5.8 Shapley Values
A prediction can be explained by assuming that each feature value of the instance is a “player” in a game where the prediction is the payout. The Shapley value – a method from coalitional game theory – tells us how to fairly distribute the “payout” among the features.
5.8.1 General Idea
Assume the following scenario:
You have trained a machine learning model to predict apartment prices. For a certain apartment it predicts €300,000 and you need to explain this prediction. The apartment has a size of 50 m2, is located on the 2nd floor, has a park nearby and cats are banned:
knitr::include_graphics("images/shapley-instance.png")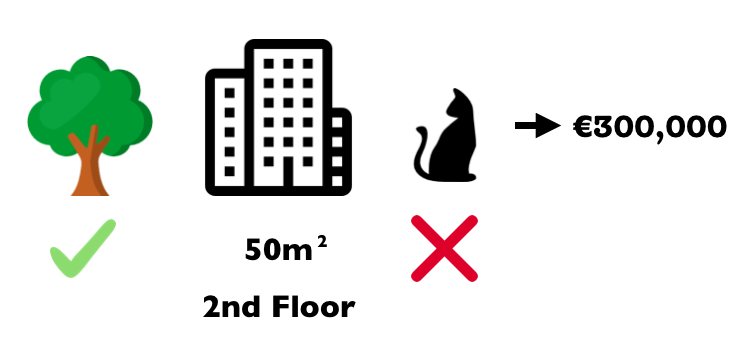
FIGURE 5.37: The predicted price for a 50 m2 2nd floor apartment with a nearby park and cat ban is €300,000. Our goal is to explain how each of these feature values contributed to the prediction.
The average prediction for all apartments is €310,000. How much has each feature value contributed to the prediction compared to the average prediction?
The answer is simple for linear regression models. The effect of each feature is the weight of the feature times the feature value. This only works because of the linearity of the model. For more complex models, we need a different solution. For example, LIME suggests local models to estimate effects. Another solution comes from cooperative game theory: The Shapley value, coined by Shapley (1953)39, is a method for assigning payouts to players depending on their contribution to the total payout. Players cooperate in a coalition and receive a certain profit from this cooperation.
Players?
Game?
Payout?
What is the connection to machine learning predictions and interpretability?
The “game” is the prediction task for a single instance of the dataset.
The “gain” is the actual prediction for this instance minus the average prediction for all instances.
The “players” are the feature values of the instance that collaborate to receive the gain (= predict a certain value).
In our apartment example, the feature values park-nearby, cat-banned, area-50 and floor-2nd worked together to achieve the prediction of €300,000.
Our goal is to explain the difference between the actual prediction (€300,000) and the average prediction (€310,000): a difference of -€10,000.
The answer could be:
The park-nearby contributed €30,000; size-50 contributed €10,000; floor-2nd contributed €0; cat-banned contributed -€50,000.
The contributions add up to -€10,000, the final prediction minus the average predicted apartment price.
How do we calculate the Shapley value for one feature?
The Shapley value is the average marginal contribution of a feature value across all possible coalitions. All clear now?
In the following figure we evaluate the contribution of the cat-banned feature value when it is added to a coalition of park-nearby and size-50.
We simulate that only park-nearby, cat-banned and size-50 are in a coalition by randomly drawing another apartment from the data and using its value for the floor feature.
The value floor-2nd was replaced by the randomly drawn floor-1st.
Then we predict the price of the apartment with this combination (€310,000).
In a second step, we remove cat-banned from the coalition by replacing it with a random value of the cat allowed/banned feature from the randomly drawn apartment.
In the example it was cat-allowed, but it could have been cat-banned again.
We predict the apartment price for the coalition of park-nearby and size-50 (€320,000).
The contribution of cat-banned was €310,000 - €320,000 = -€10.000.
This estimate depends on the values of the randomly drawn apartment that served as a “donor” for the cat and floor feature values.
