)) +
geom_density(size = 0, fill = "blue") +
scale_y_continuous(breaks = NULL) +
ggtitle("Chimp #5's density") +
theme_fivethirtyeight()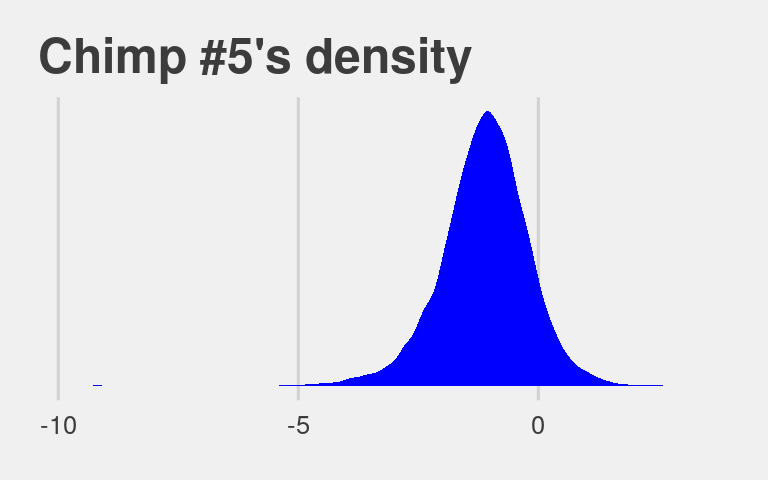
And because we made the density only using the r_actor[5,Intercept] values (i.e., we didn’t add b_Intercept to them), the density is in a deviance-score metric.
McElreath built his own link() function. Here we’ll build an alternative to fitted().
# our hand-made `brms::fitted()` alternative
my_fitted <- function(prosoc_left, condition){
post %>%
transmute(fitted = (b_Intercept +
`r_actor[5,Intercept]` +
b_prosoc_left * prosoc_left +
`b_prosoc_left:condition` * prosoc_left * condition) %>%
inv_logit_scaled())
}
# the posterior summaries
(
chimp_5_my_fitted <-
tibble(prosoc_left = c(0, 1, 0, 1),
condition = c(0, 0, 1, 1)) %>%
mutate(post = map2(prosoc_left, condition, my_fitted)) %>%
unnest() %>%
mutate(condition = str_c(prosoc_left, "/", condition)) %>%
mutate(condition = factor(condition, levels = c("0/0", "1/0", "0/1", "1/1"))) %>%
group_by(condition) %>%
tidybayes::mean_qi(fitted)
)## # A tibble: 4 x 7
## condition fitted .lower .upper .width .point .interval
## <fct> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 0/0 0.332 0.224 0.450 0.95 mean qi
## 2 1/0 0.528 0.385 0.670 0.95 mean qi
## 3 0/1 0.332 0.224 0.450 0.95 mean qi
## 4 1/1 0.495 0.351 0.638 0.95 mean qi# the empirical summaries
chimp <- 5
(
chimp_5_d <-
d %>%
filter(actor == chimp) %>%
group_by(prosoc_left, condition) %>%
summarise(prob = mean(pulled_left)) %>%
ungroup() %>%
mutate(condition = str_c(prosoc_left, "/", condition)) %>%
mutate(condition = factor(condition, levels = c("0/0", "1/0", "0/1", "1/1")))
)## # A tibble: 4 x 3
## prosoc_left condition prob
## <int> <fct> <dbl>
## 1 0 0/0 0.333
## 2 0 0/1 0.278
## 3 1 1/0 0.556
## 4 1 1/1 0.5Okay, let’s see how good we are at retrodicting the pulled_left probabilities for actor == 5.
chimp_5_my_fitted %>%
ggplot(aes(x = condition, y = fitted, group = 1)) +
geom_ribbon(aes(ymin = .lower, ymax = .upper), fill = "orange1") +
geom_line(color = "blue") +
geom_point(data = chimp_5_d,
aes(y = prob),
color = "grey25") +
ggtitle("Chimp #5",
subtitle = "This plot is like the last except\nwe did more by hand.") +
coord_cartesian(ylim = 0:1) +
theme_fivethirtyeight() +
theme(plot.subtitle = element_text(size = 10))
Not bad.
12.4.2 Posterior prediction for new clusters.
By average actor, McElreath referred to a chimp with an intercept exactly at the population mean \(\alpha\). So this time we’ll only be working with the population parameters, or what are also sometimes called the fixed effects. When using brms::posterior_samples() output, this would mean working with columns beginning with the b_ prefix (i.e., b_Intercept, b_prosoc_left, and b_prosoc_left:condition).
post_average_actor <-
post %>%
# here we use the linear regression formula to get the log_odds for the 4 conditions
transmute(`0/0` = b_Intercept,
`1/0` = b_Intercept + b_prosoc_left,
`0/1` = b_Intercept,
`1/1` = b_Intercept + b_prosoc_left + `b_prosoc_left:condition`) %>%
# with `mutate_all()` we can convert the estimates to probabilities in one fell swoop
mutate_all(inv_logit_scaled) %>%
# putting the data in the long format and grouping by condition (i.e., `key`)
gather() %>%
mutate(key = factor(key, level = c("0/0", "1/0", "0/1", "1/1"))) %>%
group_by(key) %>%
# here we get the summary values for the plot
summarise(m = mean(value),
# note we're using 80% intervals
ll = quantile(value, probs = .1),
ul = quantile(value, probs = .9))
post_average_actor## # A tibble: 4 x 4
## key m ll ul
## <fct> <dbl> <dbl> <dbl>
## 1 0/0 0.585 0.340 0.824
## 2 1/0 0.742 0.535 0.917
## 3 0/1 0.585 0.340 0.824
## 4 1/1 0.718 0.500 0.906Figure 12.5.a.
p1 <-
post_average_actor %>%
ggplot(aes(x = key, y = m, group = 1)) +
geom_ribbon(aes(ymin = ll, ymax = ul), fill = "orange1") +
geom_line(color = "blue") +
ggtitle("Average actor") +
coord_cartesian(ylim = 0:1) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 14, hjust = .5))
p1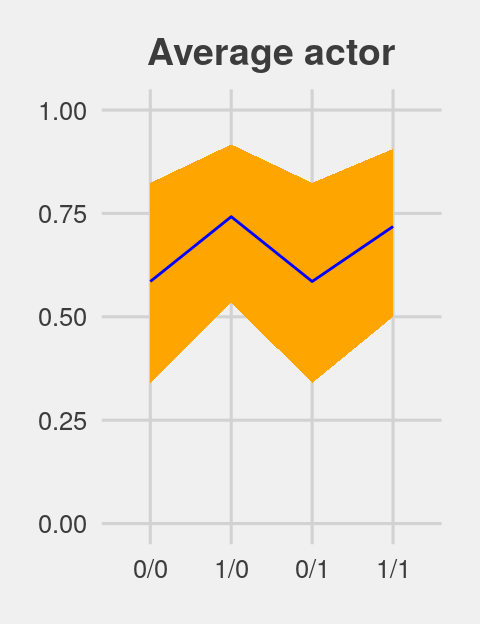
If we want to depict the variability across the chimps, we need to include sd_actor__Intercept into the calculations. In the first block of code, below, we simulate a bundle of new intercepts defined by
\[\alpha_\text{actor} \sim \text{Normal} (0, \sigma_\text{actor})\]
# the random effects
set.seed(12.42)
ran_ef <-
tibble(random_effect = rnorm(n = 1000, mean = 0, sd = post$sd_actor__Intercept)) %>%
# with the `., ., ., .` syntax, we quadruple the previous line
bind_rows(., ., ., .)
# the fixed effects (i.e., the population parameters)
fix_ef <-
post %>%
slice(1:1000) %>%
transmute(`0/0` = b_Intercept,
`1/0` = b_Intercept + b_prosoc_left,
`0/1` = b_Intercept,
`1/1` = b_Intercept + b_prosoc_left + `b_prosoc_left:condition`) %>%
gather() %>%
rename(condition = key,
fixed_effect = value) %>%
mutate(condition = factor(condition, level = c("0/0", "1/0", "0/1", "1/1")))
# combine them
ran_and_fix_ef <-
bind_cols(ran_ef, fix_ef) %>%
mutate(intercept = fixed_effect + random_effect) %>%
mutate(prob = inv_logit_scaled(intercept))
# to simplify things, we'll reduce them to summaries
(
marginal_effects <-
ran_and_fix_ef %>%
group_by(condition) %>%
summarise(m = mean(prob),
ll = quantile(prob, probs = .1),
ul = quantile(prob, probs = .9))
)## # A tibble: 4 x 4
## condition m ll ul
## <fct> <dbl> <dbl> <dbl>
## 1 0/0 0.560 0.0673 0.965
## 2 1/0 0.671 0.161 0.986
## 3 0/1 0.560 0.0673 0.965
## 4 1/1 0.652 0.140 0.983Behold Figure 12.5.b.
p2 <-
marginal_effects %>%
ggplot(aes(x = condition, y = m, group = 1)) +
geom_ribbon(aes(ymin = ll, ymax = ul), fill = "orange1") +
geom_line(color = "blue") +
ggtitle("Marginal of actor") +
coord_cartesian(ylim = 0:1) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 14, hjust = .5))
p2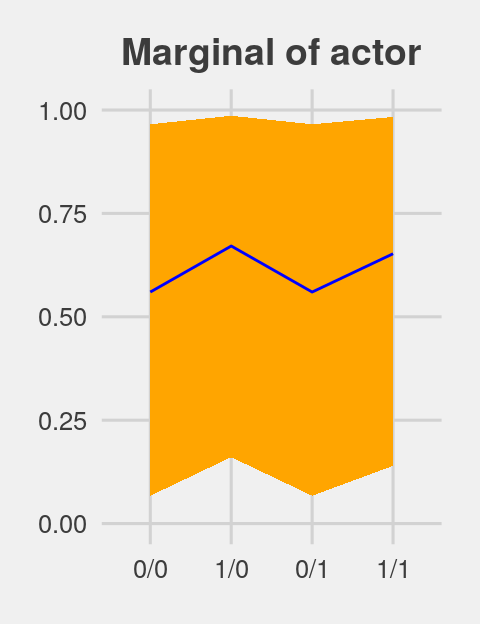
Figure 12.5.c just takes a tiny bit more wrangling.
p3 <-
ran_and_fix_ef %>%
mutate(iter = rep(1:1000, times = 4)) %>%
filter(iter %in% c(1:50)) %>%
ggplot(aes(x = condition, y = prob, group = iter)) +
theme_fivethirtyeight() +
ggtitle("50 simulated actors") +
coord_cartesian(ylim = 0:1) +
geom_line(alpha = 1/2, color = "orange3") +
theme(plot.title = element_text(size = 14, hjust = .5))
p3
For the finale, we’ll stitch the three plots together.
library(gridExtra)
grid.arrange(p1, p2, p3, ncol = 3)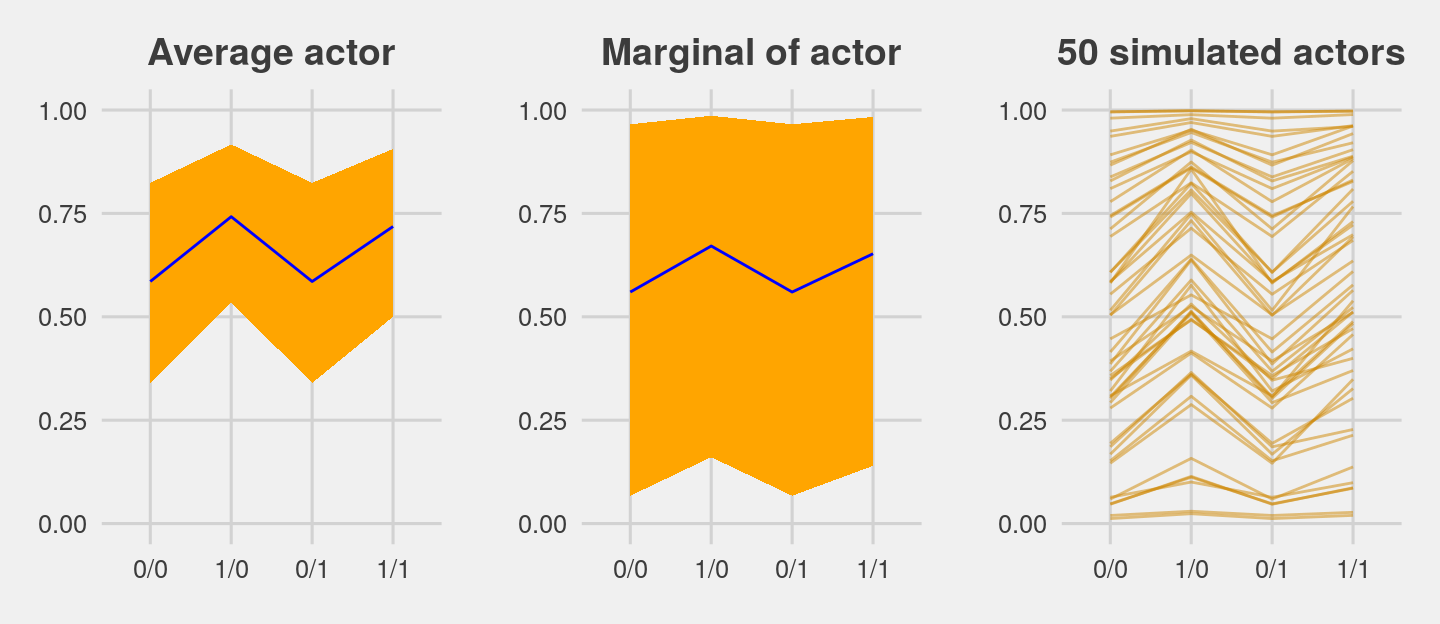
12.4.2.1 Bonus: Let’s use fitted() this time.
We just made those plots using various wrangled versions of post, the data frame returned by posterior_samples(b.12.4). If you followed along closely, part of what made that a great exercise is that it forced you to consider what the various vectors in post meant with respect to the model formula. But it’s also handy to see how to do that from a different perspective. So in this section, we’ll repeat that process by relying on the fitted() function, instead. We’ll go in the same order, starting with the average actor.
nd <-
tibble(prosoc_left = c(0, 1, 0, 1),
condition = c(0, 0, 1, 1))
(
f <-
fitted(b12.4,
newdata = nd,
re_formula = NA,
probs = c(.1, .9)) %>%
as_tibble() %>%
bind_cols(nd) %>%
mutate(condition = str_c(prosoc_left, "/", condition) %>%
factor(., levels = c("0/0", "1/0", "0/1", "1/1")))
)## # A tibble: 4 x 6
## Estimate Est.Error Q10 Q90 prosoc_left condition
## <dbl> <dbl> <dbl> <dbl> <dbl> <fct>
## 1 0.585 0.184 0.340 0.824 0 0/0
## 2 0.742 0.154 0.535 0.917 1 1/0
## 3 0.585 0.184 0.340 0.824 0 0/1
## 4 0.718 0.161 0.500 0.906 1 1/1You should notice a few things. Since b12.4 is a multilevel model, it had three predictors: prosoc_left, condition, and actor. However, our nd data only included the first two of those predictors. The reason fitted() permitted that was because we set re_formula = NA. When you do that, you tell fitted() to ignore group-level effects (i.e., focus only on the fixed effects). This was our fitted() version of ignoring the r_ vectors returned by posterior_samples(). Here’s the plot.
p4 <-
f %>%
ggplot(aes(x = condition, y = Estimate, group = 1)) +
geom_ribbon(aes(ymin = Q10, ymax = Q90), fill = "blue") +
geom_line(color = "orange1") +
ggtitle("Average actor") +
coord_cartesian(ylim = 0:1) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 14, hjust = .5))
p4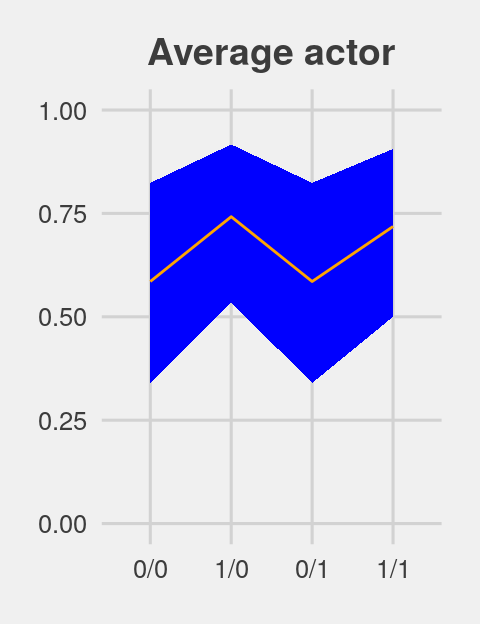
For marginal of actor, we can continue using the same nd data. This time we’ll be sticking with the default re_formula setting, which will accommodate the multilevel nature of the model. However, we’ll also be adding allow_new_levels = T and sample_new_levels = "gaussian". The former will allow us to marginalize across the specific actors in our data and the latter will instruct fitted() to use the multivariate normal distribution implied by the random effects. It’ll make more sense why I say multivariate normal by the end of the next chapter. For now, just go with it.