We will get better estimates if we repeat this sampling step and average the contributions.
knitr::include_graphics("images/shapley-instance-intervention.png")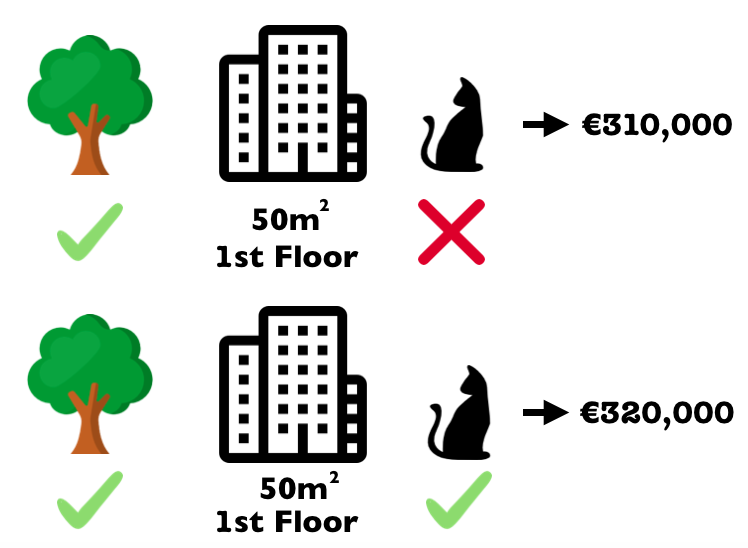
FIGURE 5.38: One sample repetition to estimate the contribution of cat-banned to the prediction when added to the coalition of park-nearby and area-50.
We repeat this computation for all possible coalitions. The Shapley value is the average of all the marginal contributions to all possible coalitions. The computation time increases exponentially with the number of features. One solution to keep the computation time manageable is to compute contributions for only a few samples of the possible coalitions.
The following figure shows all coalitions of feature values that are needed to determine the Shapley value for cat-banned.
The first row shows the coalition without any feature values.
The second, third and fourth rows show different coalitions with increasing coalition size, separated by “|”.
All in all, the following coalitions are possible:
No feature valuespark-nearbysize-50floor-2ndpark-nearby+size-50park-nearby+floor-2ndsize-50+floor-2ndpark-nearby+size-50+floor-2nd.
For each of these coalitions we compute the predicted apartment price with and without the feature value cat-banned and take the difference to get the marginal contribution.
The Shapley value is the (weighted) average of marginal contributions.
We replace the feature values of features that are not in a coalition with random feature values from the apartment dataset to get a prediction from the machine learning model.
knitr::include_graphics("images/shapley-coalitions.png")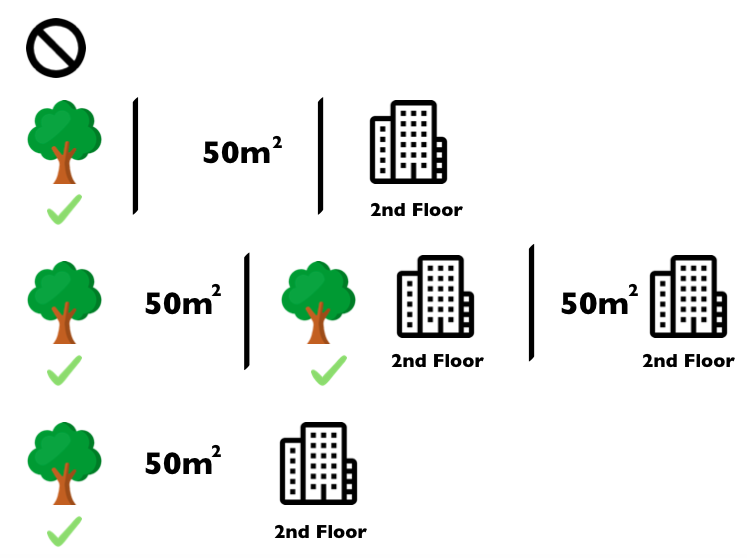
FIGURE 5.39: All 8 coalitions needed for computing the exact Shapley value of the cat-banned feature value.
If we estimate the Shapley values for all feature values, we get the complete distribution of the prediction (minus the average) among the feature values.
5.8.2 Examples and Interpretation
The interpretation of the Shapley value for feature value j is: The value of the j-th feature contributed \(\phi_j\) to the prediction of this particular instance compared to the average prediction for the dataset.