(
f <-
fitted(b12.4,
newdata = nd,
probs = c(.1, .9),
allow_new_levels = T,
sample_new_levels = "gaussian") %>%
as_tibble() %>%
bind_cols(nd) %>%
mutate(condition = str_c(prosoc_left, "/", condition) %>%
factor(., levels = c("0/0", "1/0", "0/1", "1/1")))
)## # A tibble: 4 x 6
## Estimate Est.Error Q10 Q90 prosoc_left condition
## <dbl> <dbl> <dbl> <dbl> <dbl> <fct>
## 1 0.557 0.328 0.0714 0.971 0 0/0
## 2 0.667 0.310 0.148 0.987 1 1/0
## 3 0.557 0.328 0.0714 0.971 0 0/1
## 4 0.649 0.314 0.133 0.985 1 1/1Here’s our fitted()-based marginal of actor plot.
p5 <-
f %>%
ggplot(aes(x = condition, y = Estimate, group = 1)) +
geom_ribbon(aes(ymin = Q10, ymax = Q90), fill = "blue") +
geom_line(color = "orange1") +
ggtitle("Marginal of actor") +
coord_cartesian(ylim = 0:1) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 14, hjust = .5))
p5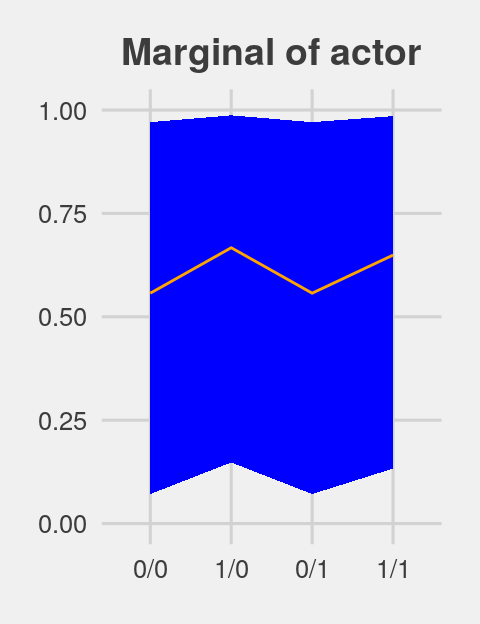
For the simulated actors plot, we’ll just amend our process from the last one. This time we’re setting summary = F, in order to keep the iteration-specific results, and setting nsamples = n_sim. n_sim is just a name for the number of actors we’d like to simulate (i.e., 50, as in the text).
# how many simulated actors would you like?
n_sim <- 50
(
f <-
fitted(b12.4,
newdata = nd,
probs = c(.1, .9),
allow_new_levels = T,
sample_new_levels = "gaussian",
summary = F,
nsamples = n_sim) %>%
as_tibble() %>%
mutate(iter = 1:n_sim) %>%
gather(key, value, -iter) %>%
bind_cols(nd %>%
transmute(condition = str_c(prosoc_left, "/", condition) %>%
factor(., levels = c("0/0", "1/0", "0/1", "1/1"))) %>%
expand(condition, iter = 1:n_sim))
)## # A tibble: 200 x 5
## iter key value condition iter1
## <int> <chr> <dbl> <fct> <int>
## 1 1 V1 0.255 0/0 1
## 2 2 V1 0.528 0/0 2
## 3 3 V1 0.597 0/0 3
## 4 4 V1 0.757 0/0 4
## 5 5 V1 0.962 0/0 5
## 6 6 V1 0.459 0/0 6
## 7 7 V1 0.157 0/0 7
## 8 8 V1 0.148 0/0 8
## 9 9 V1 0.741 0/0 9
## 10 10 V1 0.786 0/0 10
## # … with 190 more rowsp6 <-
f %>%
ggplot(aes(x = condition, y = value, group = iter)) +
geom_line(alpha = 1/2, color = "blue") +
ggtitle("50 simulated actors") +
coord_cartesian(ylim = 0:1) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 14, hjust = .5))
p6
Here they are altogether.
grid.arrange(p4, p5, p6, ncol = 3)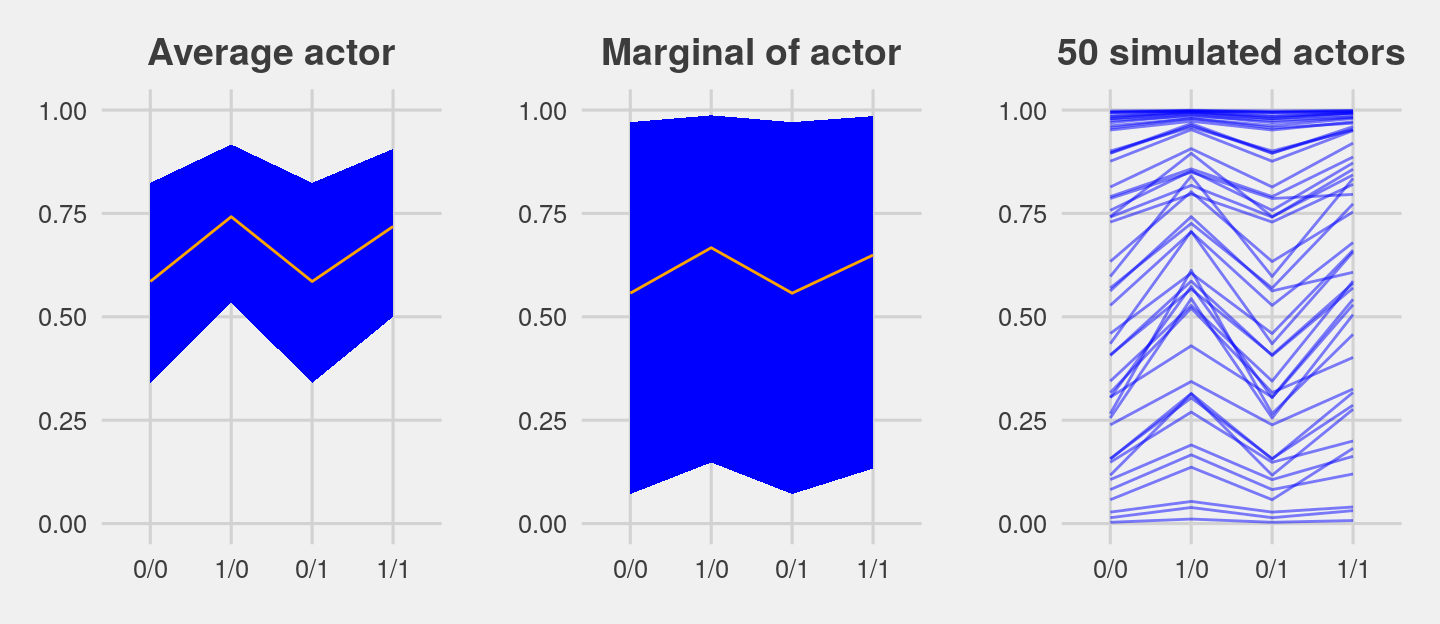
12.4.3 Focus and multilevel prediction.
First, let’s load the Kline data.
# prep data
library(rethinking)
data(Kline)
d <- KlineSwitch out the packages, once again.
detach(package:rethinking, unload = T)
library(brms)
rm(Kline)The statistical formula for our multilevel count model is
\[\begin{align*} \text{total_tools}_i & \sim \text{Poisson} (\mu_i) \\ \text{log} (\mu_i) & = \alpha + \alpha_{\text{culture}_i} + \beta \text{log} (\text{population}_i) \\ \alpha & \sim \text{Normal} (0, 10) \\ \beta & \sim \text{Normal} (0, 1) \\ \alpha_{\text{culture}} & \sim \text{Normal} (0, \sigma_{\text{culture}}) \\ \sigma_{\text{culture}} & \sim \text{HalfCauchy} (0, 1) \\ \end{align*}\]
With brms, we don’t actually need to make the logpop or society variables. We’re ready to fit the multilevel Kline model with the data in hand.
b12.6 <-
brm(data = d, family = poisson,
total_tools ~ 0 + intercept + log(population) +
(1 | culture),
prior = c(prior(normal(0, 10), class = b, coef = intercept),
prior(normal(0, 1), class = b),
prior(cauchy(0, 1), class = sd)),
iter = 4000, warmup = 1000, cores = 3, chains = 3,
seed = 12)Note how we used the special 0 + intercept syntax rather than using the default Intercept. This is because our predictor variable was not mean centered. For more info, see here. Though we used the 0 + intercept syntax for the fixed effect, it was not necessary for the random effect. Both ways work.
Here is the data-processing work for our variant of Figure 12.6.
nd <-
tibble(population = seq(from = 1000, to = 400000, by = 5000),
# to "simulate counterfactual societies, using the hyper-parameters" (p. 383),
# we'll plug a new island into the `culture` variable
culture = "my_island")
p <-
predict(b12.6,
# this allows us to simulate values for our counterfactual island, "my_island"
allow_new_levels = T,
# here we explicitly tell brms we want to include the group-level effects
re_formula = ~ (1 | culture),
# from the brms manual, this uses the "(multivariate) normal distribution implied by
# the group-level standard deviations and correlations", which appears to be
# what McElreath did in the text.
sample_new_levels = "gaussian",
newdata = nd,
probs = c(.015, .055, .165, .835, .945, .985)) %>%
as_tibble() %>%
bind_cols(nd)
p %>%
glimpse()## Observations: 80
## Variables: 10
## $ Estimate <dbl> 19.91589, 31.19600, 36.43122, 40.20144, 43.20922, 45.66733, 47.95200, 50.05578…
## $ Est.Error <dbl> 10.00401, 13.65630, 15.48353, 17.27621, 18.55424, 19.88237, 20.92730, 21.93365…
## $ Q1.5 <dbl> 5.000, 10.000, 13.000, 14.000, 15.000, 16.000, 16.000, 17.000, 18.000, 18.000,…
## $ Q5.5 <dbl> 8, 15, 18, 20, 21, 22, 23, 24, 25, 26, 26, 27, 28, 28, 29, 29, 29, 30, 30, 31,…
## $ Q16.5 <dbl> 12, 20, 24, 26, 28, 30, 31, 33, 34, 34, 35, 36, 37, 38, 38, 39, 40, 40, 41, 42…
## $ Q83.5 <dbl> 27.000, 41.000, 48.000, 53.000, 57.000, 60.000, 63.000, 66.000, 68.000, 70.000…
## $ Q94.5 <dbl> 36.000, 53.000, 61.000, 68.000, 72.000, 78.000, 80.000, 84.000, 88.000, 90.000…
## $ Q98.5 <dbl> 47.000, 69.000, 78.000, 88.000, 95.000, 100.000, 107.000, 112.000, 117.000, 12…
## $ population <dbl> 1000, 6000, 11000, 16000, 21000, 26000, 31000, 36000, 41000, 46000, 51000, 560…
## $ culture <chr> "my_island", "my_island", "my_island", "my_island", "my_island", "my_island", …For a detailed discussion on this way of using brms::predict(), see Andrew MacDonald’s great blogpost on this very figure. Here’s what we’ve been working for:
p %>%
ggplot(aes(x = log(population), y = Estimate)) +
geom_ribbon(aes(ymin = Q1.5, ymax = Q98.5), fill = "orange2", alpha = 1/3) +
geom_ribbon(aes(ymin = Q5.5, ymax = Q94.5), fill = "orange2", alpha = 1/3) +
geom_ribbon(aes(ymin = Q16.5, ymax = Q83.5), fill = "orange2", alpha = 1/3) +
geom_line(color = "orange4") +
geom_text(data = d, aes(y = total_tools, label = culture),
size = 2.33, color = "blue") +
ggtitle("Total tools as a function of log(population)") +
coord_cartesian(ylim = range(d$total_tools)) +
theme_fivethirtyeight() +
theme(plot.title = element_text(size = 12, hjust = .5))
Glorious.
The envelope of predictions is a lot wider here than it was back in Chapter 10. This is a consequene of the varying intercepts, combined with the fact that there is much more variation in the data than a pure-Poisson model anticipates. (p. 384)
12.5 Summary Bonus: tidybayes::spread_draws()
A big part of this chapter, both what McElreath focused on in the text and even our plotting digression a bit above, focused on how to combine the fixed effects of a multilevel with the group-level. Given some binomial variable, \(\text{criterion}\), and some group term, \(\text{grouping variable}\), we’ve learned the simple multilevel model follows a form like
\[\begin{align*} \text{criterion}_i & \sim \text{Binomial} (n_i \geq 1, p_i) \\ \text{logit} (p_i) & = \alpha + \alpha_{\text{grouping variable}_i}\\ \alpha & \sim \text{Normal} (0, 1) \\ \alpha_{\text{grouping variable}} & \sim \text{Normal} (0, \sigma_{\text{grouping variable}}) \\ \sigma_{\text{grouping variable}} & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
and we’ve been grappling with the relation between the grand mean \(\alpha\) and the group-level deviations \(\alpha_{\text{grouping variable}}\). For situations where we have the brms::brm() model fit in hand, we’ve been playing with various ways to use the iterations, particularly with either the posterior_samples() method and the fitted()/predict() method. Both are great. But (a) we have other options, which I’d like to share, and (b) if you’re like me, you probably need more practice than following along with the examples in the text. In this bonus section, we are going to introduce two simplified models and then practice working with combining the grand mean various combinations of the random effects.
For our first step, we’ll introduce the models.
12.5.1 Intercepts-only models with one or two grouping variables
If you recall, b12.4 was our first multilevel model with the chimps data. We can retrieve the model formula like so.
b12.4$formula## pulled_left | trials(1) ~ 1 + prosoc_left + prosoc_left:condition + (1 | actor)In addition to the model intercept and random effects for the individual chimps (i.e., actor), we also included fixed effects for the study conditions. For our bonus section, it’ll be easier if we reduce this to a simple intercepts-only model with the sole actor grouping factor. That model will follow the form
\[\begin{align*} \text{pulled_left}_i & \sim \text{Binomial} (n_i = 1, p_i) \\ \text{logit} (p_i) & = \alpha + \alpha_{\text{actor}_i}\\ \alpha & \sim \text{Normal} (0, 10) \\ \alpha_{\text{actor}} & \sim \text{Normal} (0, \sigma_{\text{actor}}) \\ \sigma_{\text{actor}} & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
Before we fit the model, you might recall that (a) we’ve already removed the chimpanzees data after saving the data as d and (b) we subsequently reassigned the Kline data to d. Instead of reloading the rethinking package to retrieve the chimpanzees data, we might also acknowledge that the data has also been saved within our b12.4 fit object. [It’s easy to forget such things.]
b12.4$data %>%
glimpse()## Observations: 504
## Variables: 4
## $ pulled_left <int> 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1,…
## $ prosoc_left <int> 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0,…
## $ condition <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ actor <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…So there’s no need to reload anything. Everything we need is already at hand. Let’s fit the intercepts-only model.
b12.7 <-
brm(data = b12.4$data, family = binomial,
pulled_left | trials(1) ~ 1 + (1 | actor),
prior = c(prior(normal(0, 10), class = Intercept),
prior(cauchy(0, 1), class = sd)),
iter = 5000, warmup = 1000, chains = 4, cores = 4,
control = list(adapt_delta = 0.95),
seed = 12)Here’s the model summary:
print(b12.7)## Family: binomial
## Links: mu = logit
## Formula: pulled_left | trials(1) ~ 1 + (1 | actor)
## Data: b12.4$data (Number of observations: 504)
## Samples: 4 chains, each with iter = 5000; warmup = 1000; thin = 1;
## total post-warmup samples = 16000
##
## Group-Level Effects:
## ~actor (Number of levels: 7)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 2.22 0.94 1.09 4.52 1101 1.00
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.84 1.02 -0.91 2.90 939 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Now recall that our competing cross-classified model, b12.5 added random effects for the trial blocks. Here was that formula.
b12.5$formula## pulled_left | trials(1) ~ prosoc_left + (1 | actor) + (1 | block) + prosoc_left:conditionAnd, of course, we can retrieve the data from that model, too.
b12.5$data %>%
glimpse()## Observations: 504
## Variables: 5
## $ pulled_left <int> 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1,…
## $ prosoc_left <int> 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0,…
## $ condition <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ actor <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ block <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 5, 5,…It’s the same data we used from the b12.4 model, but with the addition of the block index. With those data in hand, we can fit the intercepts-only version of our cross-classified model. This model formula follows the form
\[\begin{align*} \text{pulled_left}_i & \sim \text{Binomial} (n_i = 1, p_i) \\ \text{logit} (p_i) & = \alpha + \alpha_{\text{actor}_i} + \alpha_{\text{block}_i}\\ \alpha & \sim \text{Normal} (0, 10) \\ \alpha_{\text{actor}} & \sim \text{Normal} (0, \sigma_{\text{actor}}) \\ \alpha_{\text{block}} & \sim \text{Normal} (0, \sigma_{\text{block}}) \\ \sigma_{\text{actor}} & \sim \text{HalfCauchy} (0, 1) \\ \sigma_{\text{block}} & \sim \text{HalfCauchy} (0, 1) \end{align*}\]
Fit the model.
b12.8 <-
brm(data = b12.5$data, family = binomial,
pulled_left | trials(1) ~ 1 + (1 | actor) + (1 | block),
prior = c(prior(normal(0, 10), class = Intercept),
prior(cauchy(0, 1), class = sd)),
iter = 5000, warmup = 1000, chains = 4, cores = 4,
control = list(adapt_delta = 0.95),
seed = 12)Here’s the summary.
print(b12.8)## Family: binomial
## Links: mu = logit
## Formula: pulled_left | trials(1) ~ 1 + (1 | actor) + (1 | block)
## Data: b12.5$data (Number of observations: 504)
## Samples: 4 chains, each with iter = 5000; warmup = 1000; thin = 1;
## total post-warmup samples = 16000
##
## Group-Level Effects:
## ~actor (Number of levels: 7)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 2.22 0.89 1.10 4.46 4536 1.00
##
## ~block (Number of levels: 6)
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sd(Intercept) 0.23 0.18 0.01 0.69 6108 1.00
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.82 0.92 -0.92 2.77 3524 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Now we’ve fit our two intercepts-only models, let’s get to the heart of this section. We are going to practice four methods for working with the posterior samples. Each method will revolve around a different primary function. In order, they are
brms::posterior_samples()brms::coef()brms::fitted()tidybayes::spread_draws()
We’ve already had some practice with the first three, but I hope this section will make them even more clear. The tidybayes::spread_draws() method will be new, to us. I think you’ll find it’s a handy alternative.