The Shapley value works for both classification (if we are dealing with probabilities) and regression.
We use the Shapley value to analyze the predictions of a random forest model predicting cervical cancer:
data("cervical")
library("caret")## Loading required package: lattice##
## Attaching package: 'caret'## The following object is masked from 'package:mlr':
##
## trainlibrary("iml")
ntree = 30
cervical.x = cervical[names(cervical) != 'Biopsy']
model <- caret::train(cervical.x,
cervical$Biopsy,
method = 'rf', ntree=ntree, maximise = FALSE)
predictor = Predictor$new(model, class = "Cancer", data = cervical.x, type = "prob")
instance_indices = 326
x.interest = cervical.x[instance_indices,]
avg.prediction = mean(predict(model, type = 'prob')[,'Cancer'])
actual.prediction = predict(model, newdata = x.interest, type = 'prob')['Cancer']
diff.prediction = actual.prediction - avg.predictionshapley2 = Shapley$new(predictor, x.interest = x.interest, sample.size = 100)
plot(shapley2) +
scale_y_continuous("Feature value contribution") +
ggtitle(sprintf("Actual prediction: %.2f\nAverage prediction: %.2f\nDifference: %.2f", actual.prediction, avg.prediction, diff.prediction)) +
scale_x_discrete("")
FIGURE 5.40: Shapley values for a woman in the cervical cancer dataset. With a prediction of 0.53, this woman’s cancer probability is 0.51 above the average prediction of 0.03. The number of diagnosed STDs increased the probability the most. The sum of contributions yields the difference between actual and average prediction (0.51).
For the bike rental dataset, we also train a random forest to predict the number of rented bikes for a day, given weather and calendar information. The explanations created for the random forest prediction of a particular day:
data("bike")
ntree = 30
bike.train.x = bike[names(bike) != 'cnt']
model <- caret::train(bike.train.x,
bike$cnt,
method = 'rf', ntree=ntree, maximise = FALSE)
predictor = Predictor$new(model, data = bike.train.x)
instance_indices = c(295, 285)
avg.prediction = mean(predict(model))
actual.prediction = predict(model, newdata = bike.train.x[instance_indices[2],])
diff.prediction = actual.prediction - avg.prediction
x.interest = bike.train.x[instance_indices[2],]shapley2 = Shapley$new(predictor, x.interest = x.interest)
plot(shapley2) + scale_y_continuous("Feature value contribution") +
ggtitle(sprintf("Actual prediction: %.0f\nAverage prediction: %.0f\nDifference: %.0f", actual.prediction, avg.prediction, diff.prediction)) +
scale_x_discrete("")
FIGURE 5.41: Shapley values for day 285. With a predicted 2475 rental bikes, this day is -2041 below the average prediction of 4516. The weather situation and humidity and had the largest negative contributions. The temperature on this day had a positive contribution. The sum of Shapley values yields the difference of actual and average prediction (-2041).
Be careful to interpret the Shapley value correctly: The Shapley value is the average contribution of a feature value to the prediction in different coalitions. The Shapley value is NOT the difference in prediction when we would remove the feature from the model.
5.8.3 The Shapley Value in Detail
This section goes deeper into the definition and computation of the Shapley value for the curious reader. Skip this section and go directly to “Advantages and Disadvantages” if you are not interested in the technical details.
We are interested in how each feature affects the prediction of a data point. In a linear model it is easy to calculate the individual effects. Here is what a linear model prediction looks like for one data instance:
\[\hat{f}(x)=\beta_0+\beta_{1}x_{1}+\ldots+\beta_{p}x_{p}\]
where x is the instance for which we want to compute the contributions. Each \(x_j\) is a feature value, with j = 1,…, p. The \(\beta_j\) is the weight corresponding to feature j.