With each of the four methods, we’ll practice three different model summaries.
- Getting the posterior draws for the
actor-level estimates from theb12.7model - Getting the posterior draws for the
actor-level estimates from the cross-classifiedb12.8model, averaging over the levels ofblock - Getting the posterior draws for the
actor-level estimates from the cross-classifiedb12.8model, based onblock == 1
So to be clear, our goal is to accomplish those three tasks with four methods, each of which should yield equivalent results.
12.5.2 brms::posterior_samples()
To warm up, let’s take a look at the structure of the posterior_samples() output for the simple b12.7 model.
posterior_samples(b12.7) %>% str()## 'data.frame': 16000 obs. of 10 variables:
## $ b_Intercept : num 0.929 0.388 0.195 0.223 -0.612 ...
## $ sd_actor__Intercept : num 3.3 2.41 2.3 2.72 2.93 ...
## $ r_actor[1,Intercept]: num -1.5618 -0.94732 -0.40974 -0.83024 0.00504 ...
## $ r_actor[2,Intercept]: num 3.61 4.72 7.62 8.63 3.18 ...
## $ r_actor[3,Intercept]: num -1.789 -0.91 -1.031 -0.587 0.142 ...
## $ r_actor[4,Intercept]: num -2.203 -1.251 -0.688 -1.074 -0.146 ...
## $ r_actor[5,Intercept]: num -1.384 -0.84 -0.511 -0.556 0.364 ...
## $ r_actor[6,Intercept]: num -0.0667 0.3732 0.0569 0.2945 1.1865 ...
## $ r_actor[7,Intercept]: num 1.54 1.78 1.52 2.17 2.97 ...
## $ lp__ : num -282 -279 -282 -282 -282 ...The b_Intercept vector corresponds to the \(\alpha\) term in the statistical model. The second vector, sd_actor__Intercept, corresponds to the \(\sigma_{\text{actor}}\) term. And the next 7 vectors beginning with the r_actor suffix are the \(\alpha_{\text{actor}}\) deviations from the grand mean, \(\alpha\). Thus if we wanted to get the model-implied probability for our first chimp, we’d add b_Intercept to r_actor[1,Intercept] and then take the inverse logit.
posterior_samples(b12.7) %>%
transmute(`chimp 1's average probability of pulling left` = (b_Intercept + `r_actor[1,Intercept]`) %>% inv_logit_scaled()) %>%
head()## chimp 1's average probability of pulling left
## 1 0.3469689
## 2 0.3636186
## 3 0.4466062
## 4 0.3527511
## 5 0.3527666
## 6 0.4897990To complete our first task, then, of getting the posterior draws for the actor-level estimates from the b12.7 model, we can do that in bulk.
p1 <-
posterior_samples(b12.7) %>%
transmute(`chimp 1's average probability of pulling left` = b_Intercept + `r_actor[1,Intercept]`,
`chimp 2's average probability of pulling left` = b_Intercept + `r_actor[2,Intercept]`,
`chimp 3's average probability of pulling left` = b_Intercept + `r_actor[3,Intercept]`,
`chimp 4's average probability of pulling left` = b_Intercept + `r_actor[4,Intercept]`,
`chimp 5's average probability of pulling left` = b_Intercept + `r_actor[5,Intercept]`,
`chimp 6's average probability of pulling left` = b_Intercept + `r_actor[6,Intercept]`,
`chimp 7's average probability of pulling left` = b_Intercept + `r_actor[7,Intercept]`) %>%
mutate_all(inv_logit_scaled)
str(p1)## 'data.frame': 16000 obs. of 7 variables:
## $ chimp 1's average probability of pulling left: num 0.347 0.364 0.447 0.353 0.353 ...
## $ chimp 2's average probability of pulling left: num 0.989 0.994 1 1 0.929 ...
## $ chimp 3's average probability of pulling left: num 0.297 0.372 0.302 0.41 0.385 ...
## $ chimp 4's average probability of pulling left: num 0.219 0.297 0.379 0.299 0.319 ...
## $ chimp 5's average probability of pulling left: num 0.388 0.389 0.422 0.418 0.438 ...
## $ chimp 6's average probability of pulling left: num 0.703 0.682 0.563 0.627 0.64 ...
## $ chimp 7's average probability of pulling left: num 0.922 0.897 0.847 0.916 0.913 ...One of the things I really like about this method is the b_Intercept + r_actor[i,Intercept] part of the code makes it very clear, to me, how the porterior_samples() columns correspond to the statistical model, \(\text{logit} (p_i) = \alpha + \alpha_{\text{actor}_i}\). This method easily extends to our next task, getting the posterior draws for the actor-level estimates from the cross-classified b12.8 model, averaging over the levels of block. In fact, other than switching out b12.7 for b12.8, the method is identical.
p2 <-
posterior_samples(b12.8) %>%
transmute(`chimp 1's average probability of pulling left` = b_Intercept + `r_actor[1,Intercept]`,
`chimp 2's average probability of pulling left` = b_Intercept + `r_actor[2,Intercept]`,
`chimp 3's average probability of pulling left` = b_Intercept + `r_actor[3,Intercept]`,
`chimp 4's average probability of pulling left` = b_Intercept + `r_actor[4,Intercept]`,
`chimp 5's average probability of pulling left` = b_Intercept + `r_actor[5,Intercept]`,
`chimp 6's average probability of pulling left` = b_Intercept + `r_actor[6,Intercept]`,
`chimp 7's average probability of pulling left` = b_Intercept + `r_actor[7,Intercept]`) %>%
mutate_all(inv_logit_scaled)
str(p2)## 'data.frame': 16000 obs. of 7 variables:
## $ chimp 1's average probability of pulling left: num 0.472 0.423 0.384 0.496 0.302 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.982 0.993 0.998 0.99 ...
## $ chimp 3's average probability of pulling left: num 0.328 0.347 0.32 0.409 0.317 ...
## $ chimp 4's average probability of pulling left: num 0.28 0.374 0.392 0.292 0.283 ...
## $ chimp 5's average probability of pulling left: num 0.395 0.385 0.467 0.376 0.375 ...
## $ chimp 6's average probability of pulling left: num 0.653 0.576 0.618 0.71 0.551 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.909 0.914 0.881 0.811 ...The reason we can still get away with this is because the grand mean in the b12.8 model is the grand mean across all levels of actor and block. AND it’s the case that the r_actor and r_block vectors returned by posterior_samples(b12.8) are all in deviation metrics–execute posterior_samples(b12.8) %>% glimpse() if it will help you follow along. So if we simply leave out the r_block vectors, we are ignoring the specific block-level deviations, effectively averaging over them.
Now for our third task, we’ve decided we wanted to retrieve the posterior draws for the actor-level estimates from the cross-classified b12.8 model, based on block == 1. To get the chimp-specific estimates for the first block, we simply add + r_block[1,Intercept] to the end of each formula.
p3 <-
posterior_samples(b12.8) %>%
transmute(`chimp 1's average probability of pulling left` = b_Intercept + `r_actor[1,Intercept]` + `r_block[1,Intercept]`,
`chimp 2's average probability of pulling left` = b_Intercept + `r_actor[2,Intercept]` + `r_block[1,Intercept]`,
`chimp 3's average probability of pulling left` = b_Intercept + `r_actor[3,Intercept]` + `r_block[1,Intercept]`,
`chimp 4's average probability of pulling left` = b_Intercept + `r_actor[4,Intercept]` + `r_block[1,Intercept]`,
`chimp 5's average probability of pulling left` = b_Intercept + `r_actor[5,Intercept]` + `r_block[1,Intercept]`,
`chimp 6's average probability of pulling left` = b_Intercept + `r_actor[6,Intercept]` + `r_block[1,Intercept]`,
`chimp 7's average probability of pulling left` = b_Intercept + `r_actor[7,Intercept]` + `r_block[1,Intercept]`) %>%
mutate_all(inv_logit_scaled)
str(p3)## 'data.frame': 16000 obs. of 7 variables:
## $ chimp 1's average probability of pulling left: num 0.475 0.336 0.334 0.471 0.316 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.974 0.991 0.998 0.991 ...
## $ chimp 3's average probability of pulling left: num 0.33 0.269 0.275 0.384 0.332 ...
## $ chimp 4's average probability of pulling left: num 0.283 0.292 0.342 0.272 0.297 ...
## $ chimp 5's average probability of pulling left: num 0.398 0.302 0.414 0.353 0.391 ...
## $ chimp 6's average probability of pulling left: num 0.655 0.484 0.566 0.689 0.568 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.873 0.896 0.87 0.821 ...Again, I like this method because of how close the wrangling code within transmute() is to the statistical model formula. I wrote a lot of code like this in my early days of working with these kinds of models, and I think the pedagogical insights were helpful. But this method has its limitations. It works fine if you’re working with some small number of groups. But that’s a lot of repetitious code and it would be utterly un-scalable to situations where you have 50 or 500 levels in your grouping variable. We need alternatives.
12.5.3 brms::coef()
First, let’s review what the coef() function returns.
coef(b12.7)## $actor
## , , Intercept
##
## Estimate Est.Error Q2.5 Q97.5
## 1 -0.3258351 0.2387985 -0.7945794 0.1419688
## 2 4.8723958 1.5689613 2.8545653 8.7823773
## 3 -0.6162426 0.2444905 -1.1020032 -0.1483985
## 4 -0.6155056 0.2452988 -1.1078114 -0.1410936
## 5 -0.3227853 0.2380135 -0.7963350 0.1406402
## 6 0.5786282 0.2442195 0.1109735 1.0688268
## 7 2.0770453 0.3702068 1.3956496 2.8488727By default, we get the familiar summaries for mean performances for each of our seven chimps. These, of course, are in the log-odds metric and simply tacking on inv_logit_scaled() isn’t going to fully get the job done. So to get things in the probability metric, we’ll want to first set summary = F in order to work directly with un-summarized samples and then wrangle quite a bit. Part of the wrangling challenge is because coef() returns a list, rather than a data frame. With that in mind, the code for our first task of getting the posterior draws for the actor-level estimates from the b12.7 model looks like so.
c1 <-
coef(b12.7, summary = F)$actor[, , ] %>%
as_tibble() %>%
gather() %>%
mutate(key = str_c("chimp ", key, "'s average probability of pulling left"),
value = inv_logit_scaled(value),
# we need an iteration index for `spread()` to work properly
iter = rep(1:16000, times = 7)) %>%
spread(key = key, value = value)
str(c1)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 8 variables:
## $ iter : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.347 0.364 0.447 0.353 0.353 ...
## $ chimp 2's average probability of pulling left: num 0.989 0.994 1 1 0.929 ...
## $ chimp 3's average probability of pulling left: num 0.297 0.372 0.302 0.41 0.385 ...
## $ chimp 4's average probability of pulling left: num 0.219 0.297 0.379 0.299 0.319 ...
## $ chimp 5's average probability of pulling left: num 0.388 0.389 0.422 0.418 0.438 ...
## $ chimp 6's average probability of pulling left: num 0.703 0.682 0.563 0.627 0.64 ...
## $ chimp 7's average probability of pulling left: num 0.922 0.897 0.847 0.916 0.913 ...So with this method, you get a little practice with three-dimensional indexing, which is a good skill to have. Now let’s extend it to our second task, getting the posterior draws for the actor-level estimates from the cross-classified b12.8 model, averaging over the levels of block.
c2 <-
coef(b12.8, summary = F)$actor[, , ] %>%
as_tibble() %>%
gather() %>%
mutate(key = str_c("chimp ", key, "'s average probability of pulling left"),
value = inv_logit_scaled(value),
iter = rep(1:16000, times = 7)) %>%
spread(key = key, value = value)
str(c2)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 8 variables:
## $ iter : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.472 0.423 0.384 0.496 0.302 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.982 0.993 0.998 0.99 ...
## $ chimp 3's average probability of pulling left: num 0.328 0.347 0.32 0.409 0.317 ...
## $ chimp 4's average probability of pulling left: num 0.28 0.374 0.392 0.292 0.283 ...
## $ chimp 5's average probability of pulling left: num 0.395 0.385 0.467 0.376 0.375 ...
## $ chimp 6's average probability of pulling left: num 0.653 0.576 0.618 0.71 0.551 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.909 0.914 0.881 0.811 ...As with our posterior_samples() method, this code was near identical to the block, above. All we did was switch out b12.7 for b12.8. [Okay, we removed a line of annotations. But that doesn’t really count.] We should point something out, though. Consider what coef() yields when working with a cross-classified model.
coef(b12.8)## $actor
## , , Intercept
##
## Estimate Est.Error Q2.5 Q97.5
## 1 -0.3247235 0.2688330 -0.85572928 0.19778169
## 2 4.9029215 1.5706782 2.85073026 8.80095264
## 3 -0.6207587 0.2775315 -1.17877374 -0.08300196
## 4 -0.6179356 0.2748473 -1.16001597 -0.08521013
## 5 -0.3262990 0.2666483 -0.84668181 0.19152270
## 6 0.5872925 0.2726632 0.06094433 1.12349276
## 7 2.0849640 0.3882744 1.35517600 2.88680438
##
##
## $block
## , , Intercept
##
## Estimate Est.Error Q2.5 Q97.5
## 1 0.6272241 0.9270623 -1.1364317 2.618713
## 2 0.8729194 0.9209817 -0.8599580 2.850919
## 3 0.8736776 0.9203855 -0.8524904 2.841719
## 4 0.8018632 0.9196948 -0.9287296 2.771870
## 5 0.8010938 0.9185675 -0.9314255 2.767559
## 6 0.9221205 0.9245301 -0.8199536 2.889170Now we have a list of two elements, one for actor and one for block. What might not be immediately obvious is that the summaries returned by one grouping level are based off of averaging over the other. Although this made our second task easy, it provides a challenge for our third task, getting the posterior draws for the actor-level estimates from the cross-classified b12.8 model, based on block == 1. To accomplish that, we’ll need to bring in ranef(). Let’s review what that returns.
ranef(b12.8)## $actor
## , , Intercept
##
## Estimate Est.Error Q2.5 Q97.5
## 1 -1.1415598 0.9328233 -3.0941856 0.6170603
## 2 4.0860852 1.6204352 1.7573932 7.9603480
## 3 -1.4375950 0.9314227 -3.4150644 0.3029414
## 4 -1.4347719 0.9327609 -3.4353776 0.2948453
## 5 -1.1431353 0.9282478 -3.1432070 0.6032561
## 6 -0.2295438 0.9312132 -2.2371739 1.5168560
## 7 1.2681277 0.9588380 -0.7373642 3.1367315
##
##
## $block
## , , Intercept
##
## Estimate Est.Error Q2.5 Q97.5
## 1 -0.18961221 0.2329755 -0.7601650 0.1140436
## 2 0.05608313 0.1880142 -0.3043344 0.4875170
## 3 0.05684135 0.1901712 -0.2931361 0.5001637
## 4 -0.01497311 0.1877653 -0.4178607 0.3738005
## 5 -0.01574246 0.1855662 -0.4171200 0.3665485
## 6 0.10528424 0.2021796 -0.2285119 0.5882794The format of the ranef() output is identical to that from coef(). However, the summaries are in the deviance metric. They’re all centered around zero, which corresponds to the part of the statistical model that specifies how \(\alpha_{\text{block}} \sim \text{Normal} (0, \sigma_{\text{block}})\). So then, if we want to continue using our coef() method, we’ll need to augment it with ranef() to accomplish our last task.
c3 <-
coef(b12.8, summary = F)$actor[, , ] %>%
as_tibble() %>%
gather() %>%
# here we add in the `block == 1` deviations from the grand mean
mutate(value = value + ranef(b12.8, summary = F)$block[, 1, ] %>% rep(., times = 7)) %>%
mutate(key = str_c("chimp ", key, "'s average probability of pulling left"),
value = inv_logit_scaled(value),
iter = rep(1:16000, times = 7)) %>%
spread(key = key, value = value)
str(c3)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 8 variables:
## $ iter : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.475 0.336 0.334 0.471 0.316 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.974 0.991 0.998 0.991 ...