The contribution \(\phi_j\) of the j-th feature on the prediction \(\hat{f}(x)\) is:
\[\phi_j(\hat{f})=\beta_{j}x_j-E(\beta_{j}X_{j})=\beta_{j}x_j-\beta_{j}E(X_{j})\]
where \(E(\beta_jX_{j})\) is the mean effect estimate for feature j. The contribution is the difference between the feature effect minus the average effect. Nice! Now we know how much each feature contributed to the prediction. If we sum all the feature contributions for one instance, the result is the following:
\[\begin{align*}\sum_{j=1}^{p}\phi_j(\hat{f})=&\sum_{j=1}^p(\beta_{j}x_j-E(\beta_{j}X_{j}))\\=&(\beta_0+\sum_{j=1}^p\beta_{j}x_j)-(\beta_0+\sum_{j=1}^{p}E(\beta_{j}X_{j}))\\=&\hat{f}(x)-E(\hat{f}(X))\end{align*}\]
This is the predicted value for the data point x minus the average predicted value. Feature contributions can be negative.
Can we do the same for any type of model? It would be great to have this as a model-agnostic tool. Since we usually do not have similar weights in other model types, we need a different solution.
Help comes from unexpected places: cooperative game theory. The Shapley value is a solution for computing feature contributions for single predictions for any machine learning model.
5.8.3.1 The Shapley Value
The Shapley value is defined via a value function val of players in S.
The Shapley value of a feature value is its contribution to the payout, weighted and summed over all possible feature value combinations:
\[\phi_j(val)=\sum_{S\subseteq\{x_{1},\ldots,x_{p}\}\setminus\{x_j\}}\frac{|S|!\left(p-|S|-1\right)!}{p!}\left(val\left(S\cup\{x_j\}\right)-val(S)\right)\]
where S is a subset of the features used in the model, x is the vector of feature values of the instance to be explained and p the number of features. \(val_x(S)\) is the prediction for feature values in set S that are marginalized over features that are not included in set S:
\[val_{x}(S)=\int\hat{f}(x_{1},\ldots,x_{p})d\mathbb{P}_{x\notin{}S}-E_X(\hat{f}(X))\]
You actually perform multiple integrations for each feature that is not contained S. A concrete example: The machine learning model works with 4 features x1, x2, x3 and x4 and we evaluate the prediction for the coalition S consisting of feature values x1 and x3:
\[val_{x}(S)=val_{x}(\{x_{1},x_{3}\})=\int_{\mathbb{R}}\int_{\mathbb{R}}\hat{f}(x_{1},X_{2},x_{3},X_{4})d\mathbb{P}_{X_2X_4}-E_X(\hat{f}(X))\]
This looks similar to the feature contributions in the linear model!
Do not get confused by the many uses of the word “value”: The feature value is the numerical or categorical value of a feature and instance; the Shapley value is the feature contribution to the prediction; the value function is the payout function for coalitions of players (feature values).
The Shapley value is the only attribution method that satisfies the properties Efficiency, Symmetry, Dummy and Additivity, which together can be considered a definition of a fair payout.
Efficiency
The feature contributions must add up to the difference of prediction for x and the average.
\[\sum\nolimits_{j=1}^p\phi_j=\hat{f}(x)-E_X(\hat{f}(X))\]
Symmetry
The contributions of two feature values j and k should be the same if they contribute equally to all possible coalitions.
If
\[val(S\cup\{x_j\})=val(S\cup\{x_k\})\]
for all
\[S\subseteq\{x_{1},\ldots,x_{p}\}\setminus\{x_j,x_k\}\]
then
\[\phi_j=\phi_{k}\]
Dummy
A feature j that does not change the predicted value – regardless of which coalition of feature values it is added to – should have a Shapley value of 0.
If
\[val(S\cup\{x_j\})=val(S)\]
for all
\[S\subseteq\{x_{1},\ldots,x_{p}\}\]
then
\[\phi_j=0\]
Additivity
For a game with combined payouts val+val+ the respective Shapley values are as follows:
\[\phi_j+\phi_j^{+}\]
Suppose you trained a random forest, which means that the prediction is an average of many decision trees. The Additivity property guarantees that for a feature value, you can calculate the Shapley value for each tree individually, average them, and get the Shapley value for the feature value for the random forest.
5.8.3.2 Intuition
An intuitive way to understand the Shapley value is the following illustration: The feature values enter a room in random order. All feature values in the room participate in the game (= contribute to the prediction). The Shapley value of a feature value is the average change in the prediction that the coalition already in the room receives when the feature value joins them.