## $ chimp 3's average probability of pulling left: num 0.33 0.269 0.275 0.384 0.332 ...
## $ chimp 4's average probability of pulling left: num 0.283 0.292 0.342 0.272 0.297 ...
## $ chimp 5's average probability of pulling left: num 0.398 0.302 0.414 0.353 0.391 ...
## $ chimp 6's average probability of pulling left: num 0.655 0.484 0.566 0.689 0.568 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.873 0.896 0.87 0.821 ...One of the nicest things about the coef() method is how is scales well. This code is no more burdensome for 5 group levels than it is for 5000. It’s also a post-processing version of the distinction McElreath made on page 372 between the two equivalent ways you might define a Gaussian:
\[\text{Normal}(10, 1)\] and
\[10 + \text{Normal}(0, 1)\]
Conversely, it can be a little abstract. Let’s keep expanding our options.
12.5.4 brms::fitted()
As is often the case, we’re going to want to define our predictor values for fitted().
(nd <- b12.7$data %>% distinct(actor))## actor
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7Now we have our new data, nd, here’s how we might use fitted() to accomplish our first task, getting the posterior draws for the actor-level estimates from the b12.7 model.
f1 <-
fitted(b12.7,
newdata = nd,
summary = F,
# within `fitted()`, this line does the same work that
# `inv_logit_scaled()` did with the other two methods
scale = "response") %>%
as_tibble() %>%
set_names(str_c("chimp ", 1:7, "'s average probability of pulling left"))
str(f1)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 7 variables:
## $ chimp 1's average probability of pulling left: num 0.347 0.364 0.447 0.353 0.353 ...
## $ chimp 2's average probability of pulling left: num 0.989 0.994 1 1 0.929 ...
## $ chimp 3's average probability of pulling left: num 0.297 0.372 0.302 0.41 0.385 ...
## $ chimp 4's average probability of pulling left: num 0.219 0.297 0.379 0.299 0.319 ...
## $ chimp 5's average probability of pulling left: num 0.388 0.389 0.422 0.418 0.438 ...
## $ chimp 6's average probability of pulling left: num 0.703 0.682 0.563 0.627 0.64 ...
## $ chimp 7's average probability of pulling left: num 0.922 0.897 0.847 0.916 0.913 ...This scales reasonably well. But might not work well if the vectors you wanted to rename didn’t follow a serial order, like ours. If you’re willing to pay with a few more lines of wrangling code, this method is more general, but still scalable.
f1 <-
fitted(b12.7,
newdata = nd,
summary = F,
scale = "response") %>%
as_tibble() %>%
# you'll need this line to make the `spread()` line work properly
mutate(iter = 1:n()) %>%
gather(key, value, -iter) %>%
mutate(key = str_replace(key, "V", "chimp ")) %>%
mutate(key = str_c(key, "'s average probability of pulling left")) %>%
spread(key = key, value = value)
str(f1)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 8 variables:
## $ iter : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.347 0.364 0.447 0.353 0.353 ...
## $ chimp 2's average probability of pulling left: num 0.989 0.994 1 1 0.929 ...
## $ chimp 3's average probability of pulling left: num 0.297 0.372 0.302 0.41 0.385 ...
## $ chimp 4's average probability of pulling left: num 0.219 0.297 0.379 0.299 0.319 ...
## $ chimp 5's average probability of pulling left: num 0.388 0.389 0.422 0.418 0.438 ...
## $ chimp 6's average probability of pulling left: num 0.703 0.682 0.563 0.627 0.64 ...
## $ chimp 7's average probability of pulling left: num 0.922 0.897 0.847 0.916 0.913 ...Now unlike with the previous two methods, our fitted() method will not allow us to simply switch out b12.7 for b12.8 to accomplish our second task of getting the posterior draws for the actor-level estimates from the cross-classified b12.8 model, averaging over the levels of block. This is because when we use fitted() in combination with its newdata argument, the function expects us to define values for all the predictor variables in the formula. Because the b12.8 model has both actor and block grouping variables as predictors, the default requires we include both in our new data. But if we were to specify a value for block in the nd data, we would no longer be averaging over the levels of block anymore; we’d be selecting one of the levels of block in particular, which we don’t yet want to do. Happily, brms::fitted() has a re_formula argument. If we would like to average out block, we simply drop it from the formula. Here’s how to do so.
f2 <-
fitted(b12.8,
newdata = nd,
# this line allows us to average over the levels of `block`
re_formula = pulled_left ~ 1 + (1 | actor),
summary = F,
scale = "response") %>%
as_tibble() %>%
set_names(str_c("chimp ", 1:7, "'s average probability of pulling left"))
str(f2)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 7 variables:
## $ chimp 1's average probability of pulling left: num 0.472 0.423 0.384 0.496 0.302 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.982 0.993 0.998 0.99 ...
## $ chimp 3's average probability of pulling left: num 0.328 0.347 0.32 0.409 0.317 ...
## $ chimp 4's average probability of pulling left: num 0.28 0.374 0.392 0.292 0.283 ...
## $ chimp 5's average probability of pulling left: num 0.395 0.385 0.467 0.376 0.375 ...
## $ chimp 6's average probability of pulling left: num 0.653 0.576 0.618 0.71 0.551 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.909 0.914 0.881 0.811 ...If we want to use fitted() for our third task of getting the posterior draws for the actor-level estimates from the cross-classified b12.8 model, based on block == 1, we’ll need to augment our nd data.
(
nd <-
b12.8$data %>%
distinct(actor) %>%
mutate(block = 1)
)## actor block
## 1 1 1
## 2 2 1
## 3 3 1
## 4 4 1
## 5 5 1
## 6 6 1
## 7 7 1This time, we no longer need that re_formula argument.
f3 <-
fitted(b12.8,
newdata = nd,
summary = F,
scale = "response") %>%
as_tibble() %>%
set_names(str_c("chimp ", 1:7, "'s average probability of pulling left"))
str(f3)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 7 variables:
## $ chimp 1's average probability of pulling left: num 0.475 0.336 0.334 0.471 0.316 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.974 0.991 0.998 0.991 ...
## $ chimp 3's average probability of pulling left: num 0.33 0.269 0.275 0.384 0.332 ...
## $ chimp 4's average probability of pulling left: num 0.283 0.292 0.342 0.272 0.297 ...
## $ chimp 5's average probability of pulling left: num 0.398 0.302 0.414 0.353 0.391 ...
## $ chimp 6's average probability of pulling left: num 0.655 0.484 0.566 0.689 0.568 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.873 0.896 0.87 0.821 ...Let’s learn one more option.
12.5.5 tidybayes::spread_draws()
Up till this point, we’ve really only used the tidybayes package for plotting (e.g., with geom_halfeyeh()) and summarizing (e.g., with median_qi()). But tidybayes is more general; it offers a handful of convenience functions for wrangling posterior draws from a tidyverse perspective. One such function is spread_draws(), which you can learn all about in Matthew Kay’s vignette Extracting and visualizing tidy draws from brms models. Let’s take a look at how we’ll be using it.
library(tidybayes)
b12.7 %>%
spread_draws(b_Intercept, r_actor[actor,])## # A tibble: 112,000 x 6
## # Groups: actor [7]
## .chain .iteration .draw b_Intercept actor r_actor
## <int> <int> <int> <dbl> <int> <dbl>
## 1 1 1 1 0.929 1 -1.56
## 2 1 1 1 0.929 2 3.61
## 3 1 1 1 0.929 3 -1.79
## 4 1 1 1 0.929 4 -2.20
## 5 1 1 1 0.929 5 -1.38
## 6 1 1 1 0.929 6 -0.0667
## 7 1 1 1 0.929 7 1.54
## 8 1 2 2 0.388 1 -0.947
## 9 1 2 2 0.388 2 4.72
## 10 1 2 2 0.388 3 -0.910
## # … with 111,990 more rowsFirst, notice tidybayes::spread_draws() took the model fit itself, b12.7, as input. No need for posterior_samples(). Now, notice we fed it two additional arguments. By the first argument, we that requested spead_draws() extract the posterior samples for the b_Intercept. By the second argument, r_actor[actor,], we instructed spead_draws() to extract all the random effects for the actor variable. Also notice how within the brackets [] we specified actor, which then became the name of the column in the output that indexed the levels of the grouping variable actor. By default, the code returns the posterior samples for all the levels of actor. However, had we only wanted those from chimps #1 and #3, we might use typical tidyverse-style indexing. E.g.,
b12.7 %>%
spread_draws(b_Intercept, r_actor[actor,]) %>%
filter(actor %in% c(1, 3))## # A tibble: 32,000 x 6
## # Groups: actor [2]
## .chain .iteration .draw b_Intercept actor r_actor
## <int> <int> <int> <dbl> <int> <dbl>
## 1 1 1 1 0.929 1 -1.56
## 2 1 1 1 0.929 3 -1.79
## 3 1 2 2 0.388 1 -0.947
## 4 1 2 2 0.388 3 -0.910
## 5 1 3 3 0.195 1 -0.410
## 6 1 3 3 0.195 3 -1.03
## 7 1 4 4 0.223 1 -0.830
## 8 1 4 4 0.223 3 -0.587
## 9 1 5 5 -0.612 1 0.00504
## 10 1 5 5 -0.612 3 0.142
## # … with 31,990 more rowsAlso notice those first three columns. By default, spread_draws() extracted information about which Markov chain a given draw was from, which iteration a given draw was within a given chain, and which draw from an overall standpoint. If it helps to keep track of which vector indexed what, consider this.
b12.7 %>%
spread_draws(b_Intercept, r_actor[actor,]) %>%
ungroup() %>%
select(.chain:.draw) %>%
gather() %>%
group_by(key) %>%
summarise(min = min(value),
max = max(value))## # A tibble: 3 x 3
## key min max
## <chr> <int> <int>
## 1 .chain 1 4
## 2 .draw 1 16000
## 3 .iteration 1 4000Above we simply summarized each of the three variables by their minimum and maximum values. If you recall that we fit b12.7 with four Markov chains, each with 4000 post-warmup iterations, hopefully it’ll make sense what each of those three variables index.
Now we’ve done a little clarification, let’s use spread_draws() to accomplish our first task, getting the posterior draws for the actor-level estimates from the b12.7 model.
s1 <-
b12.7 %>%
spread_draws(b_Intercept, r_actor[actor,]) %>%
mutate(p = (b_Intercept + r_actor) %>% inv_logit_scaled()) %>%
select(.draw, actor, p) %>%
ungroup() %>%
mutate(actor = str_c("chimp ", actor, "'s average probability of pulling left")) %>%
spread(value = p, key = actor)
str(s1)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 8 variables:
## $ .draw : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.347 0.364 0.447 0.353 0.353 ...
## $ chimp 2's average probability of pulling left: num 0.989 0.994 1 1 0.929 ...
## $ chimp 3's average probability of pulling left: num 0.297 0.372 0.302 0.41 0.385 ...
## $ chimp 4's average probability of pulling left: num 0.219 0.297 0.379 0.299 0.319 ...
## $ chimp 5's average probability of pulling left: num 0.388 0.389 0.422 0.418 0.438 ...
## $ chimp 6's average probability of pulling left: num 0.703 0.682 0.563 0.627 0.64 ...
## $ chimp 7's average probability of pulling left: num 0.922 0.897 0.847 0.916 0.913 ...The method remains essentially the same for accomplishing our second task, getting the posterior draws for the actor-level estimates from the cross-classified b12.8 model, averaging over the levels of block.
s2 <-
b12.8 %>%
spread_draws(b_Intercept, r_actor[actor,]) %>%
mutate(p = (b_Intercept + r_actor) %>% inv_logit_scaled()) %>%
select(.draw, actor, p) %>%
ungroup() %>%
mutate(actor = str_c("chimp ", actor, "'s average probability of pulling left")) %>%
spread(value = p, key = actor)
str(s2)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 8 variables:
## $ .draw : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.472 0.423 0.384 0.496 0.302 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.982 0.993 0.998 0.99 ...
## $ chimp 3's average probability of pulling left: num 0.328 0.347 0.32 0.409 0.317 ...
## $ chimp 4's average probability of pulling left: num 0.28 0.374 0.392 0.292 0.283 ...
## $ chimp 5's average probability of pulling left: num 0.395 0.385 0.467 0.376 0.375 ...
## $ chimp 6's average probability of pulling left: num 0.653 0.576 0.618 0.71 0.551 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.909 0.914 0.881 0.811 ...To accomplish our third task, we augment the spread_draws() and first mutate() lines, and add a filter() line between them.
s3 <-
b12.8 %>%
spread_draws(b_Intercept, r_actor[actor,], r_block[block,]) %>%
filter(block == 1) %>%
mutate(p = (b_Intercept + r_actor + r_block) %>% inv_logit_scaled()) %>%
select(.draw, actor, p) %>%
ungroup() %>%
mutate(actor = str_c("chimp ", actor, "'s average probability of pulling left")) %>%
spread(value = p, key = actor)## Adding missing grouping variables: `block`str(s3)## Classes 'tbl_df', 'tbl' and 'data.frame': 16000 obs. of 9 variables:
## $ block : int 1 1 1 1 1 1 1 1 1 1 ...
## $ .draw : int 1 2 3 4 5 6 7 8 9 10 ...
## $ chimp 1's average probability of pulling left: num 0.475 0.336 0.334 0.471 0.316 ...
## $ chimp 2's average probability of pulling left: num 0.993 0.974 0.991 0.998 0.991 ...
## $ chimp 3's average probability of pulling left: num 0.33 0.269 0.275 0.384 0.332 ...
## $ chimp 4's average probability of pulling left: num 0.283 0.292 0.342 0.272 0.297 ...
## $ chimp 5's average probability of pulling left: num 0.398 0.302 0.414 0.353 0.391 ...
## $ chimp 6's average probability of pulling left: num 0.655 0.484 0.566 0.689 0.568 ...
## $ chimp 7's average probability of pulling left: num 0.941 0.873 0.896 0.87 0.821 ...Hopefully working through these examples gave you some insight on the relation between fixed and random effects within multilevel models, and perhaps added to your posterior-iteration-wrangling toolkit.
Session info
sessionInfo()## R version 3.6.3 (2020-02-29)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Debian GNU/Linux 10 (buster)
##
## Matrix products: default
## BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/libopenblasp-r0.3.5.so
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=en_US.UTF-8
## [4] LC_COLLATE=en_US.UTF-8 LC_MONETARY=en_US.UTF-8 LC_MESSAGES=C
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] parallel stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidybayes_1.1.0 gridExtra_2.3 bayesplot_1.7.0 ggthemes_4.2.0 forcats_0.4.0
## [6] stringr_1.4.0 dplyr_0.8.1 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3
## [11] tibble_2.1.3 tidyverse_1.2.1 brms_2.9.0 Rcpp_1.0.1 dagitty_0.2-2
## [16] rstan_2.18.2 StanHeaders_2.18.1 ggplot2_3.1.1
##
## loaded via a namespace (and not attached):
## [1] colorspace_1.4-1 ggridges_0.5.1 rsconnect_0.8.13
## [4] ggstance_0.3.1 markdown_1.0 base64enc_0.1-3
## [7] rstudioapi_0.10 farver_2.0.3 svUnit_0.7-12
## [10] DT_0.7 fansi_0.4.0 mvtnorm_1.0-10
## [13] lubridate_1.7.4 xml2_1.2.0 codetools_0.2-16
## [16] bridgesampling_0.6-0 knitr_1.23 shinythemes_1.1.2
## [19] zeallot_0.1.0 jsonlite_1.6 broom_0.5.2
## [22] shiny_1.3.2 compiler_3.6.3 httr_1.4.0
## [25] backports_1.1.4 assertthat_0.2.1 Matrix_1.2-17
## [28] lazyeval_0.2.2 cli_1.1.0 later_0.8.0
## [31] htmltools_0.3.6 prettyunits_1.0.2 tools_3.6.3
## [34] igraph_1.2.4.1 coda_0.19-2 gtable_0.3.0
## [37] glue_1.3.1 reshape2_1.4.3 V8_2.2
## [40] cellranger_1.1.0 vctrs_0.1.0 nlme_3.1-144
## [43] crosstalk_1.0.0 xfun_0.7 ps_1.3.0
## [46] rvest_0.3.4 mime_0.7 miniUI_0.1.1.1
## [49] lifecycle_0.1.0 gtools_3.8.1 MASS_7.3-51.5
## [52] zoo_1.8-6 scales_1.1.1.9000 colourpicker_1.0
## [55] hms_0.4.2 promises_1.0.1 Brobdingnag_1.2-6
## [58] inline_0.3.15 shinystan_2.5.0 yaml_2.2.0
## [61] curl_3.3 loo_2.1.0 stringi_1.4.3
## [64] highr_0.8 dygraphs_1.1.1.6 boot_1.3-24
## [67] pkgbuild_1.0.3 shape_1.4.4 rlang_0.4.0
## [70] pkgconfig_2.0.2 matrixStats_0.54.0 evaluate_0.14
## [73] lattice_0.20-38 labeling_0.3 rstantools_1.5.1
## [76] htmlwidgets_1.3 processx_3.3.1 tidyselect_0.2.5
## [79] plyr_1.8.4 magrittr_1.5 bookdown_0.11
## [82] R6_2.4.0 generics_0.0.2 pillar_1.4.1
## [85] haven_2.1.0 withr_2.1.2 xts_0.11-2
## [88] abind_1.4-5 modelr_0.1.4 crayon_1.3.4
## [91] arrayhelpers_1.0-20160527 utf8_1.1.4 rmarkdown_1.13
## [94] grid_3.6.3 readxl_1.3.1 callr_3.2.0
## [97] threejs_0.3.1 digest_0.6.19 xtable_1.8-4
## [100] httpuv_1.5.1 stats4_3.6.3 munsell_0.5.0
## [103] shinyjs_1.0