5.8.3.3 Estimating the Shapley Value
All possible coalitions (sets) of feature values have to be evaluated with and without the j-th feature to calculate the exact Shapley value. For more than a few features, the exact solution to this problem becomes problematic as the number of possible coalitions exponentially increases as more features are added. Strumbelj et al. (2014)40 propose an approximation with Monte-Carlo sampling:
\[\hat{\phi}_{j}=\frac{1}{M}\sum_{m=1}^M\left(\hat{f}(x^{m}_{+j})-\hat{f}(x^{m}_{-j})\right)\]
where \(\hat{f}(x^{m}_{+j})\) is the prediction for x, but with a random number of feature values replaced by feature values from a random data point z, except for the respective value of feature j. The x-vector \(x^{m}_{-j}\) is almost identical to \(x^{m}_{+j}\), but the value \(x_j^{m}\) is also taken from the sampled x. Each of these M new instances is a kind of “Frankenstein Monster” assembled from two instances.
Approximate Shapley estimation for single feature value:
- Output: Shapley value for the value of the j-th feature
- Required: Number of iterations M, instance of interest x, feature index j, data matrix X, and machine learning model f
- For all m = 1,…,M:
- Draw random instance z from the data matrix X
- Choose a random permutation o of the feature values
- Order instance x: \(x_o=(x_{(1)},\ldots,x_{(j)},\ldots,x_{(p)})\)
- Order instance z: \(z_o=(z_{(1)},\ldots,z_{(j)},\ldots,z_{(p)})\)
- Construct two new instances
- With feature j: \(x_{+j}=(x_{(1)},\ldots,x_{(j-1)},x_{(j)},z_{(j+1)},\ldots,z_{(p)})\)
- Without feature j:\(x_{-j}=(x_{(1)},\ldots,x_{(j-1)},z_{(j)},z_{(j+1)},\ldots,z_{(p)})\)
- Compute marginal contribution: \(\phi_j^{m}=\hat{f}(x_{+j})-\hat{f}(x_{-j})\)
- For all m = 1,…,M:
- Compute Shapley value as the average: \(\phi_j(x)=\frac{1}{M}\sum_{m=1}^M\phi_j^{m}\)
First, select an instance of interest x, a feature j and the number of iterations M. For each iteration, a random instance z is selected from the data and a random order of the features is generated. Two new instances are created by combining values from the instance of interest x and the sample z. The first instance \(x_{+j}\) is the instance of interest, but all values in the order before and including value of feature j are replaced by feature values from the sample z. The second instance \(x_{-j}\) is similar, but has all the values in the order before, but excluding feature j replaced by values of feature j from the sample z. The difference in the prediction from the black box is computed:
\[\phi_j^{m}=\hat{f}(x^m_{+j})-\hat{f}(x^m_{-j})\]
All these differences are averaged and result in:
\[\phi_j(x)=\frac{1}{M}\sum_{m=1}^M\phi_j^{m}\]
Averaging implicitly weighs samples by the probability distribution of X.
The procedure has to be repeated for each of the features to get all Shapley values.
5.8.4 Advantages
The difference between the prediction and the average prediction is fairly distributed among the feature values of the instance – the Efficiency property of Shapley values. This property distinguishes the Shapley value from other methods such as LIME. LIME does not guarantee that the prediction is fairly distributed among the features. The Shapley value might be the only method to deliver a full explanation. In situations where the law requires explainability – like EU’s “right to explanations” – the Shapley value might be the only legally compliant method, because it is based on a solid theory and distributes the effects fairly. I am not a lawyer, so this reflects only my intuition about the requirements.
The Shapley value allows contrastive explanations. Instead of comparing a prediction to the average prediction of the entire dataset, you could compare it to a subset or even to a single data point. This contrastiveness is also something that local models like LIME do not have.
The Shapley value is the only explanation method with a solid theory. The axioms – efficiency, symmetry, dummy, additivity – give the explanation a reasonable foundation. Methods like LIME assume linear behavior of the machine learning model locally, but there is no theory as to why this should work.
It is mind-blowing to explain a prediction as a game played by the feature values.
5.8.5 Disadvantages
The Shapley value requires a lot of computing time. In 99.9% of real-world problems, only the approximate solution is feasible. An exact computation of the Shapley value is computationally expensive because there are 2k possible coalitions of the feature values and the “absence” of a feature has to be simulated by drawing random instances, which increases the variance for the estimate of the Shapley values estimation. The exponential number of the coalitions is dealt with by sampling coalitions and limiting the number of iterations M. Decreasing M reduces computation time, but increases the variance of the Shapley value. There is no good rule of thumb for the number of iterations M. M should be large enough to accurately estimate the Shapley values, but small enough to complete the computation in a reasonable time. It should be possible to choose M based on Chernoff bounds, but I have not seen any paper on doing this for Shapley values for machine learning predictions.
The Shapley value can be misinterpreted. The Shapley value of a feature value is not the difference of the predicted value after removing the feature from the model training. The interpretation of the Shapley value is: Given the current set of feature values, the contribution of a feature value to the difference between the actual prediction and the mean prediction is the estimated Shapley value.
The Shapley value is the wrong explanation method if you seek sparse explanations (explanations that contain few features). Explanations created with the Shapley value method always use all the features. Humans prefer selective explanations, such as those produced by LIME. LIME might be the better choice for explanations lay-persons have to deal with. Another solution is SHAP introduced by Lundberg and Lee (2016)41, which is based on the Shapley value, but can also provide explanations with few features.
The Shapley value returns a simple value per feature, but no prediction model like LIME. This means it cannot be used to make statements about changes in prediction for changes in the input, such as: “If I were to earn €300 more a year, my credit score would increase by 5 points.”
Another disadvantage is that you need access to the data if you want to calculate the Shapley value for a new data instance. It is not sufficient to access the prediction function because you need the data to replace parts of the instance of interest with values from randomly drawn instances of the data. This can only be avoided if you can create data instances that look like real data instances but are not actual instances from the training data.
Like many other permutation-based interpretation methods, the Shapley value method suffers from inclusion of unrealistic data instances when features are correlated. To simulate that a feature value is missing from a coalition, we marginalize the feature. This is achieved by sampling values from the feature’s marginal distribution. This is fine as long as the features are independent. When features are dependent, then we might sample feature values that do not make sense for this instance. But we would use those to compute the feature’s Shapley value. To the best of my knowledge, there is no research on what that means for the Shapley values, nor a suggestion on how to fix it. One solution might be to permute correlated features together and get one mutual Shapley value for them. Or the sampling procedure might have to be adjusted to account for dependence of features.
5.8.6 Software and Alternatives
Shapley values are implemented in the iml R package.
SHAP, an alternative formulation of the Shapley values, is implemented in the Python package shap.
SHAP turns the Shapley values method into an optimization problem and uses a special kernel function to measure proximity of data instances.
The results of SHAP are sparse (many Shapley values are estimated to be zero), which is the biggest difference from the classic Shapley values.
Another approach is called breakDown, which is implemented in the breakDown R package42.
BreakDown also shows the contributions of each feature to the prediction, but computes them step by step.
Let us reuse the game analogy:
We start with an empty team, add the feature value that would contribute the most to the prediction and iterate until all feature values are added.
How much each feature value contributes depends on the respective feature values that are already in the “team”, which is the big drawback of the breakDown method.
It is faster than the Shapley value method, and for models without interactions, the results are the same.
Shapley, Lloyd S. “A value for n-person games.” Contributions to the Theory of Games 2.28 (1953): 307-317.↩
Štrumbelj, Erik, and Igor Kononenko. “Explaining prediction models and individual predictions with feature contributions.” Knowledge and information systems 41.3 (2014): 647-665.↩
Lundberg, Scott, and Su-In Lee. “An unexpected unity among methods for interpreting model predictions.” arXiv preprint arXiv:1611.07478 (2016).↩
Staniak, Mateusz, and Przemyslaw Biecek. “Explanations of model predictions with live and breakDown packages.” arXiv preprint arXiv:1804.01955 (2018).↩